This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
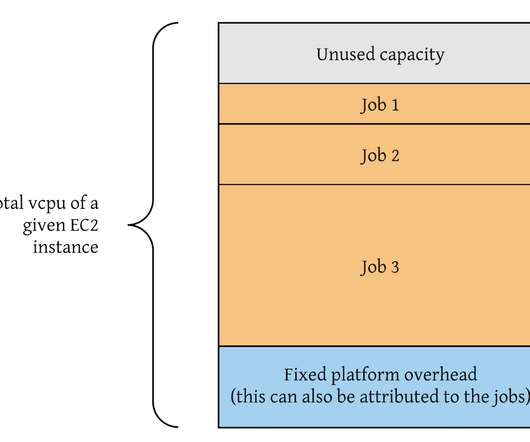
Jia Zhan, Senior Staff Software Engineer, Pinterest Sachin Holla, Principal Solution Architect, AWS Summary Pinterest is a visual search engine and powers over 550 million monthly active users globally. Pinterests infrastructure runs on AWS and leverages Amazon EC2 instances for its compute fleet. 4xl with up to 12.5 4xl with up to 12.5
After Zynga, he rejoined Amazon, and was the General Manager (GM) for Compute services at AWS, and later chief of staff, and advisor to AWS executives like Charlie Bell and Andy Jassy (Amazon’s current CEO.) The AWS re:invent conference in 2022 hosted a good in-depth overview of Amazon’s COE process.
Discover how AWS CloudFront is revolutionizing content delivery networks by offering rapid, secure, and scalable distribution of digital content across the globe. It’s because of AWS CloudFront, the secret behind lightning-fast and scalable content delivery. Table of Contents What is AWS CloudFront?
The AWS-Snowflake Partnership Snowflake is a cloud-native data warehousing platform for importing, analyzing, and reporting vast amounts of data first distributed on Amazon Web Services ( AWS ). You can deploy Snowflake environments directly from the AWS cloud for AWS users. It runs on AWS, Azure, and GCP.
Some excellent cloud data warehousing platforms are available in the market- AWS Redshift, Google BigQuery , Microsoft Azure , Snowflake , etc. Due to this, combining and contrasting the STRING and BYTE types is impossible. An OUT OF RANGE error is generated if a sequence of bytes contains more bytes than L.
Image from Unsplash Building a Semantic Book Search: Scale an Embedding Pipeline with Apache Spark and AWS EMR Serverless Using OpenAI’s Clip model to support natural language search on a collection of 70k book covers In a previous post I did a little PoC to see if I could use OpenAI’s Clip model to build a semantic book search.
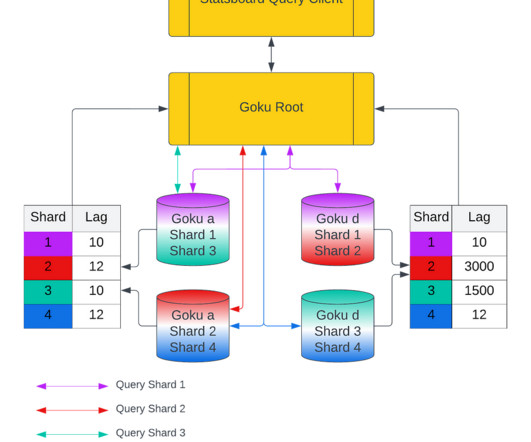
data before the last 2 hours, since GokuS allows only 2 hours of backfill old data in most cases), it stores a copy of the finalized data on AWS EFS (deep persistent storage). It also asynchronously logs the latest data points onto AWS EFS. Figure 10: compaction read and write bytes showing non zero values as soon as host starts up.
Security AWS and Amazon Redshift collaborate on security and are also in charge of ensuring the safety of the cloud. Google offers "on-demand pricing," where users are charged for each byte of requested and processed data; the first 1 TB of data per month is free. The hourly rate starts at $0.25 and increases from there.
rwxr-xr-x 1 jherland users 31560 Jan 1 00:00 hello.with-g We can see that the debug symbols add an extra (31560 - 8280 =) 23280 bytes (or almost 300%) to the final executable. gnu_debuglink ) has been added, and comparing the file sizes we see that this costs a modest 96 bytes. compared to hello.default ). What is removed?
Netflix operates in multiple AWS regions. That is, all mounted files that were opened and every single byte range read that MezzFS received. Finally, MezzFS will record various statistics about the mount, including: total bytes downloaded, total bytes read, total time spent reading, etc. Regional caching? —?Netflix
DMS AWS provides the Data Migration Service , which allows logical replication between a source and target Postgres DB. To overcome this issue, we opted instead for AWS Route53. As of October 2023, AWS now supports blue/green deployment for Aurora Postgres. The diff_bytes is 0 now!
AWS or Azure? Exabytes are 10006 bytes, so to put it into perspective, 463 exabytes is the same as 212,765,957 DVDs. This section mainly focuses on the three most valuable and popular vendor-specific data engineering certifications- AWS, Azure , and GCP. Cloudera or Databricks?
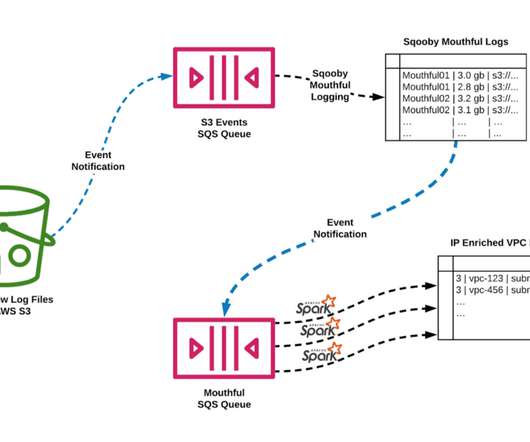
Direct communication in a flat network: Leveraging AWS-CNI , microservice pods in distinct clusters within a cell can communicate directly with each other. This led us to use a number of observability tools, including VPC flow logs , ebpf agent metrics , and Envoy networking bytes metrics to rectify the situation.
The index file keeps track of the physical location (URL) of each chunk and also keeps track of the physical location (URL + byte offset + size) of each video frame to facilitate downstream processing. What happens when the packager references bytes that have already been uploaded (e.g. when it updates the ‘mdat’ size)?
In this post, I’ll talk about why this is necessary and then show how to do it based on a couple of scenarios—Docker and AWS. AWS EC2) and on-premises machines locally (or even in another cloud). on AWS, etc.) Docker network, AWS VPC, etc.). We’ve got a broker on AWS. Is anyone listening? Brokers in the cloud (e.g.,
Along with enhancing your current skill set, the AWS Solutions Architect Associate certification can be your key to better job prospects and higher salaries. For that, you need to know the AWS Solutions Architect Associate cheat sheet. What is an AWS Solutions Architect Associate Cheat Sheet? Keep reading to learn more!
AWS, for example, offers services such as Amazon FSx and Amazon EFS for mirroring your data in a high-performance file system in the cloud. For this and all subsequent code snippets, we assume that your AWS account and local environment have been appropriately configured to access Amazon S3. client('s3') s3.upload_file('2GB.bin',
Capable of publishing events to a variety of different technologies, with arbitrary event transformations via AWS Lambda, these event streams form a core part of the Zalando infrastructure offering. At the time of writing, there are hundreds of these Postgres-sourced event streams out in the wild at Zalando.
Content Repository The Content Repository stores the actual content bytes of a given FlowFile. The default approach involves a persistent Write-Ahead Log on a specified disk partition. This repository ensures the resiliency and durability of FlowFile information.
Of course, a local Maven repository is not fit for real environments, but Gradle supports all major Maven repository servers, as well as AWS S3 and Google Cloud Storage as Maven artifact repositories. zip Zip file size: 3593 bytes, number of entries: 9 drwxr-xr-x 2.0 zip Zip file size: 3593 bytes, number of entries: 9 drwxr-xr-x 2.0
MEMORY ONLY SER: The RDD is stored as One Byte per partition serialized Java Objects. For data at rest, PySpark works with encrypted storage systems like HDFS and AWS S3. MEMORY ONLY SER: The RDD is stored as One Byte per partition serialized Java Objects. DISK ONLY: RDD partitions are only saved on disc.
Metadata for a file, block, or directory typically takes 150 bytes. This section covers the interview questions on big data based on various tools and languages, including Python, AWS, SQL, and Hadoop. How can AWS solve Big Data Challenges? AWS offers a wide range of solutions for all development and deployment needs.
Quotas are byte-rate thresholds that are defined per client-id. The process of converting the data into a stream of bytes for the purpose of the transmission is known as serialization. Deserialization is the process of converting the bytes of arrays into the desired data format. Assume your brokers are hosted on AWS EC2.
From startups to large enterprises to government agencies, AWS is used by millions of customers for powering their infrastructure at a lower cost. It is the fastest-growing service offered by the AWS. Along with AWS and EC2, Amazon Redshift involves deploying a cluster. Do You want to Get AWS Certified?
Industries generate 2,000,000,000,000,000,000 bytes of data across the globe in a single day. You must be aware of Amazon Web Services (AWS) and the data warehousing concept to effectively store the data sets. Most of these are performed by Data Engineers. Your organization will use internal and external sources to port the data.
Service Segmentation: The ease of the cloud deployments has led to the organic growth of multiple AWS accounts, deployment practices, interconnection practices, etc. VPC Flow Logs VPC Flow Logs is an AWS feature that captures information about the IP traffic going to and from network interfaces in a VPC. 43416 5001 52.213.180.42
Lack of Byte String Support : It is difficult to handle binary data efficiently. link] AWS: Build Write-Audit-Publish pattern with Apache Iceberg branching and AWS Glue Data Quality If you’ve not adopted the WAP (Write-Audit-Publish) pattern in your data pipeline, I highly recommend taking a deeper look at it.
Cloud services like AWS SageMaker or Google Colab Pro provide scalable GPU resources for high-performance training. For example, BERT uses WordPiece, while GPT uses byte pair encoding (BPE). Install libraries like torch, transformers , datasets, langchain , etc., for model development, pymupdf, PyPDF2, etc., for PDF processing.
This cluster can be from AWS / GCP / Azure cloud service or a Kubernetes cluster. Understanding the Python Ray Architecture Components of Ray Cluster Below are the key components of a Ray cluster- Cluster: The hardware on which Ray has a single head node and multiple worker nodes. Python driver is only on the head node.
Some excellent cloud data warehousing platforms are available in the market- AWS Redshift, Google BigQuery , Microsoft Azure , Snowflake , etc. Due to this, combining and contrasting the STRING and BYTE types is impossible. An OUT OF RANGE error is generated if a sequence of bytes contains more bytes than L.
jar Zip file size: 5849 bytes, number of entries: 5. jar Zip file size: 11405084 bytes, number of entries: 7422. It can then send that activity to cloud services like AWS Kinesis, Amazon S3, Cloud Pub/Sub, or Google Cloud Storage and a few JDBC sources. jar Archive: functions/build/libs/functions-1.0.0.jar
As a simple solution, files can be stored on cloud storage services, such as Azure Blob Storage or AWS S3, which can scale more easily than on-premises infrastructure. Whether displaying it on a screen or feeding it to a neural network, it is fundamental to have a tool to turn the stored bytes into a meaningful representation.
Datasets themselves are of varying size, from a few bytes to multiple gigabytes. Publishing Publishers generally use high-level APIs to publish strings, files, or byte arrays. For example, for some topics we roll out a new dataset version one AWS region at a time.
External DNS automatically configures the DNS name and the Kubernetes Ingress Controller for AWS configures the AWS ALB with the right ACM SSL certificate. ms , 38.382 ms , 59.958 ms , 244.094 ms Bytes In [ total, mean ] 51441000 , 17147.00 Bytes Out [ total, mean ] 0 , 0.00 s3-website.amazonaws.com.
When we enabled brotli in a straightforward manner, it reduced bytes sent as expected. In the end, we decided that the brotli treatment was better mainly on the basis of sending 10% fewer bytes over the wire. Does sending fewer bytes actually drive performance? In hindsight, there was a lot of evidence that I was wrong.
The AWS-Snowflake Partnership Snowflake is a cloud-native data warehousing platform for importing, analyzing, and reporting vast amounts of data first distributed on Amazon Web Services ( AWS ). You can deploy Snowflake environments directly from the AWS cloud for AWS users. It runs on AWS, Azure, and GCP.
As the only data observability platform to provide full visibility into delta tables With our delta lake integration, Monte Carlo supports all delta tables across all metastores and all three major platform providers including Microsoft Azure, AWS and Google Cloud.
AWS or Azure? Exabytes are 10006 bytes, so to put it into perspective, 463 exabytes is the same as 212,765,957 DVDs. This section mainly focuses on the three most valuable and popular vendor-specific data engineering certifications- AWS, Azure , and GCP. Cloudera or Databricks? Why Are Data Engineering Skills In Demand?
I took a service that I already run on AWS, ported to Ethereum, and ran it for a week, to understand first-hand how this technology fares. You couldn’t say the same for their AWS accounts for example. Going full circle, and returning to AWS Lambda in order to run my Web3 solution, is all a bit disappointing! Migration: $5.00
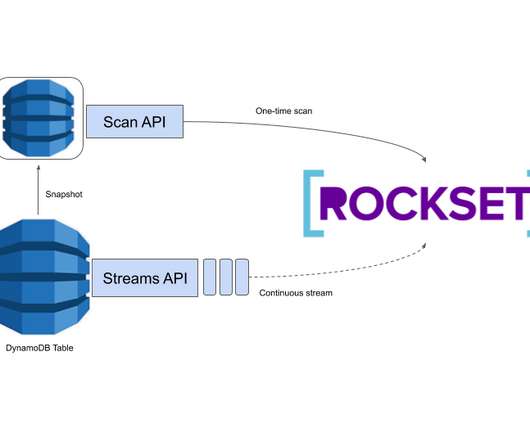
Background on DynamoDB APIs AWS offers a Scan API and a Streams API for reading data from DynamoDB. Each API call response unavoidably transfers a small amount (768 bytes) of data. The Scan API allows us to linearly scan an entire DynamoDB table. This is expensive, but sometimes unavoidable.
Top Paas providers: AWS beanstalk , Oracle Cloud Platform (OCP) , Google App Engine IaaS – Infrastructure as a Service – Provide infrastructure such as servers, physical storage, networking, memory devices etc. Only the changed layers are rebuilt, rest of the unchanged image layers are reused. OS Kernel may also be risked.
These include, but are not limitedto: Future putObjectAsync(byte[] object, Path path, Callback callback); InputStream getObjectInputStream(Path path); Clearly, in-place updates and modifications to uploaded log segments are unnecessary. Amazon, AWS, S3, and EC2 are trademarks of Amazon.com, Inc. or its affiliates.
To give you a snapshot, as of October 2023, in the AWS-US West region, the on-demand storage pricing stood at $40 per terabyte per month. Example Snowflake pricing in the AWS – US West region. Intelligent data pipelines aim to maximize the efficiency of every byte of data and every second of compute. Source: Snowflake Pricing.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content