This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
They’re basically architectural blueprints for moving and processing your data. LambdaArchitecture Pattern 4. Kappa Architecture Pattern 5. LambdaArchitecture Pattern Here’s where things get interesting. That’s where data pipeline design patterns come in. Batch Processing Pattern 2.
Aggregator Leaf Tailer (ALT) is the data architecture favored by web-scale companies, like Facebook, LinkedIn, and Google, for its efficiency and scalability. In this blog post, I will describe the Aggregator Leaf Tailer architecture and its advantages for low-latency data processing and analytics.
Architecture Difference The first difference is the Data Model. The fourth difference is the Lakehouse Architecture. Fluss embraces the Lakehouse Architecture. On the other hand, Fluss is a Kappa Architecture ; it stores one copy of data and presents it as a stream or a table, depending on the use case.
What are the prevailing architectural and technological patterns that are being used to manage these systems? The Lambdaarchitecture has largely been abandoned, so what is the answer for today’s data lakes? What are the most interesting, innovative, or unexpected ways that you have seen streaming architectures used?
For someone who wants to build an application on top of Pravega, what interfaces does it provide and what architectural patterns does it lend itself toward? For someone who wants to build an application on top of Pravega, what interfaces does it provide and what architectural patterns does it lend itself toward?
In this 30 minute video overview, CTO and Rockset Co-founder Dhruba Borthakur discusses Rockset's ALT architecture , how data is ingested, stored and queried in Rockset, and why Rockset is simple to use, incredibly fast, and capable of the highly efficient execution of complex distributed queries across diverse data sets.
Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java.
Here is an illustration to provide you with a similar idea between the trigger and the semantics in LambdaArchitecture Image created by the author. It is also the mode used in LambdaArchitecture systems, where the streaming pipeline outputs low-latency results, which are then overwritten later by the results from the batch pipeline.
Links Fundamentals of Data Engineering (affiliate link) Ternary Data Designing Data Intensive Applications James Webb Space Telescope Google Colossus Storage System DMBoK == Data Management Body of Knowledge DAMA Bill Inmon Apache Druid RTFM == Read The Fine Manual DuckDB Podcast Episode VisiCalc Ternary Data Newsletter Meroxa Podcast Episode Ruby (..)
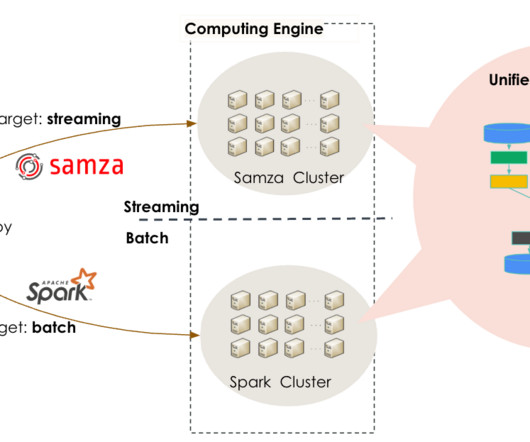
In the past, we often used lambdaarchitecture for processing jobs, meaning that our developers used two different systems for batch and stream processing. Architecture With our new architecture (as shown in Figure 3), developers only need to develop and maintain a single codebase written in Beam.
Without a well-planned architecture, these pipelines can quickly become unmanageable, often reaching a point where efficiency and transparency take a backseat, leading to operational chaos. Let’s dive into the world of data pipeline architecture. What Is Data Pipeline Architecture? That’s where we step in.
LambdaArchitecture Event Sourcing WebAssembly Apache Flink Podcast Episode Pulsar Summit The intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA Support Data Engineering Podcast
LinkedIn team decided to migrate to a lambdaarchitecture and got 94% uplift in performance. How LinkedIn reduced processing time with Apache Beam — Beam is a distributed processing framework that proposes a unified execution engine for batch and real-time. How fast is DuckDB really?
Coming up this fall is the combined events of Graphorum and the Data Architecture Summit. The Lambdaarchitecture was popular in the early days of Hadoop but seems to have fallen out of favor. Coming up this fall is the combined events of Graphorum and the Data Architecture Summit.
This framework, along with Apache Spark for batch processing, formed the basis of LinkedIn’s lambdaarchitecture for data processing jobs. The lambdaarchitecture approach led to operational complexity and inefficiencies, because it required maintaining two different codebases and two different engines for batch and streaming data.
Data streamed in is queryable in conjunction with historical data, avoiding need for LambdaArchitecture. Figure 1 below shows a standard architecture for a Real-Time Data Warehouse. Basic Architecture for Real-Time Data Warehousing. Architecture for Real-Time Data Warehousing with Extended Capabilities.
For future work, we are looking into both more efficient and scalable data storage solutions, such as event compression or online-offline lambdaarchitecture, as well as more scalable online model inference capability integrated into the streaming platform.
Organizations build data ingestion architecture to make sense of the complexity in the data and derive more value from it. A Data ingestion pipeline could be grouped under several types: Batch architecture: In this system, the raw data from various sources is collected in batches and moved to a target location.
LambdaArchitecture: Too Many Compromises A decade ago, a multitiered database architecture called Lambda began to emerge. Lambda systems try to accommodate the needs of both big data-focused data scientists as well as streaming-focused developers by separating data ingestion into two layers.
🤺🤺🤺🤺🤺🤺 [link] LinkedIn: Unified Streaming And Batch Pipelines At LinkedIn: Reducing Processing time by 94% with Apache Beam One of the curses of adopting LambdaArchitecture is the need for rewriting business logic in both streaming and batch pipelines.
Lambda views are a simple and readily available solution that is tool agnostic and SQL based. What are lambda views? The idea of lambda views comes from lambdaarchitecture. Drew and I had a brainstorming session to discuss lambdaarchitecture and the initial concept of lambda views.
It talks about how to get adoption in your organization, a sample implementation, and the contract-driven architecture. Architectural patterns like LambdaArchitecture and Kappa Architecture emerged to bridge the gap between real-time and batch data processing. Each architectural pattern has its limitation.
Also worth noting is lambdaarchitecture-based data ingestion which is a hybrid model that combines features of both streaming and batch data ingestion. Parallel architectures Streaming and batch processing often require different data pipeline architectures. Table of Contents What is Data Ingestion?
Top 20+ Data Engineering Projects Ideas for Beginners with Source Code [2023] We recommend over 20 top data engineering project ideas with an easily understandable architectural workflow covering most industry-required data engineer skills. This big data project discusses IoT architecture with a sample use case.
It can solve problems related to batch processing, near real-time processing, can be used to apply lambdaarchitecture, can be used for Structured streaming. Conclusion Apache Spark has capabilities to process huge amount of data in a very efficient manner with high throughput.
Join Live Session LinkedIn: Unified Streaming And Batch Pipelines At LinkedIn: Reducing Processing time by 94% with Apache Beam One of the curses of adopting LambdaArchitecture is the need for rewriting business logic in both streaming and batch pipelines.
This project is a LambdaArchitecture program that tracks Chicago's streets' traffic conditions, including congestion and safety. There are many uses and benefits for real-time traffic simulation and prediction projects using big data. Simulating real-time traffic has successfully been modeled.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content