This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Whether it’s unifying transactional and analytical data with Hybrid Tables, improving governance for an open lakehouse with Snowflake Open Catalog or enhancing threat detection and monitoring with Snowflake Horizon Catalog , Snowflake is reducing the number of moving parts to give customers a fully managed service that just works.
More than 50% of data leaders recently surveyed by BCG said the complexity of their dataarchitecture is a significant pain point in their enterprise. As a result,” says BCG, “many companies find themselves at a tipping point, at risk of drowning in a deluge of data, overburdened with complexity and costs.”
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. Each of these architectures has its own unique strengths and tradeoffs.
It incorporates elements from several Microsoft products working together, like Power BI, Azure Synapse Analytics, Data Factory, and OneLake, into a single SaaS experience. It provides real multi-cloud flexibility in its operations on AWS , Azure, and Google Cloud.
Summary The Presto project has become the de facto option for building scalable open source analytics in SQL for the datalake. Another area that has been seeing a lot of activity is datalakes and projects to make them more manageable and feature complete (e.g. Hudi, Delta Lake, Iceberg, Nessie, LakeFS, etc.).
In this episode Kevin Liu shares some of the interesting features that they have built by combining those technologies, as well as the challenges that they face in supporting the myriad workloads that are thrown at this layer of their data platform. Can you describe what role Trino and Iceberg play in Stripe's dataarchitecture?
In this episode he explains how it is designed to allow for querying and combining data where it resides, the use cases that such an architecture unlocks, and the innovative ways that it is being employed at companies across the world.
In August, we wrote about how in a future where distributed dataarchitectures are inevitable, unifying and managing operational and business metadata is critical to successfully maximizing the value of data, analytics, and AI. Both platforms are free to try today.
Note : Cloud Data warehouses like Snowflake and Big Query already have a default time travel feature. However, this feature becomes an absolute must-have if you are operating your analytics on top of your datalake or lakehouse. It can also be integrated into major data platforms like Snowflake.
[link] Alireza Sadeghi: Open Source Data Engineering Landscape 2025 This article comprehensively overviews the 2025 open-source data engineering landscape, highlighting key trends, active projects, and emerging technologies.
Key Differences Between AI Data Engineers and Traditional Data Engineers While traditional data engineers and AI data engineers have similar responsibilities, they ultimately differ in where they focus their efforts. Data Storage Solutions As we all know, data can be stored in a variety of ways.
Anyways, I wasn’t paying enough attention during university classes, and today I’ll walk you through data layers using — guess what — an example. Business Scenario & DataArchitecture Imagine this: next year, a new team on the grid, Red Thunder Racing, will call us (yes, me and you) to set up their new data infrastructure.
At Precisely’s Trust ’23 conference, Chief Operating Officer Eric Yau hosted an expert panel discussion on modern dataarchitectures. The group kicked off the session by exchanging ideas about what it means to have a modern dataarchitecture.
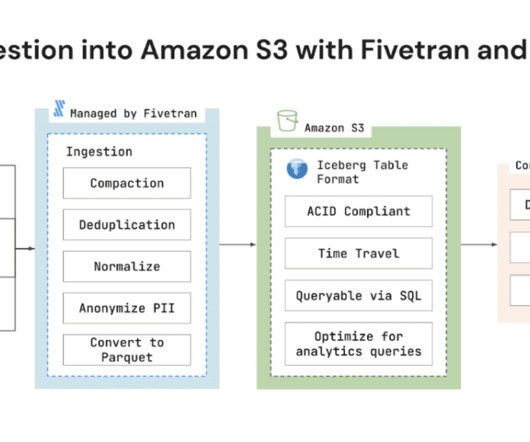
Today we want to introduce Fivetran’s support for Amazon S3 with Apache Iceberg, investigate some of the implications of this feature, and learn how it fits into the modern dataarchitecture as a whole. Fivetran today announced support for Amazon Simple Storage Service (Amazon S3) with Apache Iceberg datalake format.
In 2010, a transformative concept took root in the realm of data storage and analytics — a datalake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. What is a datalake?
Cloudera customers run some of the biggest datalakes on earth. These lakes power mission critical large scale data analytics, business intelligence (BI), and machine learning use cases, including enterprise data warehouses. On data warehouses and datalakes.
Imagine being in charge of creating an intelligent data universe where collaboration, analytics, and artificial intelligence all work together harmoniously. Companies with expertise in Microsoft Fabric are in high demand, including Microsoft, Accenture, AWS, and Deloitte Are you prepared to influence the data-driven future?
Summary Object storage is quickly becoming the unifying layer for data intensive applications and analytics. Modern, cloud oriented data warehouses and datalakes both rely on the durability and ease of use that it provides.
Summary With the constant evolution of technology for data management it can seem impossible to make an informed decision about whether to build a data warehouse, or a datalake, or just leave your data wherever it currently rests. How does it influence the relevancy of data warehouses or datalakes?
Data organizations often have a mix of centralized and decentralized activity. DataOps concerns itself with the complex flow of data across teams, data centers and organizational boundaries. It expands beyond tools and dataarchitecture and views the data organization from the perspective of its processes and workflows.
This week’s episode is also sponsored by Datacoral, an AWS-native, serverless, data infrastructure that installs in your VPC. We have partnered with organizations such as O’Reilly Media, Dataversity, Corinium Global Intelligence, Alluxio, and Data Council.
To get a better understanding of a data architect’s role, let’s clear up what dataarchitecture is. Dataarchitecture is the organization and design of how data is collected, transformed, integrated, stored, and used by a company. Sample of a high-level dataarchitecture blueprint for Azure BI programs.
The migration enhanced data quality, lineage visibility, performance improvements, cost reductions, and better reliability and scalability, setting a robust foundation for future expansions and onboarding. This approach helps maintain accuracy, relevance, and compliance in generative AI applications.
Even the best of us sometimes demonize the parts of our organization whose primary goals are in the privacy and security area and conflict with our wishes to splash around in the datalake. In reality, data scientists are not always the heroes and IT and security teams are not the villains. You’re using the data, of course!
What is Databricks Databricks is an analytics platform with a unified set of tools for data engineering, data management , data science, and machine learning. It combines the best elements of a data warehouse, a centralized repository for structured data, and a datalake used to host large amounts of raw data.
With major clients including Spotify, Puma, Five Guys, and Icelandair, Bynder uses large amounts of data to provide dashboards and open APIs to its customers, as well as vital operational insights to internal users. But when the company started to experience rapid growth, it noticed performance issues with its dataarchitecture. “
The pun being obvious, there’s more to that than just a new term: Data lakehouses combine the best features of both datalakes and data warehouses and this post will explain this all. What is a data lakehouse? Data warehouse vs datalake vs data lakehouse: What’s the difference.
Evolution of DataLake Technologies The datalake ecosystem has matured significantly in 2024, particularly in table formats and storage technologies. S3 Tables and Cloud Integration AWS’s introduction of S3 Tables marked a pivotal shift, enabling faster queries and easier management.
The Importance of a Data Pipeline What is an ETL Data Pipeline? What is a Big Data Pipeline? Features of a Data Pipeline Data Pipeline Architecture How to Build an End-to-End Data Pipeline from Scratch? The transformed data is then placed into the destination data warehouse or datalake.
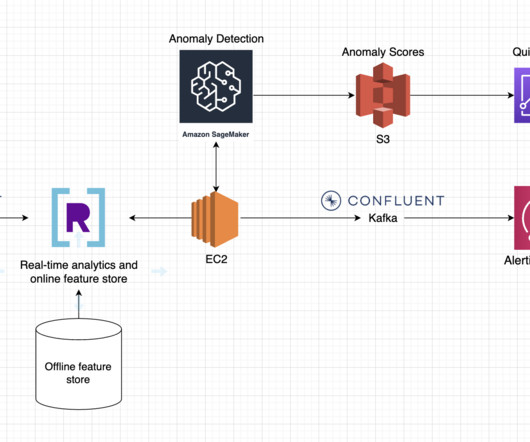
We’ve noticed many common patterns across streaming dataarchitectures and we’ll be sharing a blueprint for three of the most popular: anomaly detection, IoT, and recommendations. Offline feature store : Detecting anomalies requires historical data in order to have a baseline for comparisons. The database has two primary jobs.
Role Level Intermediate Responsibilities Design and develop data pipelines to ingest, process, and transform data. Implemented and managed data storage solutions using Azure services like Azure SQL Database , Azure DataLake Storage, and Azure Cosmos DB.
The modern data stack era , roughly 2017 to present data, saw the widespread adoption of cloud computing and modern data repositories that decoupled storage from compute such as data warehouses, datalakes, and data lakehouses. They also recently acquired Apache Flink , another streaming solution.
Key connectivity features include: Data Ingestion: Databricks supports data ingestion from a variety of sources, including datalakes, databases, streaming platforms, and cloud storage. This flexibility allows organizations to ingest data from virtually anywhere.
In the dynamic world of data, many professionals are still fixated on traditional patterns of data warehousing and ETL, even while their organizations are migrating to the cloud and adopting cloud-native data services. Central to this transformation are two shifts.
Iris tackles the challenge of extracting actionable insights from complex, cross-platform metrics by routing data in real-time to systems like InfluxDB and offline to AWS-based datalakes.
Some of the top skills to include are: Experience with Azure data storage solutions: Azure Data Engineers should have hands-on experience with various Azure data storage solutions such as Azure Cosmos DB, Azure DataLake Storage, and Azure Blob Storage.
Unstructured data , on the other hand, is unpredictable and has no fixed schema, making it more challenging to analyze. Without a fixed schema, the data can vary in structure and organization. There are several widely used unstructured data storage solutions such as datalakes (e.g., Build dataarchitecture.
Data Factory, Data Activator, Power BI, Synapse Real-Time Analytics, Synapse Data Engineering, Synapse Data Science, and Synapse Data Warehouse are some of them. With One Lake serving as a primary multi-cloud repository, Fabric is designed with an open, lake-centric architecture.
Data pipelines can handle both batch and streaming data, and at a high-level, the methods for measuring data quality for either type of asset are much the same. We’ll take a closer look at variables that can impact your data next. What is a decentralized dataarchitecture?
He also has more than 10 years of experience in big data, being among the few data engineers to work on Hadoop Big Data Analytics prior to the adoption of public cloud providers like AWS, Azure, and Google Cloud Platform. He is also an AWS Certified Solutions Architect and AWS Certified Big Data expert.
Cloud Era: Cloud platforms like AWS and Azure took center stage, making sophisticated data solutions accessible to all. Modern Landscape: Today, Data Engineering involves slick ETL processes, real-time streaming, and the concept of datalakes, shaping the backbone of our data-driven world.
Snowflake Features that Make Data Science Easier Building Data Applications with Snowflake Data Warehouse Snowflake Data Warehouse Architecture How Does Snowflake Store Data Internally? The query processing layer is separated from the disk storage layer in the Snowflake dataarchitecture.
Azure Synapse offers a second layer of encryption for data at rest using customer-managed keys stored in Azure Key Vault, providing enhanced data security and control over key management. Cost-Effective DataLake Integration Azure Synapse lets you ditch the traditional separation between SQL and Spark for datalake exploration.
AWS or Azure? With so many data engineering certifications available , choosing the right one can be a daunting task. This section mainly focuses on the three most valuable and popular vendor-specific data engineering certifications- AWS, Azure , and GCP. Cloudera or Databricks?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content