This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. Open Table Format (OTF) architecture now provides a solution for efficient data storage, management, and processing while ensuring compatibility across different platforms.
More than 50% of data leaders recently surveyed by BCG said the complexity of their dataarchitecture is a significant pain point in their enterprise. As a result,” says BCG, “many companies find themselves at a tipping point, at risk of drowning in a deluge of data, overburdened with complexity and costs.”
A dataingestionarchitecture is the technical blueprint that ensures that every pulse of your organization’s data ecosystem brings critical information to where it’s needed most. Data Transformation : Clean, format, and convert extracted data to ensure consistency and usability for both batch and real-time processing.
By Anupom Syam Background At Netflix, our current datawarehouse contains hundreds of Petabytes of data stored in AWS S3 , and each day we ingest and create additional Petabytes. Some of the optimizations are prerequisites for a high-performance datawarehouse.
When you deconstruct the core database architecture, deep in the heart of it you will find a single component that is performing two distinct competing functions: real-time dataingestion and query serving. When dataingestion has a flash flood moment, your queries will slow down or time out making your application flaky.
The promise of a modern data lakehouse architecture. Imagine having self-service access to all business data, anywhere it may be, and being able to explore it all at once. Imagine quickly answering burning business questions nearly instantly, without waiting for data to be found, shared, and ingested.
Today’s customers have a growing need for a faster end to end dataingestion to meet the expected speed of insights and overall business demand. This ‘need for speed’ drives a rethink on building a more modern datawarehouse solution, one that balances speed with platform cost management, performance, and reliability.
In this post, we will be particularly interested in the impact that cloud computing left on the modern datawarehouse. We will explore the different options for data warehousing and how you can leverage this information to make the right decisions for your organization. Understanding the Basics What is a DataWarehouse?
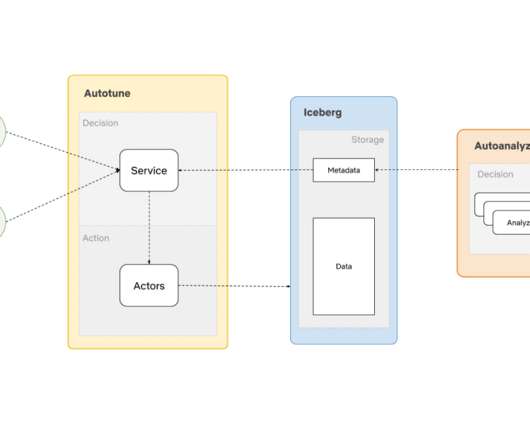
While the Iceberg itself simplifies some aspects of data management, the surrounding ecosystem introduces new challenges: Small File Problem (Revisited): Like Hadoop, Iceberg can suffer from small file problems. Dataingestion tools often create numerous small files, which can degrade performance during query execution.
Many of our customers — from Marriott to AT&T — start their journey with the Snowflake AI Data Cloud by migrating their data warehousing workloads to the platform. Today we’re focusing on customers who migrated from a legacy datawarehouse to Snowflake and some of the benefits they saw.
Dataingestion is the process of collecting data from various sources and moving it to your datawarehouse or lake for processing and analysis. It is the first step in modern data management workflows. Table of Contents What is DataIngestion? Decision making would be slower and less accurate.
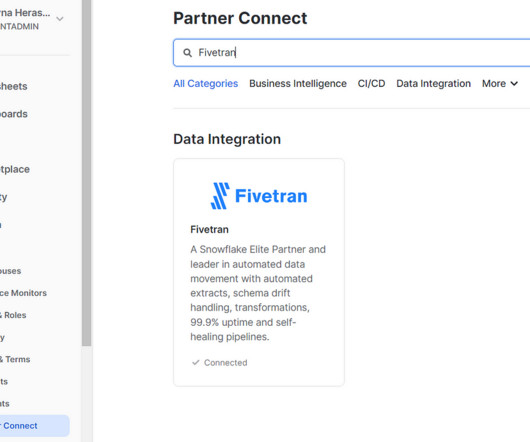
At the heart of every data-driven decision is a deceptively simple question: How do you get the right data to the right place at the right time? The growing field of dataingestion tools offers a range of answers, each with implications to ponder. Fivetran Image courtesy of Fivetran.
Data pipelines are the backbone of your business’s dataarchitecture. Implementing a robust and scalable pipeline ensures you can effectively manage, analyze, and organize your growing data. Benjamin Kennedy, Cloud Solutions Architect at Striim, emphasizes the outcome-driven nature of data pipelines.
Two popular approaches that have emerged in recent years are datawarehouse and big data. While both deal with large datasets, but when it comes to datawarehouse vs big data, they have different focuses and offer distinct advantages.
Data volume and velocity, governance, structure, and regulatory requirements have all evolved and continue to. Despite these limitations, datawarehouses, introduced in the late 1980s based on ideas developed even earlier, remain in widespread use today for certain business intelligence and data analysis applications.
Datafold shows how a change in SQL code affects your data, both on a statistical level and down to individual rows and values before it gets merged to production. Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows.
Data engineering inherits from years of data practices in US big companies. Hadoop initially led the way with Big Data and distributed computing on-premise to finally land on Modern Data Stack — in the cloud — with a datawarehouse at the center. workflows (Airflow, Prefect, Dagster, etc.)
Complete Guide to DataIngestion: Types, Process, and Best Practices Helen Soloveichik July 19, 2023 What Is DataIngestion? DataIngestion is the process of obtaining, importing, and processing data for later use or storage in a database. In this article: Why Is DataIngestion Important?
In the second part, we will focus on architectural patterns to implement data quality from a data contract perspective. Why is Data Quality Expensive? I won’t bore you with the importance of data quality in the blog. But before doing that, let's revisit some of the basic theories of the data pipeline.
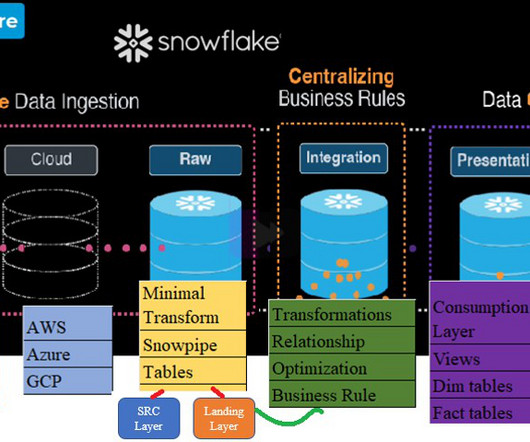
Read Time: 5 Minute, 16 Second As we know Snowflake has introduced latest badge “Data Cloud Deployment Framework” which helps to understand knowledge in designing, deploying, and managing the Snowflake landscape. Respective Cloud would consume/Store the data in bucket or containers. Snowpipe to automate the ingestion process.
You know what they always say: data lakehouse architecture is like an onion. …ok, Data lakehouse architecture combines the benefits of datawarehouses and data lakes, bringing together the structure and performance of a datawarehouse with the flexibility of a data lake.
Datafold shows how a change in SQL code affects your data, both on a statistical level and down to individual rows and values before it gets merged to production. Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows.
You know what they always say: data lakehouse architecture is like an onion. …ok, Data lakehouse architecture combines the benefits of datawarehouses and data lakes, bringing together the structure and performance of a datawarehouse with the flexibility of a data lake.
Organizations that depend on data for their success and survival need robust, scalable dataarchitecture, typically employing a datawarehouse for analytics needs. Snowflake is often their cloud-native datawarehouse of choice. Dataingestion must be performant to handle large amounts of data.
In this post, we will help you quickly level up your overall knowledge of data pipeline architecture by reviewing: Table of Contents What is data pipeline architecture? Why is data pipeline architecture important? What is data pipeline architecture? Why is data pipeline architecture important?
Data modeling is changing Typical data modeling techniques — like the star schema — which defined our approach to data modeling for the analytics workloads typically associated with datawarehouses, are less relevant than they once were.
Learn More → Notion: Building and scaling Notion’s data lake Notion writes about scaling the data lake by bringing critical dataingestion operations in-house. Hudi seems to be a de facto choice for CDC data lake features. Notion migrated the change data capture pipeline from FiveTran to Debezium.
Select Star’s data discovery platform solves that out of the box, with an automated catalog that includes lineage from where the data originated, all the way to which dashboards rely on it and who is viewing them every day. That’s where our friends at Ascend.io Can you describe what is driving the adoption of real-time analytics?
Data lakes emerged as expansive reservoirs where raw data in its most natural state could commingle freely, offering unprecedented flexibility and scalability. This article explains what a data lake is, its architecture, and diverse use cases. Datawarehouse vs. data lake in a nutshell.
Cloudera customers run some of the biggest data lakes on earth. These lakes power mission-critical, large-scale data analytics and AI use cases—including enterprise datawarehouses. This scalability ensures the data lakehouse remains responsive and performant, even as data complexity and usage patterns change over time.
The Ascend Data Automation Cloud provides a unified platform for dataingestion, transformation, orchestration, and observability. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java.
Summary The "data lakehouse" architecture balances the scalability and flexibility of data lakes with the ease of use and transaction support of datawarehouses. The Ascend Data Automation Cloud provides a unified platform for dataingestion, transformation, orchestration, and observability.
Datafold shows how a change in SQL code affects your data, both on a statistical level and down to individual rows and values before it gets merged to production. Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows.
Datafold shows how a change in SQL code affects your data, both on a statistical level and down to individual rows and values before it gets merged to production. Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows.
Technical Overview The project architecture is depicted as follows: Google Calendar -> Fivetran -> Snowflake -> dbt -> Snowflake Dashboard , with GitHub Actions orchestrating the deployment. Storage — Snowflake Snowflake, a cloud-based datawarehouse tailored for analytical needs, will serve as our data storage solution.
Companies, on the other hand, have continued to demand highly scalable and flexible analytic engines and services on the data lake, without vendor lock-in. Organizations want modern dataarchitectures that evolve at the speed of their business and we are happy to support them with the first open data lakehouse. .
Tools like Python’s requests library or ETL/ELT tools can facilitate data enrichment by automating the retrieval and merging of external data. Read More: Discover how to build a data pipeline in 6 steps Data Integration Data integration involves combining data from different sources into a single, unified view.
Data pipelines are a significant part of the big data domain, and every professional working or willing to work in this field must have extensive knowledge of them. As data is expanding exponentially, organizations struggle to harness digital information's power for different business use cases. What is a Big Data Pipeline?
Hello Dinesh, thank you for joining us for Part II of our Q&A on streaming data. Can you talk a bit about how businesses best use Flink within a streaming architecture and what is it about the solution that promotes low latency processing of high-volume streaming data?
The team at Skyflow decided that the second best way is to build a storage system dedicated to securely managing your sensitive information and making it easy to integrate with your applications and data systems. Data teams are increasingly under pressure to deliver. Data teams are increasingly under pressure to deliver.
Cloudera and Accenture demonstrate strength in their relationship with an accelerator called the Smart Data Transition Toolkit for migration of legacy datawarehouses into Cloudera Data Platform. Accenture’s Smart Data Transition Toolkit . Are you looking for your datawarehouse to support the hybrid multi-cloud?
The Rise of Data Observability Data observability has become increasingly critical as companies seek greater visibility into their data processes. This growing demand has found a natural synergy with the rise of the data lake.
Cloudera users can securely connect Rill to a source of event stream data, such as Cloudera DataFlow , model data into Rill’s cloud-based Druid service, and share live operational dashboards within minutes via Rill’s interactive metrics dashboard or any connected BI solution. Figure 1: Rill and Cloudera Architecture.
Select Star’s data discovery platform solves that out of the box, with an automated catalog that includes lineage from where the data originated, all the way to which dashboards rely on it and who is viewing them every day. That’s where our friends at Ascend.io That’s where our friends at Ascend.io
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content