This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
source: svitla.com Introduction Before jumping to the datawarehouse interview questions, let’s first understand the overview of a datawarehouse. The data is then organized and structured […] The post DataWarehouse Interview Questions appeared first on Analytics Vidhya.
This is where data warehousing is a critical component of any business, allowing companies to store and manage vast amounts of data. It provides the necessary foundation for businesses to […] The post Understanding the Basics of DataWarehouse and its Structure appeared first on Analytics Vidhya.
The goal of this post is to understand how data integrity best practices have been embraced time and time again, no matter the technology underpinning. In the beginning, there was a datawarehouse The datawarehouse (DW) was an approach to dataarchitecture and structured data management that really hit its stride in the early 1990s.
A comparative overview of datawarehouses, data lakes, and data marts to help you make informed decisions on data storage solutions for your dataarchitecture.
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. Open Table Format (OTF) architecture now provides a solution for efficient data storage, management, and processing while ensuring compatibility across different platforms.
Did you know Cloudera customers, such as SMG and Geisinger , offloaded their legacy DW environment to Cloudera DataWarehouse (CDW) to take advantage of CDW’s modern architecture and best-in-class performance? In the following sections, we are going to show you how to use HPL/SQL in Cloudera DataWarehouse (CDW).
Data storage has been evolving, from databases to datawarehouses and expansive data lakes, with each architecture responding to different business and data needs. Traditional databases excelled at structured data and transactional workloads but struggled with performance at scale as data volumes grew.
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. Each of these architectures has its own unique strengths and tradeoffs.
More than 50% of data leaders recently surveyed by BCG said the complexity of their dataarchitecture is a significant pain point in their enterprise. As a result,” says BCG, “many companies find themselves at a tipping point, at risk of drowning in a deluge of data, overburdened with complexity and costs.”
They developed a /data command internally that answer questions about everything and structured the analytics around a foundational data platform with company-wide analytics data layer that provides time series efficiency metrics across various business use cases. when you have a semantic layer).
With this 3rd platform generation, you have more real time data analytics and a cost reduction because it is easier to manage this infrastructure in the cloud thanks to managed services. We are Data Teams versus we have to patch the server with the latest version and do the tests.
Summary A data lakehouse is intended to combine the benefits of data lakes (cost effective, scalable storage and compute) and datawarehouses (user friendly SQL interface). To start, can you share your definition of what constitutes a "Data Lakehouse"? Want to see Starburst in action?
Rethinking data warehousing: Why redefinition is necessary even beyond Modern DataWarehouse (MDW) and Lakehouse Models Continue reading on Towards Data Science »
It’s not enough for businesses to implement and maintain a dataarchitecture. The unpredictability of market shifts and the evolving use of new technologies means businesses need more data they can trust than ever to stay agile and make the right decisions.
What used to be bespoke and complex enterprise data integration has evolved into a modern dataarchitecture that orchestrates all the disparate data sources intelligently and securely, even in a self-service manner: a data fabric. Cloudera data fabric and analyst acclaim. Next steps.
A fundamental challenge with today’s “data explosion” is finding the best answer to the question, “So where do I put my data?” while avoiding the longer-term problem of datawarehouses, […].
The promise of a modern data lakehouse architecture. Imagine having self-service access to all business data, anywhere it may be, and being able to explore it all at once. Imagine quickly answering burning business questions nearly instantly, without waiting for data to be found, shared, and ingested.
Folding data into pointers. On 64-bit architectures, pointers store memory addresses using 8 bytes. But on architectures like x86 and ARM the linear address is limited to 48 bits long, with bits 49 to 64 reserved for future usage. Intel Level 5 proposal 64-bit memory address.
By making the software be the owner of the data that it generates, we have to go through the trouble of extracting the information to then be used elsewhere. The team at Cinchy are working to bring about a new paradigm of software architecture that puts the data as the central element. No more scripts, just SQL.
Summary The ecosystem for data tools has been going through rapid and constant evolution over the past several years. These technological shifts have brought about corresponding changes in data and platform architectures for managing data and analytical workflows. Tired of deploying bad data?
Nowadays, when it comes to data management, every business has to make one critical decision: whether to use a Data Mesh or a DataWarehouse. Both are strong data management architectures, but they are designed to support different needs and various organizational structures.
Modern dataarchitectures. To eliminate or integrate these silos, the public sector needs to adopt robust data management solutions that support modern dataarchitectures (MDAs). Deploying modern dataarchitectures. Lack of sharing hinders the elimination of fraud, waste, and abuse. Forrester ).
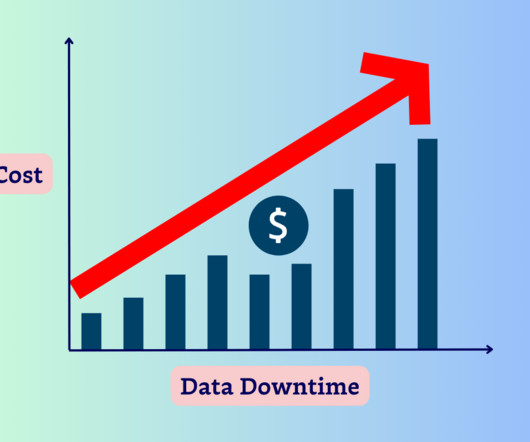
Our calculator estimates the cost of this poor data quality would be: 400 data incidents per year 2400 data downtime hours per year $156,587 in resource cost $2,671,232 in efficiency cost The Data Quality Calculator provides the estimated cost of bad data by leveraging data from hundreds of datawarehouses and millions of tables.
Data volume and velocity, governance, structure, and regulatory requirements have all evolved and continue to. Despite these limitations, datawarehouses, introduced in the late 1980s based on ideas developed even earlier, remain in widespread use today for certain business intelligence and data analysis applications.
Summary Databases and analytics architectures have gone through several generational shifts. A substantial amount of the data that is being managed in these systems is related to customers and their interactions with an organization. How has that changed the architectural approach to CDPs? Want to see Starburst in action?
Sign up now for early access to Materialize and get started with the power of streaming data with the same simplicity and low implementation cost as batch cloud datawarehouses. Go to [dataengineeringpodcast.com/materialize]([link] Support Data Engineering Podcast
With instant elasticity, high-performance, and secure data sharing across multiple clouds , Snowflake has become highly in-demand for its cloud-based datawarehouse offering. As organizations adopt Snowflake for business-critical workloads, they also need to look for a modern data integration approach.
Were sharing how Meta built support for data logs, which provide people with additional data about how they use our products. Here we explore initial system designs we considered, an overview of the current architecture, and some important principles Meta takes into account in making data accessible and easy to understand.
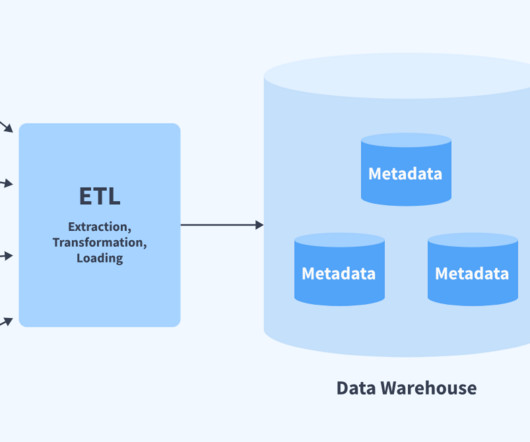
Batch processing: data is typically extracted from databases at the end of the day, saved to disk for transformation, and then loaded in batch to a datawarehouse. Batch data integration is useful for data that isn’t extremely time-sensitive. Electric bills are a relevant example.
Trusted by teams of all sizes, including Comcast and Doordash, Starburst is a data lake analytics platform that delivers the adaptability and flexibility a lakehouse ecosystem promises. What are some of the platforms/architectures that teams are replacing with RisingWave? Want to see Starburst in action?
CDC tools fuel analytical apps and mission-critical data feeds in banking and regulated industries, with use cases ranging from data synchronization, managing risk, and preventing fraud to driving personalization. This approach simplifies dataarchitecture and enhances performance by reducing data movement and latency.
Summary Data lake architectures have largely been biased toward batch processing workflows due to the volume of data that they are designed for. With more real-time requirements and the increasing use of streaming data there has been a struggle to merge fast, incremental updates with large, historical analysis.
Data observability has been gaining adoption for a number of years now, with a large focus on datawarehouses. How much of the complexity is due to the nature of streaming data vs. the architectural realities of Flink? How have the requirements of generative AI shifted the demand for streaming data systems?
In this post, we will be particularly interested in the impact that cloud computing left on the modern datawarehouse. We will explore the different options for data warehousing and how you can leverage this information to make the right decisions for your organization. Understanding the Basics What is a DataWarehouse?
[link] Adam Bellemare & Thomas Betts: The End of the Bronze Age: Rethinking the Medallion Architecture I’m always a bit uncomfortable with medallion architecture since it is a glorified term for the traditional ETL process. link] All rights reserved ProtoGrowth Inc, India.
Can you describe the architecture of your Flow platform? What is involved in getting Flow/Estuary deployed and integrated with an organization's data systems? How does it impact the overall system architecture for a data platform as compared to other prevalent paradigms? RudderStack also supports real-time use cases.
My personal take on justifying the existence of Data Mesh A senior stakeholder at one my projects mentioned that they wanted to decentralise their data platform architecture and democratise data across the organisation. When I heard the words ‘decentralised dataarchitecture’, I was left utterly confused at first!
Kappa Architectures are becoming a popular way of unifying real-time (streaming) and historical (batch) analytics giving you a faster path to realizing business value with your pipelines. Kappa Architecture combines streaming and batch while simultaneously turning datawarehouses and data lakes into near real-time sources of truth.
Whether it’s customer transactions, IoT sensor readings, or just an endless stream of social media hot takes, you need a reliable way to get that data from point A to point B while doing something clever with it along the way. That’s where data pipeline design patterns come in. Lambda Architecture Pattern 4.
Key Differences Between AI Data Engineers and Traditional Data Engineers While traditional data engineers and AI data engineers have similar responsibilities, they ultimately differ in where they focus their efforts. Data Storage Solutions As we all know, data can be stored in a variety of ways.
What are some of the tools and architectures that an organization might be able to replace with Agile Data Engine? How does the unified experience of Agile Data Engine change the way that teams think about the lifecycle of their data? What does CI/CD look like for a datawarehouse?
Let’s walk through how to transform your scrappy data setup into a robust pipeline that’s ready to grow with your business. Gone are the days of just dumping everything into a single database; modern dataarchitectures typically use a combination of data lakes and warehouses.
In this episode the host Tobias Macey shares his reflections on recent experiences where the abstractions leaked and some observances on how to deal with that situation in a data platform architecture. You can collect, transform, and route data across your entire stack with its event streaming, ETL, and reverse ETL pipelines.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content