This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The fact that ETLtools evolved to expose graphical interfaces seems like a detour in the history of data processing, and would certainly make for an interesting blog post of its own. Let’s highlight the fact that the abstractions exposed by traditional ETLtools are off-target.
Some of the common challenges with data ingestion in Hadoop are parallel processing, data quality, machine data on a higher scale of several gigabytes per minute, multiple source ingestion, real-time ingestion and scalability. Sqoop hadoop can also be used for exporting data from HDFS into RDBMS.
In the contemporary age of Big Data, DataWarehouse Systems and Data Science Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. So why using IaC for Cloud Data Infrastructures?
Ascend is a compelling option for managing these integration workflows, offering automation and scalability to streamline data integration tasks. With its capabilities, users can efficiently extract data from various databases, reconcile differences in formats, and load the integrated data into a datawarehouse or other target systems.
StreamSets DataOps Platform is the world’s first single platform for building smart data pipelines across hybrid and multi-cloud architectures. Build, run, monitor and manage data pipelines confidently with an end-to-end data integration platform that’s built for constant change.
Data lakes emerged as expansive reservoirs where raw data in its most natural state could commingle freely, offering unprecedented flexibility and scalability. This article explains what a data lake is, its architecture, and diverse use cases. Datawarehouse vs. data lake in a nutshell.
Data pipelines are a significant part of the big data domain, and every professional working or willing to work in this field must have extensive knowledge of them. As data is expanding exponentially, organizations struggle to harness digital information's power for different business use cases. What is a Big Data Pipeline?
Next-gen product analytics is now warehouse-native, an architectural approach that allows for the separation of code and data. In this model, providers of next-gen product analytics maintain code for the analytical application as a connected app, while customers manage the data in their own cloud data platform.
Data engineer’s responsibilities — Development and Architecture. Data engineer’s integral task is building and maintaining data infrastructure — the system managing the flow of data from its source to destination. Engineers can build different types of architectures by mixing and matching these parts.
With so much riding on the efficiency of ETL processes for data engineering teams, it is essential to take a deep dive into the complex world of ETL on AWS to take your data management to the next level. ETL has typically been carried out utilizing datawarehouses and on-premise ETLtools.
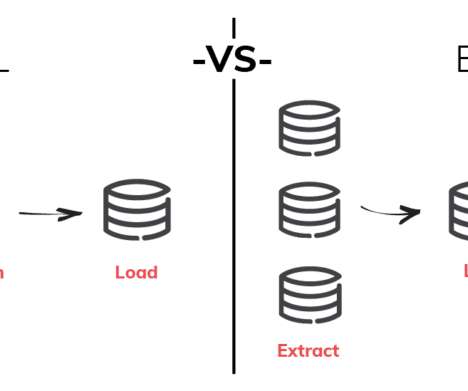
Data Ingestion Data ingestion is the first step of both ETL and data pipelines. In the ETL world, this is called data extraction, reflecting the initial effort to pull data out of source systems. The data sources themselves are not built to perform analytics.
Now let’s think of sweets as the data required for your company’s daily operations. Instead of combing through the vast amounts of all organizational data stored in a datawarehouse, you can use a data mart — a repository that makes specific pieces of data available quickly to any given business unit.
The last three years have seen a remarkable change in data infrastructure. ETL changed towards ELT. Now, data teams are embracing a new approach: reverse ETL. Cloud datawarehouses, such as Snowflake and BigQuery, have made it simpler than ever to combine all of your data into one location.
era of Data Catalog Let’s call the pre-modern era; as the state of DataWarehouses before the explosion of big data and subsequent cloud datawarehouse adoption. Applications deployed in a large monolithic web server with all the datawarehouse changes go through a central dataarchitecture team.
The technology was written in Java and Scala in LinkedIn to solve the internal problem of managing continuous data flows. The number of possible applications tends to grow due to the rise of IoT , Big Data analytics , streaming media, smart manufacturing, predictive maintenance , and other data-intensive technologies.
2: The majority of Flink shops are in earlier phases of maturity We talked to numerous developer teams who had migrated workloads from legacy ETLtools, Kafka streams, Spark streaming, or other tools for the efficiency and speed of Flink. Cloudera Perspective: Deployment architecture matters. Takeaway No. Takeaway No.
In the dynamic world of data, many professionals are still fixated on traditional patterns of data warehousing and ETL, even while their organizations are migrating to the cloud and adopting cloud-native data services. Modern platforms like Redshift , Snowflake , and BigQuery have elevated the datawarehouse model.
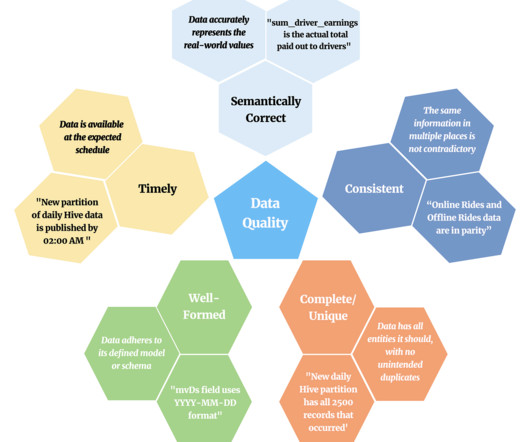
In this post we will define data quality at a high-level and explore our motivation to achieve better data quality. We will then introduce our in-house product, Verity, and showcase how it serves as a central platform for ensuring data quality in our Hive DataWarehouse. What and Where is Data Quality?
Often it is a datawarehouse solution (DWH) in the central part of our infrastructure. Datawarehouse exmaple. It’s worth mentioning that its data frame transformations have been included in one of the basic methods of data loading for many modern datawarehouses.
They work together with stakeholders to get business requirements and develop scalable and efficient dataarchitectures. Role Level Advanced Responsibilities Design and architect data solutions on Azure, considering factors like scalability, reliability, security, and performance.
Modern data teams have all the right solutions in place to ensure that data is ingested, stored, transformed, and loaded into their datawarehouse, but what happens at “the last mile?” In other words, how can data analysts and engineers ensure that transformed, actionable data is actually available to access and use?
This blog aims to answer two questions as illustrated in the diagram below: How have stream processing requirements and use cases evolved as more organizations shift to “streaming first” architectures and attempt to build streaming analytics pipelines? Better yet, it works in any cloud environment.
Meltano is a DataOps platform that enables data engineers to streamline data management and keep all stages of data production in a single place. Analysis While data engineers don’t typically analyze data, they can prepare the data for analysis for data scientists and business analysts to access and derive insights.
In today's data-driven world, businesses need to extract, transform, and load data from multiple data sources because of the large amount of data which businesses generate. An ETL pipeline is one of the most common solutions for the efficient processing of large data. What is an ETL Pipeline?
A 2016 data science report from data enrichment platform CrowdFlower found that data scientists spend around 80% of their time in data preparation (collecting, cleaning, and organizing of data) before they can even begin to build machine learning (ML) models to deliver business value.
It combines the best elements of a datawarehouse, a centralized repository for structured data, and a data lake used to host large amounts of raw data. The relatively new storage architecture powering Databricks is called a data lakehouse. Databricks lakehouse platform architecture.
Understanding the Architecture No company is alike and no infrastructure will be alike. Although there are some guidelines that you can follow when setting up a data infrastructure, each company has it's own needs, processes and organizational structure. Data Sources: How different are your data sources?
They use tools like Microsoft Power BI or Oracle BI to develop dashboards, reports, and Key Performance Indicator (KPI) scorecards. They should know SQL queries, SQL Server Reporting Services (SSRS), and SQL Server Integration Services (SSIS) and a background in Data Mining and DataWarehouse Design.
If you encounter Big Data on a regular basis, the limitations of the traditional ETLtools in terms of storage, efficiency and cost is likely to force you to learn Hadoop. Systems that contain the data are often not the ones that consume it and Hadoop is changing that concept.
The platform’s massive parallel processing (MPP) architecture empowers you with high-performance querying of even massive datasets. Polyglot Data Processing Synapse speaks your language! This capability fosters a more flexible dataarchitecture where data can be processed and analyzed in its raw form.
The responsibilities of a data engineer imply that the person in this role designs, creates, develops, and maintains systems and architecture that allow them to collect, store, and interpret data. Design algorithms transforming raw data into actionable information for strategic decisions.
In the post, we will investigate how to become an Azure data engineer, the skills required, the roles and responsibilities of an Azure data engineer, and much more. Who is an Azure Data Engineer? This involves knowing how to manage data partitions, load data into a datawarehouse, and speed up query execution.
The responsibilities of a DataOps engineer include: Building and optimizing data pipelines to facilitate the extraction of data from multiple sources and load it into datawarehouses. A DataOps engineer must be familiar with extract, load, transform (ELT) and extract, transform, load (ETL) tools.
Data integration defines the process of collecting data from a number of disparate source systems and presenting it in a unified form within a centralized location like a datawarehouse. So, why is data integration such a big deal? Connections to both datawarehouses and data lakes are possible in any case.
We as Azure Data Engineers should have extensive knowledge of data modelling and ETL (extract, transform, load) procedures in addition to extensive expertise in creating and managing data pipelines, data lakes, and datawarehouses. ETL activities are also the responsibility of data engineers.
As a data engineer description, you must be ready to explore large-scale data processing and use your expertise and soft skills to ensure a scalable and reliable working environment. Data engineers need to work with large amounts of data and maintain the architectures used in various data science projects.
An Azure Data Engineer is a highly qualified expert who is in charge of integrating, transforming, and merging data from various structured and unstructured sources into a structure that can be used to build analytics solutions. Learn about popular ETLtools such as Xplenty, Stitch, Alooma, and others.
Let’s discuss how to convert events from an event-driven microservice architecture into relational tables in a warehouse like Snowflake. We use Snowflake as our datawarehouse where we build dashboards both for internal use and for customers. This data would become the main dbt sources used by our report models in BI.
Introduction Amazon Redshift, a cloud datawarehouse service from Amazon Web Services (AWS), will directly query your structured and semi-structured data with SQL. Amazon Redshift Serverless allows customers to analyze and query data without configuring and managing a datawarehouse.
While working as a big data engineer, there are some roles and responsibilities one has to do: Designing large data systems starts with designing a capable system that can handle large workloads. Develop the algorithms: Once the database is ready, the next thing is to analyze the data to obtain valuable insights.
While working as a big data engineer, there are some roles and responsibilities one has to do: Designing large data systems starts with designing a capable system that can handle large workloads. Develop the algorithms: Once the database is ready, the next thing is to analyze the data to obtain valuable insights.
The task of integrating, manipulating, and merging data from diverse structured and unstructured sources into a structure utilized to build analytics solutions falls within the purview of an Azure Data Engineer, a highly qualified specialist. How Can I Prepare for the Azure Data Engineer Certification Exam?
This integration allows you to version control your data factory resources, automate testing, and deploy changes across different environments with ease. Integrated Security This tool has a bunch of powerful security features seamlessly woven into its architecture. Is Azure Data Factory an ETLtool?
Big Data Engineer performs a multi-faceted role in an organization by identifying, extracting, and delivering the data sets in useful formats. A Big Data Engineer also constructs, tests, and maintains the Big Dataarchitecture. Your organization will use internal and external sources to port the data.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content