This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data storage has been evolving, from databases to data warehouses and expansive datalakes, with each architecture responding to different business and data needs. Traditional databases excelled at structureddata and transactional workloads but struggled with performance at scale as data volumes grew.
The goal of this post is to understand how data integrity best practices have been embraced time and time again, no matter the technology underpinning. In the beginning, there was a data warehouse The data warehouse (DW) was an approach to dataarchitecture and structureddata management that really hit its stride in the early 1990s.
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. Each of these architectures has its own unique strengths and tradeoffs.
The alternative, however, provides more multi-cloud flexibility and strong performance on structureddata. It incorporates elements from several Microsoft products working together, like Power BI, Azure Synapse Analytics, Data Factory, and OneLake, into a single SaaS experience.
In this blog, I will demonstrate the value of Cloudera DataFlow (CDF) , the edge-to-cloud streaming data platform available on the Cloudera Data Platform (CDP) , as a Data integration and Democratization fabric. Introduction to the Data Mesh Architecture and its Required Capabilities.
In 2010, a transformative concept took root in the realm of data storage and analytics — a datalake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. What is a datalake?
While data warehouses are still in use, they are limited in use-cases as they only support structureddata. Datalakes add support for semi-structured and unstructured data, and data lakehouses add further flexibility with better governance in a true hybrid solution built from the ground-up.
Whether it’s customer transactions, IoT sensor readings, or just an endless stream of social media hot takes, you need a reliable way to get that data from point A to point B while doing something clever with it along the way. That’s where data pipeline design patterns come in. Lambda Architecture Pattern 4.
The terms “ Data Warehouse ” and “ DataLake ” may have confused you, and you have some questions. Structuringdata refers to converting unstructured data into tables and defining data types and relationships based on a schema. What is DataLake? .
“DataLake vs Data Warehouse = Load First, Think Later vs Think First, Load Later” The terms datalake and data warehouse are frequently stumbled upon when it comes to storing large volumes of data. Data Warehouse Architecture What is a Datalake?
Datalakes are useful, flexible data storage repositories that enable many types of data to be stored in its rawest state. Traditionally, after being stored in a datalake, raw data was then often moved to various destinations like a data warehouse for further processing, analysis, and consumption.
Key Differences Between AI Data Engineers and Traditional Data Engineers While traditional data engineers and AI data engineers have similar responsibilities, they ultimately differ in where they focus their efforts. Data Storage Solutions As we all know, data can be stored in a variety of ways.
Data teams need to balance the need for robust, powerful data platforms with increasing scrutiny on costs. That’s why it’s essential for teams to choose the right architecture for the storage layer of their data stack. But, the options for data storage are evolving quickly.
Data pipelines are the backbone of your business’s dataarchitecture. Implementing a robust and scalable pipeline ensures you can effectively manage, analyze, and organize your growing data. Benjamin Kennedy, Cloud Solutions Architect at Striim, emphasizes the outcome-driven nature of data pipelines.
Over the past few years, datalakes have emerged as a must-have for the modern data stack. But while the technologies powering our access and analysis of data have matured, the mechanics behind understanding this data in a distributed environment have lagged behind. Data discovery tools and platforms can help.
In this context, data management in an organization is a key point for the success of its projects involving data. One of the main aspects of correct data management is the definition of a dataarchitecture. What is Delta Lake? The data became useless. The Lakehouse architecture was one of them.
The pun being obvious, there’s more to that than just a new term: Data lakehouses combine the best features of both datalakes and data warehouses and this post will explain this all. What is a data lakehouse? Data warehouse vs datalake vs data lakehouse: What’s the difference.
My personal take on justifying the existence of Data Mesh A senior stakeholder at one my projects mentioned that they wanted to decentralise their data platform architecture and democratise data across the organisation. When I heard the words ‘decentralised dataarchitecture’, I was left utterly confused at first!
Summary Data warehouse technology has been around for decades and has gone through several generational shifts in that time. The current trends in data warehousing are oriented around cloud native architectures that take advantage of dynamic scaling and the separation of compute and storage.
We have partnered with organizations such as O’Reilly Media, Corinium Global Intelligence, ODSC, and Data Council. Upcoming events include the Software Architecture Conference in NYC, Strata Data in San Jose, and PyCon US in Pittsburgh. Is there any utility in data vault modeling in a datalake context (S3, Hadoop, etc.)?
A data ingestion architecture is the technical blueprint that ensures that every pulse of your organization’s data ecosystem brings critical information to where it’s needed most. Data Transformation : Clean, format, and convert extracted data to ensure consistency and usability for both batch and real-time processing.
One of the innovative ways to address this problem is to build a data hub — a platform that unites all your information sources under a single umbrella. This article explains the main concepts of a data hub, its architecture, and how it differs from data warehouses and datalakes. What is Data Hub?
In this post, we will help you quickly level up your overall knowledge of data pipeline architecture by reviewing: Table of Contents What is data pipeline architecture? Why is data pipeline architecture important? What is data pipeline architecture? Why is data pipeline architecture important?
In the last few decades, we’ve seen a lot of architectural approaches to building data pipelines , changing one another and promising better and easier ways of deriving insights from information. There have been relational databases, data warehouses, datalakes, and even a combination of the latter two.
Data pipelines are a significant part of the big data domain, and every professional working or willing to work in this field must have extensive knowledge of them. As data is expanding exponentially, organizations struggle to harness digital information's power for different business use cases. What is a Big Data Pipeline?
In this post, we’ll attempt to explain the idea behind a data fabric, its architectural building blocks, the benefits it brings, and ways to approach its implementation. What is data fabric? to provide a unified view of all enterprise data. Data fabric architecture example. Data fabric vs data mesh.
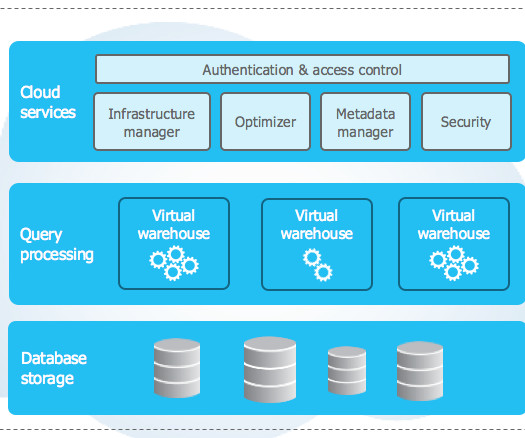
This blog walks you through what does Snowflake do , the various features it offers, the Snowflake architecture, and so much more. Table of Contents Snowflake Overview and Architecture What is Snowflake Data Warehouse? Snowflake is not based on existing database systems or big data software platforms like Hadoop.
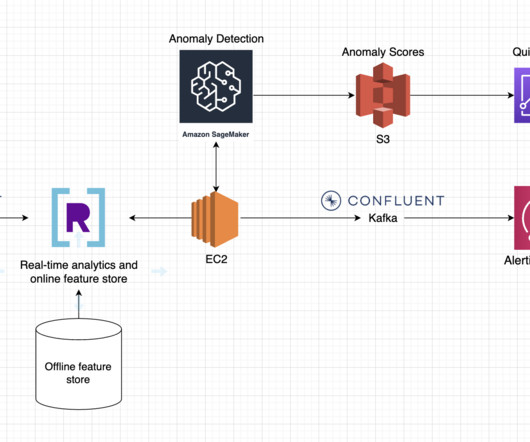
We’ve noticed many common patterns across streaming dataarchitectures and we’ll be sharing a blueprint for three of the most popular: anomaly detection, IoT, and recommendations. The majority of anomaly detectors require streaming data, real-time data and historical data in order to generate inferences.
Summary Working with unstructured data has typically been a motivation for a datalake. Kirk Marple has spent years working with data systems and the media industry, which inspired him to build a platform for automatically organizing your unstructured assets to make them more valuable.
The alleviation of infrastructure and computational constraints associated with solely on-premises data platforms; Data Products can now use different deployment models (e.g., The proliferation of real-time processing by deploying event-driven architectures (e.g., data warehousing). Deep Java Learning, Apache Spark 3.x,
Using easy-to-define policies, Replication Manager solves one of the biggest barriers for the customers in their cloud adoption journey by allowing them to move both tables/structureddata and files/unstructured data to the CDP cloud of their choice easily. CDP DataLake cluster versions – CM 7.4.0,
The holistic view of Hadoop architecture gives prominence to Hadoop common, Hadoop YARN, Hadoop Distributed File Systems (HDFS ) and Hadoop MapReduce of the Hadoop Ecosystem. HDFS in Hadoop architecture provides high throughput access to application data and Hadoop MapReduce provides YARN based parallel processing of large data sets.
Snowflake Data Warehouse delivers essential infrastructure for handling a DataLake, and Data Warehouse needs. It can store semi-structured and structureddata in one place due to its multi-clusters architecture that allows users to independently query data using SQL.
First, organizations have a tough time getting their arms around their data. More data is generated in ever wider varieties and in ever more locations. Organizations don’t know what they have anymore and so can’t fully capitalize on it — the majority of data generated goes unused in decision making. Unified data fabric.
Key connectivity features include: Data Ingestion: Databricks supports data ingestion from a variety of sources, including datalakes, databases, streaming platforms, and cloud storage. This flexibility allows organizations to ingest data from virtually anywhere.
Since data marts provide analytical capabilities for a restricted area of a data warehouse, they offer isolated security and isolated performance. Data mart vs data warehouse vs datalake vs OLAP cube. Datalakes, data warehouses, and data marts are all data repositories of different sizes.
It combines the best elements of a data warehouse, a centralized repository for structureddata, and a datalake used to host large amounts of raw data. The relatively new storage architecture powering Databricks is called a data lakehouse. Databricks lakehouse platform architecture.
What is unstructured data? Definition and examples Unstructured data , in its simplest form, refers to any data that does not have a pre-defined structure or organization. It can come in different forms, such as text documents, emails, images, videos, social media posts, sensor data, etc.
Based on Tecton blog So is this similar to data engineering pipelines into a datalake/warehouse? Schema drift on a wide table structure needs an ALTER TABLE statement, whereas the tall table structure does not. The friction of data movement is reduced. Yes, feature stores are part of the MLOps discipline.
Open source data lakehouse deployments are built on the foundations of compute engines (like Apache Spark, Trino, Apache Flink), distributed storage (HDFS, cloud blob stores), and metadata catalogs / table formats (like Apache Iceberg, Delta, Hudi, Apache Hive Metastore).
In the dynamic world of data, many professionals are still fixated on traditional patterns of data warehousing and ETL, even while their organizations are migrating to the cloud and adopting cloud-native data services. Central to this transformation are two shifts. Let’s take a closer look.
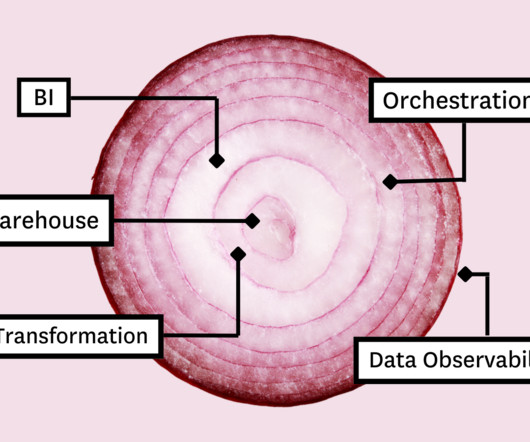
Known as the Modern Data Stack (MDS) , this suite of tools and technologies has transformed how businesses approach data management and analysis. What is a modern data stack? A data stack, in turn, focuses on data : It helps businesses manage data and make the most out of it. Modern data stack architecture.
In this blog post, we’ll look at six innovations that are shaping the future of the data warehousing, as well as challenges and considerations that organizations should keep in mind. Datalake and data warehouse convergence 2. Easier to stream real-time data 3. Zero-copy data sharing 4.
Before you can model the data for your stakeholders, you need a place to collect and store it. In simple terms, data transformation refers to the process of converting all that data from a variety of disparate formats into something consistent and useful for modeling. Image courtesy of Databricks.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content