This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ERP and CRM systems are designed and built to fulfil a broad range of business processes and functions. This generalisation makes their data models complex and cryptic and require domain expertise. As you do not want to start your development with uncertainty, you decide to go for the operational raw data directly.
With the trending advance of IoT in every facet of life, technology has enabled us to handle a large amount of data ingested with high velocity. This big data project discusses IoT architecture with a sample use case. S3 is an object storage service provided by AWS that allows data to be stored and retrieved from anywhere on the web.
Refining data through data warehousing tools enables organizations to extract valuable insights, recognize trends, and make informed decisions, much like refining turns crude oil into valuable products that power our world. So, read on to discover these essential tools for your data management needs.
Data quality can be influenced by various factors, such as data collection methods, data entry processes, data storage, and data integration. Maintaining high data quality is crucial for organizations to gain valuable insights, make informed decisions, and achieve their goals.
“Observability” has become a bit of a buzzword so it’s probably best to define it: Data observability is the blanket term for monitoring and improving the health of data within applications and systems like data pipelines. Data observability vs. monitoring: what is the difference?
If you're aspiring to be a data engineer and seeking to showcase your skills or gain hands-on experience, you've landed in the right spot. Get ready to delve into fascinating data engineering project concepts and explore a world of exciting data engineering projects in this article.
As we move firmly into the data cloud era, data leaders need metrics for the robustness and reliability of the machine–the data pipelines, systems, and engineers–just as much as the final (data) product it spits out. The next step is to assess the overall performance of your systems and team.
The importance of data quality cannot be overstated, as poor-quality data can result in incorrect conclusions, inefficient operations, and a lack of trust in the information provided by a company’s systems. Completeness: The extent that all required data is present and available.
Spark Streaming Kafka Streams 1 Data received from live input data streams is Divided into Micro-batched for processing. processes per data stream(real real-time) 2 A separate processing Cluster is required No separate processing cluster is required. it's better for functions like row parsing, datacleansing, etc.
Eric Jones June 21, 2023 What Are Data Integrity Tools? Data integrity tools are software applications or systems designed to ensure the accuracy, consistency, and reliability of data stored in databases, spreadsheets, or other data storage systems. In this article: Why Are Data Integrity Tools Important?
Although both Data Science and Software Engineering domains focus on math, code, data, etc., Is mastering data science beneficial or building software is a better career option? This field uses several scientific procedures to understand structured, semi-structured, and unstructured data.
Besides these categories, specialized solutions tailored specifically for particular domains or use cases also exist, such as ETL (Extract-Transform-Load) tools for managing data pipelines, data integration tools for combining information from disparate sources/systems, and more.
They can handle various data types, including structured and unstructured data, and can be deployed on-premises or in the cloud, depending on organizational needs and preferences. In this article: Why Do You Need a Data Quality Platform?
The ELT process relies heavily on the power and scalability of modern data storage systems. By loading the data before transforming it, ELT takes full advantage of the computational power of these systems. This approach allows for faster data processing and more flexible data management compared to traditional methods.
There are various ways to ensure data accuracy. Data validation involves checking data for errors, inconsistencies, and inaccuracies, often using predefined rules or algorithms. Datacleansing involves identifying and correcting errors, inconsistencies, and inaccuracies in data sets.
Niv Sluzki June 20, 2023 What Is Data Integrity? Data integrity refers to the overall accuracy, consistency, and reliability of data stored in a database, data warehouse, or any other information storage system. 4 Ways to Prevent and Resolve Data Integrity Issues 1.
This data cannot be directly consumed for analysis. There are different data-cleaning steps in data science that one must go through to ensure the data is validated and ready for analysis. Each stage in a data pipeline consumes input and produces output. To fix them, we need to first get the data understanding.
DataOps tools can be categorized into several types, including data integration tools, data quality tools, data catalog tools, data orchestration tools, and data monitoring tools. In this article: Why Are DataOps Tools Important? This allows it to be easily integrated with other services and systems.
Whether it is intended for analytics purposes, application development, or machine learning, the aim of data ingestion is to ensure that data is accurate, consistent, and ready to be utilized. It is a crucial step in the data processing pipeline, and without it, we’d be lost in a sea of unusable data.
Data Consistency vs Data Integrity: Similarities and Differences Joseph Arnold August 30, 2023 What Is Data Consistency? Data consistency refers to the state of data in which all copies or instances are the same across all systems and databases.
Besides these categories, specialized solutions tailored specifically for particular domains or use cases also exist, such as extract, transform and load (ETL) tools for managing data pipelines, data integration tools for combining information from disparate sources or systems and more.
In order to develop a successful data quality strategy, you will need to understand how high-quality information supports decision-making processes and drives growth across your organization, and what factors can impact or reduce data quality. Data profiling: Regularly analyze dataset content to identify inconsistencies or errors.
AI can help improve prediction accuracy by analyzing large data sets and identifying patterns humans may miss. In addition to these two examples, AI can also help to improve the efficiency of other data management activities such as datacleansing, classification, and security. Intelligent Automation .
Yet, looking into the complexities of today’s data-driven world, it becomes clear that ELT, while transformative at its inception, now forms just a part of an ever-evolving data landscape. This article revisits the foundational elements of ELT, exploring what it is, how it reshaped data strategies, and how it works.
Accelerated Digital & Data Transformation : According to industry reports, a substantial number of teams report being over capacity, with many spending over 50% of their time just maintaining existing systems and with little time to truly modernize their data ecosystem. The post Wizeline and Ascend.io
It encompasses the systems, tools, and processes that enable businesses to manage their data more efficiently and effectively. These systems typically consist of siloed data storage and processing environments, with manual processes and limited collaboration between teams.
As we move firmly into the data cloud era, data leaders need metrics for the robustness and reliability of the machine–the data pipelines, systems, and engineers–just as much as the final (data) product it spits out. The next step is to assess the overall performance of your systems and team.
Whether it's aggregating customer interactions, analyzing historical sales trends, or processing real-time sensor data, data extraction initiates the process. Utilizes structured data or datasets that may have already undergone extraction and preparation. Primary Focus Structuring and preparing data for further analysis.
While data engineering and Artificial Intelligence (AI) may seem like distinct fields at first glance, their symbiosis is undeniable. The foundation of any AI system is high-quality data. Here lies the critical role of data engineering: preparing and managing data to feed AI models.
Businesses and groups gather enormous amounts of data from a variety of sources, including social media, customer databases, transactional systems, and many more. in today's data-driven world, Consolidating, processing, and making meaning of this data in order to derive insights that can guide decision-making is the difficult part.
If you are also indecisive about which field to pursue, this article will assist you in discovering the best career options. The educational requirement for the field of Data Science is preferably a B.E/B.Tech Full Stack Software Developer Full-stack software engineers are familiar with database systems.
NLG can be used to generate content for various applications, including chatbots and automated documents like reports and articles. . Examples are Customer complaints processing, Datacleansing, Compliance reporting, etc. . A cyber defense system detects, repairs, and mitigates attacks against systems and data infrastructure.
Data Science is an interdisciplinary field that blends programming skills, domain knowledge, reasoning skills, mathematical and statistical skills to generate value from a large pool of data. The first step is capturing data, extracting it periodically, and adding it to the pipeline. Data Science salary.
By automating repetitive tasks and processes, data teams can focus on higher-value activities, such as developing new insights and strategies to drive business growth. This involves the implementation of processes and controls that help ensure the accuracy, completeness, and consistency of data.
2) Your Data Analytics Projects for Portfolio Understanding a business problem, extracting data with SQL, datacleansing and validation using Python or R , and lastly, visualizing the insights for successful business choices are all part of a data analyst's job description.
The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. This article explains what a data lake is, its architecture, and diverse use cases. Who needs a data lake?
Data cleaning is the process of identifying and correcting inaccurate, incomplete, or inconsistent data in a dataset. The data cleaning process can be done manually by humans or automated with tools. Automated systems can be useful if they produce sufficient quality work under normal conditions. .
Integrating data from numerous, disjointed sources and processing it to provide context provides both opportunities and challenges. One of the ways to overcome challenges and gain more opportunities in terms of data integration is to build an ELT (Extract, Load, Transform) pipeline. Partial data extraction with update notifications.
A DBA typically works with database management systems (DBMS) to ensure that data is properly stored, organized, and secured. This can include everything from operating systems and applications to middleware and security updates. They ensure that the data is accurate, consistent, and available when needed. Conclusion .
Organizations are utilizing the enormous potential of big data to help them succeed, from consumer insights that enable personalized experiences to operational efficiency that simplifies procedures. How does big data actually make it happen? Go for the best Big Data courses and work on ral-life projects with actual datasets.
Data accuracy is an absolute necessity for today’s companies—and it’s becoming all the more essential as a growing volume of data flows through any given organization. In this article, we’ll highlight how to determine data accuracy, share examples of inaccurate data, and walk through common impediments to achieving more accurate data.
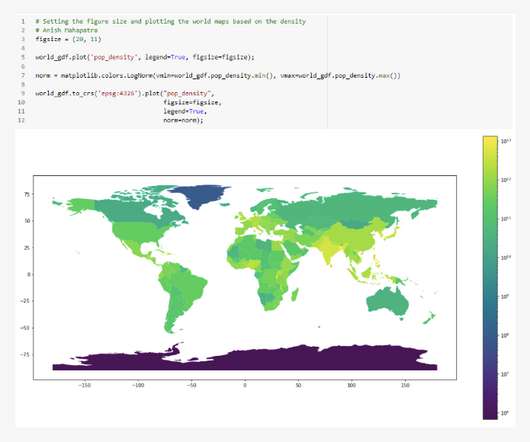
Spatial data is any form of data that helps us directly or indirectly reference a specific location or geographical area on the surface of the earth or elsewhere. Geographic Information systems, or GIS, is the most common method of processing and analyzing spatial data.
With the trending advance of IoT in every facet of life, technology has enabled us to handle a large amount of data ingested with high velocity. This big data project discusses IoT architecture with a sample use case. Finally, this data is used to create KPIs and visualize them using Tableau.
More solutions and services are becoming available, so if you haven’t established a data governance framework yet, now is the perfect time. In this article, we will explore what data governance is, the key components of a data governance framework, and best practices for implementing a successful data governance strategy.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content