This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this article, you will explore one such exciting solution for handling data in a better manner through AWS Athena , a serverless and low-maintenance tool for simplifying data analysis tasks with the help of simple SQL commands. What is AWS Athena?, How to write an AWS Athena query?
Jia Zhan, Senior Staff Software Engineer, Pinterest Sachin Holla, Principal Solution Architect, AWS Summary Pinterest is a visual search engine and powers over 550 million monthly active users globally. Pinterests infrastructure runs on AWS and leverages Amazon EC2 instances for its compute fleet. 4xl with up to 12.5 4xl with up to 12.5
Do ETL and data integration activities seem complex to you? AWS Glue is here to put an end to all your worries! Read this blog to understand everything about AWS Glue that makes it one of the most popular data integration solutions in the industry. Did you know the global big data market will likely reach $268.4
Ready to apply your AWS DevOps knowledge to real-world challenges? Dive into these exciting AWS DevOps project ideas that can help you gain hands-on experience in the big data industry! With this rapid growth of the DevOps market, most cloud computing providers, such as AWS, Azure , etc., billion in 2023 to USD 25.5
This blog presents some of the most unique and exciting AWS projects from beginner to advanced levels. These AWS project ideas will provide you with a better understanding of various AWS tools and their business applications. You can work on these AWS sample projects to expand your skills and knowledge.
Becoming a successful awsdata engineer demands you to learn AWS for data engineering and leverage its various services for building efficient business applications. Amazon Web Services, or AWS, remains among the Top cloud computing services platforms with a 34% market share as of 2022. What is Data Engineering??
If you are about to start your journey in data analytics or are simply looking to enhance your existing skills, look no further. This blog will provide you with valuable insights, exam preparation tips, and a step-by-step roadmap to ace the AWSData Analyst Certification exam.
Experience with using cloud services providing platforms like AWS/GCP/Azure. Knowledge of popular big data tools like Apache Spark, Apache Hadoop, etc. Learning Resources: How to Become a GCP Data Engineer How to Become a Azure Data Engineer How to Become a AwsData Engineer 6. Similar pricing as AWS.
The AWS Big Data Analytics Certification exam holds immense significance for professionals aspiring to demonstrate their expertise in designing and implementing big data solutions on the AWS platform. In this blog, we will dive deep into the details of AWS Big Data Certification.
Data professionals who work with raw data, like data engineers, data analysts, machine learning scientists , and machine learning engineers , also play a crucial role in any data science project. Build your Data Engineer Portfolio with ProjectPro!
That’s where AWS Cloudwatch comes into picture. AWS CloudWatch is the ideal monitoring and logging tool for all your data, applications, and resources deployed on AWS or any other platform! AWS CloudWatch seamlessly integrates with over 70 AWS services for efficient monitoring and scalability.
Data Engineering Weekly recently published a reference architecture for a composable data architecture. The author further highlights why hyperscalers like AWS, Azure, and Cloudflare offer managed Iceberg services. The blog narrates adopting a hybrid approach with AWS Sagemaker integration and Chalk feature store.
Are you looking to prepare for AWS Machine Learning Certification? Check out this blog that features an expertly curated roadmap designed to equip you with the skills and knowledge needed to excel in this dynamic field. AWS Machine Learning Specialty Certification gives you the knowledge to turn your wildest imaginations into reality.
Explore the world of data analytics with the top AWS databases! Check out this blog to discover your ideal database and uncover the power of scalable and efficient solutions for all your data analytical requirements. Let’s understand more about AWS Databases in the following section.
It requires a skillful blend of data engineering expertise and the strategic use of tools designed to streamline this process. That’s where data pipeline tools come in. This blog is all about that—specifically, the top 10 data pipeline tools that data engineers worldwide rely on.
I can now begin drafting my dataingestion/ streaming pipeline without being overwhelmed. The remaining tech (stages 3, 4, 7 and 8) are all AWS technologies. What's Next I'll be documenting how I build this setup in the AWS console (with screenshots).
In this blog, we will break down the fundamentals of RAG architecture, offering clear insights into its components and real-world applications by tech giants like Google, Amazon, Azure, and others. Data is initially ingested from Amazon S3, transformed into embeddings by the model, and stored in a vector database.
Check out the highlights shared by Ritesh Shergill, who is a seasoned professional with a background in cybersecurity and software architecture on choosing the right data warehouse. He emphasizes on the relevance of AWS Redshift for AWS Users while acknowledging the growing popularity of BigQuery and Snowflake.
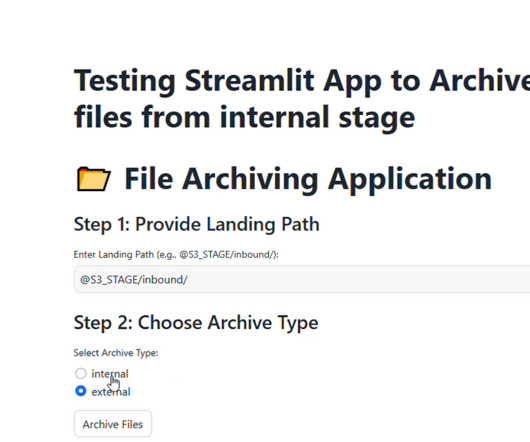
Handling feed files in data pipelines is a critical task for many organizations. These files, often stored in stages such as Amazon S3 or Snowflake internal stages, are the backbone of dataingestion workflows. Without a proper archival strategy, these files can clutter staging areas, leading to operational challenges.
Are you ready to step into the heart of big data projects and take control of data like a pro? Batch data pipelines are your ticket to the world of efficient data processing. These pipelines are the go-to solution for data engineers, and it's no secret why.
Data engineering is gradually becoming the backbone of companies looking forward to leveraging data to improve business processes. This blog will discover how Python has become an integral part of implementing data engineering methods by exploring how to use Python for data engineering.
This foundational layer is a repository for various data types, from transaction logs and sensor data to social media feeds and system logs. By storing data in its native state in cloud storage solutions such as AWS S3, Google Cloud Storage, or Azure ADLS, the Bronze layer preserves the full fidelity of the data.
This blog post provides an overview of the top 10 data engineering tools for building a robust data architecture to support smooth business operations. Table of Contents What are Data Engineering Tools? Dice Tech Jobs report 2020 indicates Data Engineering is one of the highest in-demand jobs worldwide.
Do ETL and data integration activities seem complex to you? AWS Glue is here to put an end to all your worries! Read this blog to understand everything about AWS Glue that makes it one of the most popular data integration solutions in the industry. Did you know the global big data market will likely reach $268.4
The blog took out the last edition’s recommendation on AI and summarized the current state of AI adoption in enterprises. The simplistic model expressed in the blog made it easy for me to reason about the transactional system design. The popularity also exposes its Achilles heel, the replication and network bottlenecks.
But at Snowflake, we’re committed to making the first step the easiest — with seamless, cost-effective dataingestion to help bring your workloads into the AI Data Cloud with ease. Like any first step, dataingestion is a critical foundational block. Ingestion with Snowflake should feel like a breeze.
Read Time: 2 Minute, 34 Second Introduction In modern data pipelines, especially in cloud data platforms like Snowflake, dataingestion from external systems such as AWS S3 is common. In this blog, we introduce a Snowpark-powered Data Validation Framework that: Dynamically reads data files (CSV) from an S3 stage.
According to Bill Gates, “The ability to analyze data in real-time is a game-changer for any business.” ” Thus, don't miss out on the opportunity to revolutionize your business with real-time data processing using Azure Stream Analytics.
AWS or Azure? With so many data engineering certifications available , choosing the right one can be a daunting task. They also demonstrate to potential employers that the individual possesses the skills and knowledge to create and implement business data strategies. Table of Contents Why Are Data Engineering Skills In Demand?
Learning Snowflake data Warehouse is like gaining a superpower for handling and analyzing data in the cloud. This blog is a definitive guide to mastering how to learn Snowflake data warehouse for all aspiring data engineers. That's exactly what Snowflake Data Warehouse enables you to do!
However, building and maintaining a scalable data science pipeline comes with challenges like data quality , integration complexity, scalability, and compliance with regulations like GDPR. Apache Kafka: Apache Kafka is a distributed streaming platform designed for building real-time data pipelines.
Read this blog till the end to learn everything you need to know about Airflow DAG. Let's consider an example of a data processing pipeline that involves ingestingdata from various sources, cleaning it, and then performing analysis. Apache Airflow DAGs are your one-stop solution!
In this blog, we'll explore some exciting machine learning case studies that showcase the potential of this powerful emerging technology. Data Scientists use machine learning algorithms to predict equipment failures in manufacturing, improve cancer diagnoses in healthcare , and even detect fraudulent activity in 5.
Companies with expertise in Microsoft Fabric are in high demand, including Microsoft, Accenture, AWS, and Deloitte Are you prepared to influence the data-driven future? Let’s examine the requirements for becoming a Microsoft Fabric Engineer, starting with the knowledge and credentials discussed in this blog.
The Ascend Data Automation Cloud provides a unified platform for dataingestion, transformation, orchestration, and observability. Ascend automates workloads on Snowflake, Databricks, BigQuery, and open source Spark, and can be deployed in AWS, Azure, or GCP.
This certification program is designed to equip individuals with a strong foundation in big data engineering principles, techniques, and practices. It covers various aspects of big data, including dataingestion, storage, processing, and analysis.
Data pipelines are a significant part of the big data domain, and every professional working or willing to work in this field must have extensive knowledge of them. The Importance of a Data Pipeline What is an ETL Data Pipeline? What is a Big Data Pipeline?
In the previous blog post in this series, we walked through the steps for leveraging Deep Learning in your Cloudera Machine Learning (CML) projects. For AWS this means at least P3 instances. DataIngestion. The raw data is in a series of CSV files. Introduction. P2 GPU instances are not supported. Register Now. .
I'll try to think about it in the following weeks to understand where I go for the third year of the newsletter and the blog. AWS lambdas are still on Python 3.9 — Corey rant about AWS lambdas that are still using Python 3.9 So thank you for that. Stay tuned and let's jump to the content.
Integration of External Systems Fabric ensures seamless dataingestion from various sources by supporting connector-driven and API-based integration with external systems such as Salesforce, SAP, Dynamics 365, AWS, and more.
For organizations who are considering moving from a legacy data warehouse to Snowflake, are looking to learn more about how the AI Data Cloud can support legacy Hadoop use cases, or are struggling with a cloud data warehouse that just isn’t scaling anymore, it often helps to see how others have done it.
Extracting, transforming, and loading (ETL) data from their transactional databases into data warehouses like Redshift slowed their analytics, delaying crucial business decisions. Amazon introduced the Zero ETL concept at the AWS re: Invent 2022 conference to overcome these inefficiencies. Table of Contents What is Zero ETL?
In addition to big data workloads, Ozone is also fully integrated with authorization and data governance providers namely Apache Ranger & Apache Atlas in the CDP stack. While we walk through the steps one by one from dataingestion to analysis, we will also demonstrate how Ozone can serve as an ‘S3’ compatible object store.
Due to this, knowledge of cloud computing platforms and tools is now essential for data engineers working with big data. Depending on the demands for data storage, businesses can use internal, public, or hybrid cloud infrastructure, including AWS , Azure , GCP , and other popular cloud computing platforms.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content