This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A data engineering architecture is the structural framework that determines how data flows through an organization – from collection and storage to processing and analysis. It’s the big blueprint we data engineers follow in order to transform raw data into valuable insights.
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. Though basic and easy to use, traditional table storage formats struggle to keep up. Track data files within the table along with their column statistics.
Datastorage has been evolving, from databases to data warehouses and expansive data lakes, with each architecture responding to different business and data needs. Traditional databases excelled at structured data and transactional workloads but struggled with performance at scale as data volumes grew.
A comparative overview of data warehouses, data lakes, and data marts to help you make informed decisions on datastorage solutions for your dataarchitecture.
A headless dataarchitecture separates datastorage, management, optimization, and access from services that write, process, and query it—creating a single point of access control.
These can sometimes involve running parallel architectures (analytical batches and real-time streams) and trying to reach a level of quality control that is not possible to the degree most would like. Challenges still exist of course.
In my recent blog, I researched OLAP technologies, for this post I chose some open-source technologies and used them together to build a full dataarchitecture for a Data Warehouse system. I went with Apache Druid for datastorage, Apache Superset for querying and Apache Airflow as a task orchestrator.
It means that there is a high risk of data loss but Apache Kafka solves this because it is distributed and can easily scale horizontally and other servers can take over the workload seamlessly. Kafka can also be used to stream data from IoT devices or sensors. Let’s get started!
Whether it’s customer transactions, IoT sensor readings, or just an endless stream of social media hot takes, you need a reliable way to get that data from point A to point B while doing something clever with it along the way. That’s where data pipeline design patterns come in. Lambda Architecture Pattern 4.
A data ingestion architecture is the technical blueprint that ensures that every pulse of your organization’s data ecosystem brings critical information to where it’s needed most. DataStorage : Store validated data in a structured format, facilitating easy access for analysis.
Azure architecture includes all the ideas and elements needed to build a safe, dependable, and scalable cloud application. The resources are distributed across multiple data centers and global areas, adhering to a distributed paradigm. What Is Microsoft Azure Cloud Architecture? What are the key components of Azure Architecture?
Key Differences Between AI Data Engineers and Traditional Data Engineers While traditional data engineers and AI data engineers have similar responsibilities, they ultimately differ in where they focus their efforts. DataStorage Solutions As we all know, data can be stored in a variety of ways.
It’s challenging to integrate data from various sources and manage massive data pipelines while preserving high performance and dependability. The difficulty is in creating scalable and resilient architectures. Advanced Data Visualisation Tools More people will want data visualization tools that are easier to use.
The way to achieve this balance is by moving to a modern dataarchitecture (MDA) that makes it easier to manage, integrate, and govern large volumes of distributed data. When you deploy a platform that supports MDA you can consolidate other systems, like legacy data mediation and disparate datastorage solutions.
DataOps Architecture: 5 Key Components and How to Get Started Ryan Yackel August 30, 2023 What Is DataOps Architecture? DataOps is a collaborative approach to data management that combines the agility of DevOps with the power of data analytics. As a result, they can be slow, inefficient, and prone to errors.
[link] Sneha Ghantasala: Slow Reads for S3 Files in Pandas & How to Optimize it DeepSeek’s Fire-Flyer File System (3FS) re-triggers the importance of an optimized file system for efficient data processing.
[link] Adam Bellemare & Thomas Betts: The End of the Bronze Age: Rethinking the Medallion Architecture I’m always a bit uncomfortable with medallion architecture since it is a glorified term for the traditional ETL process. link] All rights reserved ProtoGrowth Inc, India.
You know what they always say: data lakehouse architecture is like an onion. …ok, Data lakehouse architecture combines the benefits of data warehouses and data lakes, bringing together the structure and performance of a data warehouse with the flexibility of a data lake. Storage layer 3.
You know what they always say: data lakehouse architecture is like an onion. …ok, Data lakehouse architecture combines the benefits of data warehouses and data lakes, bringing together the structure and performance of a data warehouse with the flexibility of a data lake. Storage layer 3.
It stores all the metadata created within a ThoughtSpot instance to enable efficient querying, retrieval, and management of data objects. While Atlas operates as an in-memory graph database for speed and performance, it uses PostgreSQL as its persistent storage layer to ensure durability and long-term datastorage.
In this post, we will help you quickly level up your overall knowledge of data pipeline architecture by reviewing: Table of Contents What is data pipeline architecture? Why is data pipeline architecture important? What is data pipeline architecture? Why is data pipeline architecture important?
In 2010, a transformative concept took root in the realm of datastorage and analytics — a data lake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. What is a data lake?
Introduction to DataArchitectureDataarchitecture shows how data is managed, from collection to transformation to distribution and consumption. It tells about how data flows through the datastorage systems. Dataarchitecture is an important piece of data management.
And so we are thrilled to introduce our latest applied ML prototype (AMP) — a large language model (LLM) chatbot customized with website data using Meta’s Llama2 LLM and Pinecone’s vector database. An overview of the RAG architecture with a vector database used to minimize hallucinations in the chatbot application.
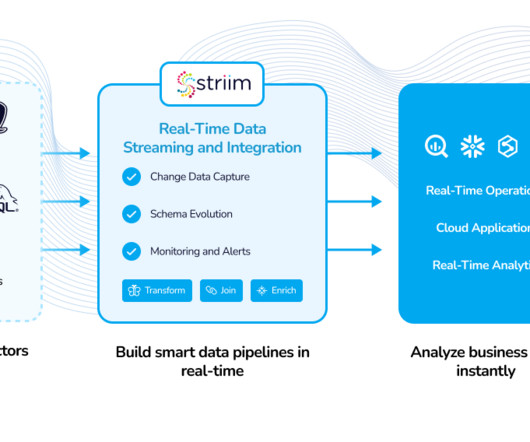
Data Mesh is revolutionizing event streaming architecture by enabling organizations to quickly and easily integrate real-time data, streaming analytics, and more. In this article, we will explore the advantages and limitations of data mesh, while also providing best practices for building and optimizing a data mesh with Striim.
Through careful co-design of the network, software, and model architectures, we have successfully used both RoCE and InfiniBand clusters for large, GenAI workloads (including our ongoing training of Llama 3 on our RoCE cluster) without any network bottlenecks.
Our technical solution builds on Meta’s existing client / server architecture We think the best way to deliver interoperability is through a solution which builds on Meta’s existing client / server architecture [Figure 1]. The proof is constructed by the third-party service cryptographically signing an authentication token.
Since 2013 the UK Government’s flagship ‘Cloud First’ policy has been at the forefront of enabling departments to shed their legacy IT architecture in order to meaningfully embrace digital transformation. Whilst two of the big three have UK data centres – what happens if they go down?
Storage We need efficient data-storage solutions to store the vast amounts of data used in model training. This involves investing in high-capacity and high-speed storage technologies and developing new data-storage solutions for specific workloads.
Data pipelines are the backbone of your business’s dataarchitecture. Implementing a robust and scalable pipeline ensures you can effectively manage, analyze, and organize your growing data. Benjamin Kennedy, Cloud Solutions Architect at Striim, emphasizes the outcome-driven nature of data pipelines.
The Current State of the DataArchitecture S3 intelligent tiered storage provides a fine balance between the cost and the duration of the data retention. However, the real-time insight on accessing the recent data remains a big challenge. The combination of stream processing + OLAP storage like Pinot.
Each of these technologies has its own strengths and weaknesses, but all of them can be used to gain insights from large data sets. As organizations continue to generate more and more data, big data technologies will become increasingly essential. Let's explore the technologies available for big data.
Prior to making a decision, an organization must consider the Total Cost of Ownership (TCO) for each potential data warehousing solution. On the other hand, cloud data warehouses can scale seamlessly. Vertical scaling refers to the increase in capability of existing computational resources, including CPU, RAM, or storage capacity.
Hybrid Horses for Courses: The Right Cloud for AI from Pilot to Production at Scale Later, on May 14 at 12:40 pm BST , hear from Mark Samson, one of Cloudera’s solutions engineering directors, on whether a data center or cloud deployment is best for your organization’s data platform and architecture.
For example, the datastorage systems and processing pipelines that capture information from genomic sequencing instruments are very different from those that capture the clinical characteristics of a patient from a site. A conceptual architecture illustrating this is shown in Figure 3.
Either way, they want the freedom to safely use multiple engines on a single copy of data to minimize the storage and compute costs associated with moving data or maintaining multiple copies. Catalogs play a critical role in a multi-engine architecture.
∘ Introduction ∘ Problem Statement ∘ Data ∘ AWS Architecture ∘ DataStorage with AWS S3 ∘ Designing the Schema ∘ ETL with AWS Glue ∘ Data Warehousing with AWS Redshift ∘ Extracting Insights…
What are some of the tools and system architectures that users turn to when building analytical workloads for data stored in Cassandra? The architecture of Cassandra has lent itself well to the cloud native ecosystem that has been growing in recent years. Cassandra is primarily used as a system of record.
Legacy SIEM cost factors to keep in mind Data ingestion: Traditional SIEMs often impose limits to data ingestion and data retention. Snowflake allows security teams to store all their data in a single platform and maintain it all in a readily accessible state, with virtually unlimited cloud datastorage capacity.
Concepts, theory, and functionalities of this modern datastorage framework Photo by Nick Fewings on Unsplash Introduction I think it’s now perfectly clear to everybody the value data can have. To use a hyped example, models like ChatGPT could only be built on a huge mountain of data, produced and collected over years.
He also discusses the shifts in database architectures from vertically integrated monoliths to separately deployed layers, and the approach he is taking with TileDB cloud to embed the authorization into the storage engine, while providing a flexible interface for compute. How is the built in data versioning implemented?
There is an introduction post about DataHub — when you look at what you have to run to launch a data catalog: 4 components and 4 different datastorage. Don't be surprised if no ones uses data catalogs. When I think that some people are saying Airflow is complex to launch.
Scalability: How To Build Scalable Pipelines Scalability is a fundamental aspect of future-proofing your data pipelines. As data volumes grow, pipelines must efficiently handle increased loads without compromising performance. Here are three strategies to ensure your pipelines are scalable: a.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content