This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data storage has been evolving, from databases to datawarehouses and expansive datalakes, with each architecture responding to different business and data needs. Now you dont have to choose. This is why Snowflake is fully embracing this open table format.
The goal of this post is to understand how data integrity best practices have been embraced time and time again, no matter the technology underpinning. In the beginning, there was a datawarehouse The datawarehouse (DW) was an approach to dataarchitecture and structured data management that really hit its stride in the early 1990s.
A comparative overview of datawarehouses, datalakes, and data marts to help you make informed decisions on data storage solutions for your dataarchitecture.
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. Each of these architectures has its own unique strengths and tradeoffs.
In this episode David Yaffe and Johnny Graettinger share the story behind the business and technology and how you can start using it today to build a real-time datalake without all of the headache. What is the impact of continuous data flows on dags/orchestration of transforms? RudderStack also supports real-time use cases.
Summary A data lakehouse is intended to combine the benefits of datalakes (cost effective, scalable storage and compute) and datawarehouses (user friendly SQL interface). Datalakes are notoriously complex. To start, can you share your definition of what constitutes a "Data Lakehouse"?
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. Open Table Format (OTF) architecture now provides a solution for efficient data storage, management, and processing while ensuring compatibility across different platforms.
Summary Datalakearchitectures have largely been biased toward batch processing workflows due to the volume of data that they are designed for. With more real-time requirements and the increasing use of streaming data there has been a struggle to merge fast, incremental updates with large, historical analysis.
With this 3rd platform generation, you have more real time data analytics and a cost reduction because it is easier to manage this infrastructure in the cloud thanks to managed services. We are Data Teams versus we have to patch the server with the latest version and do the tests. The number of subjects to automatize is not short.
Summary Building and maintaining a datalake is a choose your own adventure of tools, services, and evolving best practices. The flexibility and freedom that datalakes provide allows for generating significant value, but it can also lead to anti-patterns and inconsistent quality in your analytics.
More than 50% of data leaders recently surveyed by BCG said the complexity of their dataarchitecture is a significant pain point in their enterprise. As a result,” says BCG, “many companies find themselves at a tipping point, at risk of drowning in a deluge of data, overburdened with complexity and costs.”
Summary The current trend in data management is to centralize the responsibilities of storing and curating the organization’s information to a data engineering team. This organizational pattern is reinforced by the architectural pattern of datalakes as a solution for managing storage and access.
It incorporates elements from several Microsoft products working together, like Power BI, Azure Synapse Analytics, Data Factory, and OneLake, into a single SaaS experience. Fabric is meant for organizations looking for a single pane of glass across their data estate with seamless integration and a low learning curve for Microsoft users.
Summary Datalakes offer a great deal of flexibility and the potential for reduced cost for your analytics, but they also introduce a great deal of complexity. In order to bring the DBA into the new era of data management the team at Upsolver added a SQL interface to their datalake platform.
It’s not enough for businesses to implement and maintain a dataarchitecture. The unpredictability of market shifts and the evolving use of new technologies means businesses need more data they can trust than ever to stay agile and make the right decisions.
Summary One of the perennial challenges posed by datalakes is how to keep them up to date as new data is collected. In this episode Ori Rafael shares his experiences from Upsolver and building scalable stream processing for integrating and analyzing data, and what the tradeoffs are when coming from a batch oriented mindset.
Despite these limitations, datawarehouses, introduced in the late 1980s based on ideas developed even earlier, remain in widespread use today for certain business intelligence and data analysis applications. While datawarehouses are still in use, they are limited in use-cases as they only support structured data.
Summary A datalake can be a highly valuable resource, as long as it is well built and well managed. In this episode Yoni Iny, CTO of Upsolver, discusses the various components that are necessary for a successful datalake project, how the Upsolver platform is architected, and how modern datalakes can benefit your organization.
Summary Datawarehouse technology has been around for decades and has gone through several generational shifts in that time. The current trends in data warehousing are oriented around cloud native architectures that take advantage of dynamic scaling and the separation of compute and storage.
In this episode Yingjun Wu explains how it is architected to power analytical workflows on continuous data flows, and the challenges of making it responsive and scalable. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Datalakes are notoriously complex.
Cloud datawarehouses allow users to run analytic workloads with greater agility, better isolation and scale, and lower administrative overhead than ever before. The results demonstrate superior price performance of Cloudera DataWarehouse on the full set of 99 queries from the TPC-DS benchmark. Introduction.
Summary Designing a data platform is a complex and iterative undertaking which requires accounting for many conflicting needs. Designing a platform that relies on a datalake as its central architectural tenet adds additional layers of difficulty. Can you describe your current platform architecture?
Summary Databases and analytics architectures have gone through several generational shifts. A substantial amount of the data that is being managed in these systems is related to customers and their interactions with an organization. How has that changed the architectural approach to CDPs? Want to see Starburst in action?
Summary The market for datawarehouse platforms is large and varied, with options for every use case. We have partnered with organizations such as O’Reilly Media, Dataversity, and the Open Data Science Conference. Coming up this fall is the combined events of Graphorum and the DataArchitecture Summit.
The terms “ DataWarehouse ” and “ DataLake ” may have confused you, and you have some questions. Essentially, this is the difference between a lake and a warehouse. On the other hand, a datawarehouse contains historical data that has been cleaned and arranged. .
Datalakes are notoriously complex. Data observability has been gaining adoption for a number of years now, with a large focus on datawarehouses. How much of the complexity is due to the nature of streaming data vs. the architectural realities of Flink? Datalakes are notoriously complex.
Sign up now for early access to Materialize and get started with the power of streaming data with the same simplicity and low implementation cost as batch cloud datawarehouses. Go to [dataengineeringpodcast.com/materialize]([link] Support Data Engineering Podcast
The promise of a modern data lakehouse architecture. Imagine having self-service access to all business data, anywhere it may be, and being able to explore it all at once. Imagine quickly answering burning business questions nearly instantly, without waiting for data to be found, shared, and ingested.
By making the software be the owner of the data that it generates, we have to go through the trouble of extracting the information to then be used elsewhere. The team at Cinchy are working to bring about a new paradigm of software architecture that puts the data as the central element. No more scripts, just SQL.
In this episode the host Tobias Macey shares his reflections on recent experiences where the abstractions leaked and some observances on how to deal with that situation in a data platform architecture. You can collect, transform, and route data across your entire stack with its event streaming, ETL, and reverse ETL pipelines.
Data teams need to balance the need for robust, powerful data platforms with increasing scrutiny on costs. That’s why it’s essential for teams to choose the right architecture for the storage layer of their data stack. But, the options for data storage are evolving quickly. Let’s dive in.
CDC tools fuel analytical apps and mission-critical data feeds in banking and regulated industries, with use cases ranging from data synchronization, managing risk, and preventing fraud to driving personalization. Unlike datalakes, which are predominantly append-only, lakehouses support data mutation natively.
[link] Adam Bellemare & Thomas Betts: The End of the Bronze Age: Rethinking the Medallion Architecture I’m always a bit uncomfortable with medallion architecture since it is a glorified term for the traditional ETL process. link] All rights reserved ProtoGrowth Inc, India.
Modern dataarchitectures. To eliminate or integrate these silos, the public sector needs to adopt robust data management solutions that support modern dataarchitectures (MDAs). Deploying modern dataarchitectures. Lack of sharing hinders the elimination of fraud, waste, and abuse. Forrester ).
In 2010, a transformative concept took root in the realm of data storage and analytics — a datalake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. What is a datalake?
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management RudderStack helps you build a customer data platform on your warehouse or datalake. What are some of the tools and architectures that an organization might be able to replace with Agile Data Engine?
Summary Architectural decisions are all based on certain constraints and a desire to optimize for different outcomes. In data systems one of the core architectural exercises is data modeling, which can have significant impacts on what is and is not possible for downstream use cases.
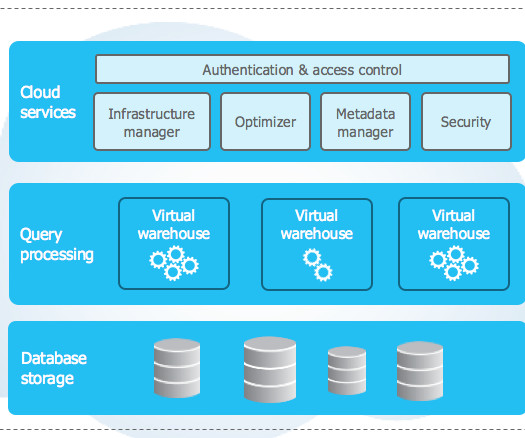
Snowflake DataWarehouse delivers essential infrastructure for handling a DataLake, and DataWarehouse needs. It can store semi-structured and structured data in one place due to its multi-clusters architecture that allows users to independently query data using SQL.
Cloudera customers run some of the biggest datalakes on earth. These lakes power mission critical large scale data analytics, business intelligence (BI), and machine learning use cases, including enterprise datawarehouses. On datawarehouses and datalakes.
How self-service data warehousing frees IT resources. Cloudera DataWarehouse (CDW) is a cloud service and an integral part of the newly released Cloudera Data Platform (CDP). Key features are: Highly scalable and performant open-source engines for BI and data warehousing workloads. Modern architecture.
Using the metaphor of a museum curator carefully managing the precious resources on display and in the vaults, he discusses the various layers of an enterprise data strategy. Can you walk through the stages of an ideal lifecycle for data within the context of an organizations uses for it?
Anyways, I wasn’t paying enough attention during university classes, and today I’ll walk you through data layers using — guess what — an example. Business Scenario & DataArchitecture Imagine this: next year, a new team on the grid, Red Thunder Racing, will call us (yes, me and you) to set up their new data infrastructure.
Many of our customers — from Marriott to AT&T — start their journey with the Snowflake AI Data Cloud by migrating their data warehousing workloads to the platform. Today we’re focusing on customers who migrated from a legacy datawarehouse to Snowflake and some of the benefits they saw.
Whether it’s customer transactions, IoT sensor readings, or just an endless stream of social media hot takes, you need a reliable way to get that data from point A to point B while doing something clever with it along the way. That’s where data pipeline design patterns come in. Lambda Architecture Pattern 4.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content