This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The goal of this post is to understand how data integrity best practices have been embraced time and time again, no matter the technology underpinning. In the beginning, there was a datawarehouse The datawarehouse (DW) was an approach to dataarchitecture and structureddata management that really hit its stride in the early 1990s.
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. Each of these architectures has its own unique strengths and tradeoffs.
Data storage has been evolving, from databases to datawarehouses and expansive data lakes, with each architecture responding to different business and data needs. Traditional databases excelled at structureddata and transactional workloads but struggled with performance at scale as data volumes grew.
Summary Datawarehouses have gone through many transformations, from standard relational databases on powerful hardware, to column oriented storage engines, to the current generation of cloud-native analytical engines. If you are evaluating your options for building or migrating a data platform, then this is definitely worth a listen.
Summary Datawarehouse technology has been around for decades and has gone through several generational shifts in that time. The current trends in data warehousing are oriented around cloud native architectures that take advantage of dynamic scaling and the separation of compute and storage.
Usually Data scientists and engineers write Extract-Transform-Load (ETL) jobs and pipelines using big data compute technologies, like Spark or Presto , to process this data and periodically compute key information for a member or a video. The processed data is typically stored as datawarehouse tables in AWS S3.
The alternative, however, provides more multi-cloud flexibility and strong performance on structureddata. Fabric is meant for organizations looking for a single pane of glass across their data estate with seamless integration and a low learning curve for Microsoft users. Next, we will see what Snowflake is What is Snowflake?
Snowflake DataWarehouse delivers essential infrastructure for handling a Data Lake, and DataWarehouse needs. It can store semi-structured and structureddata in one place due to its multi-clusters architecture that allows users to independently query data using SQL.
Data volume and velocity, governance, structure, and regulatory requirements have all evolved and continue to. Despite these limitations, datawarehouses, introduced in the late 1980s based on ideas developed even earlier, remain in widespread use today for certain business intelligence and data analysis applications.
Whether it’s customer transactions, IoT sensor readings, or just an endless stream of social media hot takes, you need a reliable way to get that data from point A to point B while doing something clever with it along the way. That’s where data pipeline design patterns come in. Lambda Architecture Pattern 4.
Two popular approaches that have emerged in recent years are datawarehouse and big data. While both deal with large datasets, but when it comes to datawarehouse vs big data, they have different focuses and offer distinct advantages. Data warehousing offers several advantages.
Key Differences Between AI Data Engineers and Traditional Data Engineers While traditional data engineers and AI data engineers have similar responsibilities, they ultimately differ in where they focus their efforts. Data Storage Solutions As we all know, data can be stored in a variety of ways.
My personal take on justifying the existence of Data Mesh A senior stakeholder at one my projects mentioned that they wanted to decentralise their data platform architecture and democratise data across the organisation. When I heard the words ‘decentralised dataarchitecture’, I was left utterly confused at first!
The terms “ DataWarehouse ” and “ Data Lake ” may have confused you, and you have some questions. Structuringdata refers to converting unstructured data into tables and defining data types and relationships based on a schema. What is DataWarehouse? .
“Data Lake vs DataWarehouse = Load First, Think Later vs Think First, Load Later” The terms data lake and datawarehouse are frequently stumbled upon when it comes to storing large volumes of data. DataWarehouseArchitecture What is a Data lake?
As data volumes increase, fetching insights from this data comes with its challenges. Sure, you can use lakes and marts to dump any data, but ultimately, deriving business insights requires structureddata with a faster querying experience. This raises the need for […]
Major datawarehouse providers (Snowflake, Databricks) have released their flavors of REST catalogs, leading to compatibility issues and potential vendor lock-in. Start the Data Governance Process: Don't wait until the last minute to build the data governance framework.
Data pipelines are the backbone of your business’s dataarchitecture. Implementing a robust and scalable pipeline ensures you can effectively manage, analyze, and organize your growing data. Benjamin Kennedy, Cloud Solutions Architect at Striim, emphasizes the outcome-driven nature of data pipelines.
Data teams need to balance the need for robust, powerful data platforms with increasing scrutiny on costs. That’s why it’s essential for teams to choose the right architecture for the storage layer of their data stack. But, the options for data storage are evolving quickly. Let’s dive in.
As the demand for big data grows, an increasing number of businesses are turning to cloud datawarehouses. The cloud is the only platform to handle today's colossal data volumes because of its flexibility and scalability. Launched in 2014, Snowflake is one of the most popular cloud data solutions on the market.
The pun being obvious, there’s more to that than just a new term: Data lakehouses combine the best features of both data lakes and datawarehouses and this post will explain this all. What is a data lakehouse? Datawarehouse vs data lake vs data lakehouse: What’s the difference.
Summary Designing the structure for your datawarehouse is a complex and challenging process. As businesses deal with a growing number of sources and types of information that they need to integrate, they need a data modeling strategy that provides them with flexibility and speed.
In this episode he shares the goals of the Unstruk DataWarehouse, how it is architected to extract asset metadata and build a searchable knowledge graph from the information, and the myriad ways that the system can be used. Are you bored with writing scripts to move data into SaaS tools like Salesforce, Marketo, or Facebook Ads?
How could Matthew serve all this data, together , in an easily consumable way, without losing focus on his core business: finding a cure for cancer. The Vision of a Discovery DataWarehouse. A Discovery DataWarehouse is cloud-agnostic. Access to valuable data should not be hindered by the technology.
A data ingestion architecture is the technical blueprint that ensures that every pulse of your organization’s data ecosystem brings critical information to where it’s needed most. Data Transformation : Clean, format, and convert extracted data to ensure consistency and usability for both batch and real-time processing.
It also came with other advantages such as independence of cloud infrastructure providers, data recovery features such as Time Travel , and zero copy cloning which made setting up several environments — such as dev, stage or production — way more efficient.
Prior to data powering valuable data products like machine learning models and real-time marketing applications, datawarehouses were mainly used to create charts in binders that sat off to the side of board meetings. The most common themes: Data readiness- You cant have good AI with bad data.
Data lakes emerged as expansive reservoirs where raw data in its most natural state could commingle freely, offering unprecedented flexibility and scalability. This article explains what a data lake is, its architecture, and diverse use cases. Datawarehouse vs. data lake in a nutshell.
In this post, we will help you quickly level up your overall knowledge of data pipeline architecture by reviewing: Table of Contents What is data pipeline architecture? Why is data pipeline architecture important? What is data pipeline architecture? Why is data pipeline architecture important?
Data pipelines are a significant part of the big data domain, and every professional working or willing to work in this field must have extensive knowledge of them. As data is expanding exponentially, organizations struggle to harness digital information's power for different business use cases. What is a Big Data Pipeline?
In the last few decades, we’ve seen a lot of architectural approaches to building data pipelines , changing one another and promising better and easier ways of deriving insights from information. There have been relational databases, datawarehouses, data lakes, and even a combination of the latter two.
One of the innovative ways to address this problem is to build a data hub — a platform that unites all your information sources under a single umbrella. This article explains the main concepts of a data hub, its architecture, and how it differs from datawarehouses and data lakes. What is Data Hub?
The holistic view of Hadoop architecture gives prominence to Hadoop common, Hadoop YARN, Hadoop Distributed File Systems (HDFS ) and Hadoop MapReduce of the Hadoop Ecosystem. HDFS in Hadoop architecture provides high throughput access to application data and Hadoop MapReduce provides YARN based parallel processing of large data sets.
In this context, data management in an organization is a key point for the success of its projects involving data. One of the main aspects of correct data management is the definition of a dataarchitecture. The Lakehouse architecture was one of them. What is Delta Lake?
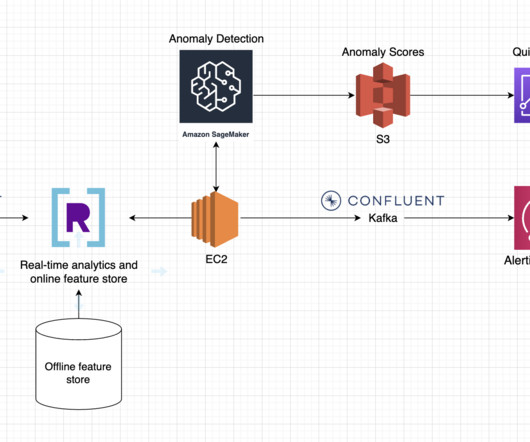
We’ve noticed many common patterns across streaming dataarchitectures and we’ll be sharing a blueprint for three of the most popular: anomaly detection, IoT, and recommendations. The majority of anomaly detectors require streaming data, real-time data and historical data in order to generate inferences.
In this post, we’ll attempt to explain the idea behind a data fabric, its architectural building blocks, the benefits it brings, and ways to approach its implementation. What is data fabric? to provide a unified view of all enterprise data. Data fabric architecture example. Data fabric vs data mesh.
A 2016 data science report from data enrichment platform CrowdFlower found that data scientists spend around 80% of their time in data preparation (collecting, cleaning, and organizing of data) before they can even begin to build machine learning (ML) models to deliver business value. Enter Snowpark !
When it comes to the question of building or buying your data stack, there’s never a one-size-fits-all solution for every data team—or every component of your data stack. Data storage and compute are very much the foundation of your data platform. Let’s jump in! So, let’s take a look at each in a bit more detail.
Now let’s think of sweets as the data required for your company’s daily operations. Instead of combing through the vast amounts of all organizational data stored in a datawarehouse, you can use a data mart — a repository that makes specific pieces of data available quickly to any given business unit.
First, organizations have a tough time getting their arms around their data. More data is generated in ever wider varieties and in ever more locations. Organizations don’t know what they have anymore and so can’t fully capitalize on it — the majority of data generated goes unused in decision making. Unified data fabric.
One reason for this is that dependencies usually exist outside of the marketing team, such as marketing ops serving as a liaison, and marketing campaign teams are the “consumer” in the integration/modeling/datawarehouse activities. And while data platforms have emerged to better handle data, there are lessons to be learned as well.
As the volume and complexity of data continue to grow, organizations seek faster, more efficient, and cost-effective ways to manage and analyze data. In recent years, cloud-based datawarehouses have revolutionized data processing with their advanced massively parallel processing (MPP) capabilities and SQL support.
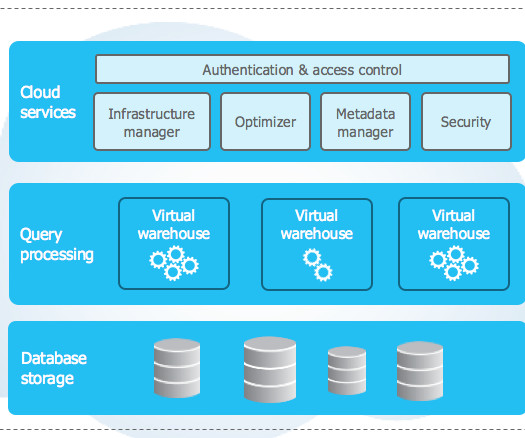
Snowflake Overview A datawarehouse is a critical part of any business organization. Lot of cloud-based datawarehouses are available in the market today, out of which let us focus on Snowflake. Snowflake is an analytical datawarehouse that is provided as Software-as-a-Service (SaaS).
With so much riding on the efficiency of ETL processes for data engineering teams, it is essential to take a deep dive into the complex world of ETL on AWS to take your data management to the next level. Data integration with ETL has changed in the last three decades. But cloud computing is preferred over the other.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content