

8 Essential Data Pipeline Design Patterns You Should Know
Monte Carlo
NOVEMBER 21, 2024
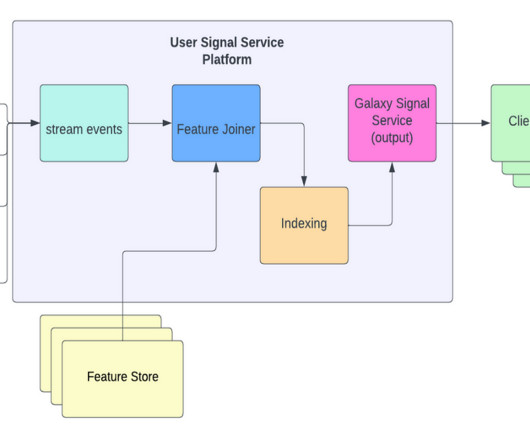
Whether it’s customer transactions, IoT sensor readings, or just an endless stream of social media hot takes, you need a reliable way to get that data from point A to point B while doing something clever with it along the way. That’s where data pipeline design patterns come in. Lambda Architecture Pattern 4.

















Let's personalize your content