This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It addresses many of Kafka's challenges in analytical infrastructure. The combination of Kafka and Flink is not a perfect fit for real-time analytics; the integration of Kafka and Lakehouse is very shallow. How do you compare Fluss with Apache Kafka? Fluss and Kafka differ fundamentally in design principles.
They’re basically architectural blueprints for moving and processing your data. LambdaArchitecture Pattern 4. Kappa Architecture Pattern 5. LambdaArchitecture Pattern Here’s where things get interesting. That’s where data pipeline design patterns come in. Batch Processing Pattern 2.
Aggregator Leaf Tailer (ALT) is the data architecture favored by web-scale companies, like Facebook, LinkedIn, and Google, for its efficiency and scalability. In this blog post, I will describe the Aggregator Leaf Tailer architecture and its advantages for low-latency data processing and analytics.
How does it compare with systems such as Kafka and Pulsar for ingesting and persisting unbounded data? For someone who wants to build an application on top of Pravega, what interfaces does it provide and what architectural patterns does it lend itself toward? Can you start by explaining what Pravega is and the story behind it?
How have projects such as Kafka and Pulsar impacted the broader software and data landscape? How have projects such as Kafka and Pulsar impacted the broader software and data landscape? What motivates you to dedicate so much of your time and enery to Pulsar in particular, and the streaming data ecosystem in general?
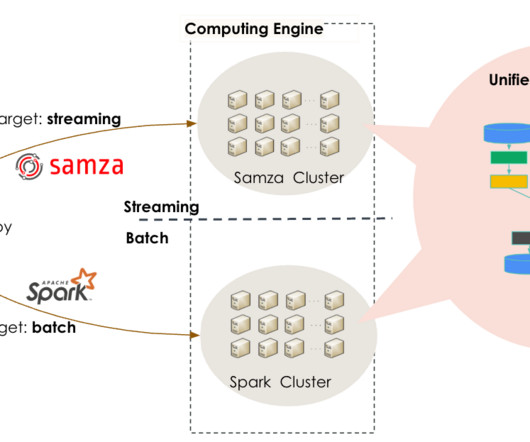
In 2010, they introduced Apache Kafka , a pivotal Big Data ingestion backbone for LinkedIn’s real-time infrastructure. To transition from batch-oriented processing and respond to Kafka events within minutes or seconds, they built an in-house distributed event streaming framework, Apache Samza.
Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java.
In the past, we often used lambdaarchitecture for processing jobs, meaning that our developers used two different systems for batch and stream processing. Architecture With our new architecture (as shown in Figure 3), developers only need to develop and maintain a single codebase written in Beam.
Data streamed in is queryable in conjunction with historical data, avoiding need for LambdaArchitecture. Figure 1 below shows a standard architecture for a Real-Time Data Warehouse. Basic Architecture for Real-Time Data Warehousing. Architecture for Real-Time Data Warehousing with Extended Capabilities.
🤺🤺🤺🤺🤺🤺 [link] LinkedIn: Unified Streaming And Batch Pipelines At LinkedIn: Reducing Processing time by 94% with Apache Beam One of the curses of adopting LambdaArchitecture is the need for rewriting business logic in both streaming and batch pipelines.
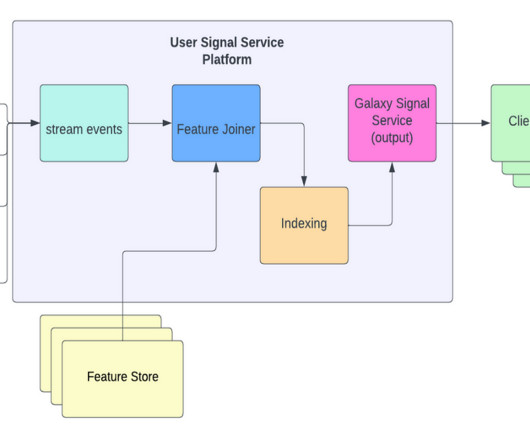
So our user sequence real-time indexing pipeline is composed of a Flink job that reads the relevant events as they come into our Kafka streams, fetches the desired features for each event from our feature services, and stores the enriched events into our KV store system.
Organizations build data ingestion architecture to make sense of the complexity in the data and derive more value from it. A Data ingestion pipeline could be grouped under several types: Batch architecture: In this system, the raw data from various sources is collected in batches and moved to a target location.
It talks about how to get adoption in your organization, a sample implementation, and the contract-driven architecture. Architectural patterns like LambdaArchitecture and Kappa Architecture emerged to bridge the gap between real-time and batch data processing. Each architectural pattern has its limitation.
Top 20+ Data Engineering Projects Ideas for Beginners with Source Code [2023] We recommend over 20 top data engineering project ideas with an easily understandable architectural workflow covering most industry-required data engineer skills. This big data project discusses IoT architecture with a sample use case.
Also worth noting is lambdaarchitecture-based data ingestion which is a hybrid model that combines features of both streaming and batch data ingestion. Parallel architectures Streaming and batch processing often require different data pipeline architectures. Table of Contents What is Data Ingestion?
Spark streaming also has in-built connectors for Apache Kafka which comes very handy while developing Streaming applications. The order management system pushes the order status to the queue(could be Kafka) from where Streaming process reads every minute and picks all the orders with their status.
Join Live Session LinkedIn: Unified Streaming And Batch Pipelines At LinkedIn: Reducing Processing time by 94% with Apache Beam One of the curses of adopting LambdaArchitecture is the need for rewriting business logic in both streaming and batch pipelines.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content