This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Prior the introduction of CDP Public Cloud, many organizations that wanted to leverage CDH, HDP or any other on-prem Hadoop runtime in the public cloud had to deploy the platform in a lift-and-shift fashion, commonly known as “Hadoop-on-IaaS” or simply the IaaS model. Introduction. 1 Year Reserved . 13,000-18,500. 7,500-11,500.
In this post, we focus on how we enhanced and extended Monarch , Pinterest’s Hadoop based batch processing system, with FGAC capabilities. We discussed our project with technical contacts at AWS and brainstormed approaches, looking at alternate ways to grant access to data in S3.
Apache Ozone is compatible with Amazon S3 and Hadoop FileSystem protocols and provides bucket layouts that are optimized for both Object Store and File system semantics. This blog post is intended to provide guidance to Ozone administrators and application developers on the optimal usage of the bucket layouts for different applications.
This blog post describes the advantages of real-time ETL and how it increases the value gained from Snowflake implementations. If you have Snowflake or are considering it, now is the time to think about your ETL for Snowflake.
Ozone natively provides Amazon S3 and Hadoop Filesystem compatible endpoints in addition to its own native object store API endpoint and is designed to work seamlessly with enterprise scale data warehousing, machine learning and streaming workloads. Boto3 is the standard python client for the AWS SDK. Ozone Namespace Overview.
During Monarch’s inception in 2016, the most dominant batch processing technology around to build the platform was Apache Hadoop YARN. Now, eight years later, we have made the decision to move off of Apache Hadoop and onto our next generation Kubernetes (K8s) based platform. A major version upgrade to 3.x
In the data world Snowflake and Databricks are our dedicated platforms, we consider them big, but when we take the whole tech ecosystem they are (so) small: AWS revenue is $80b, Azure is $62b and GCP is $37b. That's what is Unity Catalog , AWS Glue Data Catalog , Polaris , Iceberg Rest Catalog and Tabular (RIP). Here we go again.
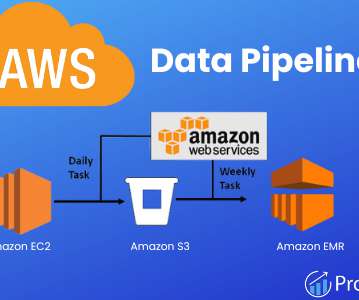
An AWS data pipeline helps businesses move and unify their data to support several data-driven initiatives. Amazon Web Services (AWS) offers an AWS Data Pipeline solution that helps businesses automate the transformation and movement of data. AWS CLI is an excellent tool for managing Amazon Web Services.
Contact Info @jgperrin on Twitter Blog Parting Question From your perspective, what is the biggest gap in the tooling or technology for data management today? Contact Info @jgperrin on Twitter Blog Parting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?
Contact Info Ajay @acoustik on Twitter LinkedIn Mike LinkedIn Website @michaelfreedman on Twitter Timescale Website Documentation Careers timescaledb on GitHub @timescaledb on Twitter Parting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?
In this blog post, we will look into benchmark test results measuring the performance of Apache Hadoop Teragen and a directory/file rename operation with Apache Ozone (native o3fs) vs. Ozone S3 API*. We ran Apache Hadoop Teragen benchmark tests in a conventional Hadoop stack consisting of YARN and HDFS side by side with Apache Ozone.
In this blog, we will discuss: What is the Open Table format (OTF)? The Hive format helped structure and partition data within the Hadoop ecosystem, but it had limitations in terms of flexibility and performance. Why should we use it? A Brief History of OTF A comparative study between the major OTFs. What is an Open Table Format?
It was designed as a native object store to provide extreme scale, performance, and reliability to handle multiple analytics workloads using either S3 API or the traditional Hadoop API. In this blog post, we will talk about a single Ozone cluster with the capabilities of both Hadoop Core File System (HCFS) and Object Store (like Amazon S3).
AWS has changed the life of data scientists by making all the data processing, gathering, and retrieving easy. One popular cloud computing service is AWS (Amazon Web Services). Many people are going for Data Science Courses in India to leverage the true power of AWS. What is Amazon Web Services (AWS)?
For organizations who are considering moving from a legacy data warehouse to Snowflake, are looking to learn more about how the AI Data Cloud can support legacy Hadoop use cases, or are struggling with a cloud data warehouse that just isn’t scaling anymore, it often helps to see how others have done it.
In this blog, we’ll share how CDP Operational Database can deliver high performance for your applications when running on AWS S3. One core component of CDP Operational Database, Apache HBase has been in the Hadoop ecosystem since 2008 and was optimised to run on HDFS. AWS EC2 instance configurations. Test Environment.
In this blog, we explore the evolution of our in-house batch processing infrastructure and how it helps Robinhood work smarter. Hadoop-Based Batch Processing Platform (V1) Initial Architecture In our early days of batch processing, we set out to optimize data handling for speed and enhance developer efficiency.
This blog post will present a simple “hello world” kind of example on how to get data that is stored in S3 indexed and served by an Apache Solr service hosted in a Data Discovery and Exploration cluster in CDP. We will only cover AWS and S3 environments in this blog. We will only cover AWS and S3 environments in this blog.
In this post, I’ll talk about why this is necessary and then show how to do it based on a couple of scenarios—Docker and AWS. AWS EC2) and on-premises machines locally (or even in another cloud). on AWS, etc.) Docker network, AWS VPC, etc.). We’ve got a broker on AWS. Is anyone listening? Brokers in the cloud (e.g.,
Most of the Data engineers working in the field enroll themselves in several other training programs to learn an outside skill, such as Hadoop or Big Data querying, alongside their Master's degree and PhDs. Data Engineers use the AWS platform to design the flow of data. Hadoop is the second most important skill for a Data engineer.
To help other people find the show please leave a review on iTunes and tell your friends and co-workers Join the community in the new Zulip chat workspace at dataengineeringpodcast.com/chat Links DataCoral Podcast Episode DataCoral Blog 3 Steps To Build A Modern Data Stack Change Data Capture: Overview Hive Hadoop DBT Podcast Episode FiveTran Podcast (..)
Read the complete blog below for a more detailed description of the vendors and their capabilities. Apache Oozie — An open-source workflow scheduler system to manage Apache Hadoop jobs. AWS Code Deploy. AWS Code Pipeline. AWS Code Commit – A fully-managed source control service that hosts secure Git-based repositories.
AWS vs. GCP blog compares the two major cloud platforms to help you choose the best one. So, are you ready to explore the differences between two cloud giants, AWS vs. google cloud? Amazon and Google are the big bulls in cloud technology, and the battle between AWS and GCP has been raging on for a while.
Ascend automates workloads on Snowflake, Databricks, BigQuery, and open source Spark, and can be deployed in AWS, Azure, or GCP. blog post SRE == Site Reliability Engineer Terraform Chef configuration management tool Puppet configuration management tool Ansible configuration management tool BigQuery Airflow Pulumi Podcast.
AWS (Amazon Web Services) is the world’s leading and widely used cloud platform, with over 200 fully featured services available from data centers worldwide. This blog presents some of the most unique and innovative AWS projects from beginner to advanced levels. Table of Contents What is AWS? Custom Alexa Skills 12.
” We hope that this blog post will solve all your queries related to crafting a winning LinkedIn profile. You will need a complete 100% LinkedIn profile overhaul to land a top gig as a Hadoop Developer , Hadoop Administrator, Data Scientist or any other big data job role. that are usually not present in a resume.
Support Kafka connectivity to HDFS, AWS S3 and Kafka Streams. The customer team included several Hadoop administrators, a program manager, a database administrator and an enterprise architect. The post Upgrade Journey: The Path from CDH to CDP Private Cloud appeared first on Cloudera Blog. Install documentation.
The blog further gives insight into IDE usage and documentation access. link] Dani: Apache Iceberg: The Hadoop of the Modern Data Stack? The comment on Iceber, a Hadoop of the modern data stack, surprises me. Along the line, AWS writes about implementing the WAP pattern leveraging Iceberg’s branching feature.
Apache HBase is a scalable, distributed, column-oriented data store that provides real-time read/write random access to very large datasets hosted on Hadoop Distributed File System (HDFS). to CDP Public Cloud on AWS. to CDP Public Cloud on AWS. to CDP Public Cloud on AWS and Azure. to CDP Public Cloud on AWS and Azure.
This is creating a huge job opportunity and there is an urgent requirement for the professionals to master Big Data Hadoop skills. Studies show, that by 2020, 80% of all Fortune 500 companies will have adopted Hadoop. Work on Interesting Big Data and Hadoop Projects to build an impressive project portfolio!
Figure 2: Access home directory contents in ADLS-Gen2 via Hadoop command-line. We hope this blog helped you understand the ADLS-Gen2 access control using Apache Ranger policies in Cloudera Data Platform. Stay tuned for more blogs that will cover the following topics: Apache Ranger fine-grained authorization for AWS-S3.
It serves as a foundation for the entire data management strategy and consists of multiple components including data pipelines; , on-premises and cloud storage facilities – data lakes , data warehouses , data hubs ;, data streaming and Big Data analytics solutions ( Hadoop , Spark , Kafka , etc.);
You can use different processing frameworks for different use-cases, for example, you can run Hive for SQL applications, Spark for in-memory applications, and Storm for streaming applications, all on the same Hadoop cluster. For the examples presented in this blog, we assume you have a CDP account already. Click Provision Cluster.
It’s also multi-cloud ready to meet your business where it is today, whether AWS, Microsoft Azure, or GCP. Test Environment: The performance comparison was done to measure the performance differences between COD using storage on Hadoop Distributed File System (HDFS) and COD using cloud storage. runtime version. CDH: 7.2.14.2
Many Cloudera customers are making the transition from being completely on-prem to cloud by either backing up their data in the cloud, or running multi-functional analytics on CDP Public cloud in AWS or Azure. Hadoop SQL Policies overview. This blog post is not a substitute for that. For context, the setup used is as follows.
We believe this has been validated by The Forrester Wave TM : Cloud Hadoop/ Spark Platforms, Q1 2019 report, which listed Cloudera and Hortonworks (more later about this) in the Leaders category. Download The Forrester Wave TM : Cloud Hadoop and Spark (HARK) report to see the complete breakdown of categories and scores.
COD enables customers to deliver prototypes within an hour in a cloud of your choice — AWS and Azure are generally available, GCP is available in Tech Preview — with the power to effortlessly scale to petabytes of data. It doesn’t require Hadoop admin expertise to set up the database.
In this comprehensive blog, we delve into the foundational aspects and intricacies of the machine learning landscape. Knowledge of C++ helps to improve the speed of the program, while Java is needed to work with Hadoop and Hive, and other tools that are essential for a machine learning engineer.
In this blog, we'll dive into some of the most commonly asked big data interview questions and provide concise and informative answers to help you ace your next big data job interview. Typically, data processing is done using frameworks such as Hadoop, Spark, MapReduce, Flink, and Pig, to mention a few. RDBMS stores structured data.
To make sense of it all, we utilise Hadoop (EMR) on AWS. While Hadoop is capable processing large amounts of data it typically works best with a small number of large files, and not with a large number of small files. A small file is one which is smaller than the Hadoop Distributed File System (HDFS) block size (default 64MB).
We’ll also need to support integration with AWS. You can use this link to find the correct aws-java-sdk-bundle for the version of Apache Spark you’re application is using. In my case, I needed aws-java-sdk-bundle 1.11.375 for Apache Spark 3.2.0. In another blog post, I’ll cover how to poll a collection.
This blog will guide you in creating an effective Azure Data Engineer resume that highlights your skills, experience and achievements in the field, and helps you stand out in a competitive job market. It can also be integrated with a variety of data storage systems, including Cassandra, Hadoop, and others.
Big Data Frameworks : Familiarity with popular Big Data frameworks such as Hadoop, Apache Spark, Apache Flink, or Kafka are the tools used for data processing. Cloud Computing : Knowledge of cloud platforms like AWS, Azure, or Google Cloud is essential as these are used by many organizations to deploy their big data solutions.
These tools include both open-source and commercial options, as well as offerings from major cloud providers like AWS, Azure, and Google Cloud. Data processing: Data engineers should know data processing frameworks like Apache Spark, Hadoop, or Kafka, which help process and analyze data at scale. What are Data Engineering Tools?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content