This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
More than 50% of data leaders recently surveyed by BCG said the complexity of their dataarchitecture is a significant pain point in their enterprise. As a result,” says BCG, “many companies find themselves at a tipping point, at risk of drowning in a deluge of data, overburdened with complexity and costs.”
__init__ Episode Tensorflow Spark The intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA Support Data Engineering Podcast Summary Databases are limited in scope to the information that they directly contain.
Are you struggling to manage the ever-increasing volume and variety of data in today’s constantly evolving landscape of modern dataarchitectures? Apache Ozone is compatible with Amazon S3 and Hadoop FileSystem protocols and provides bucket layouts that are optimized for both Object Store and File system semantics.
The result is a multi-tenant Data Engineering platform, allowing users and services access to only the data they require for their work. In this post, we focus on how we enhanced and extended Monarch , Pinterest’s Hadoop based batch processing system, with FGAC capabilities.
Striim offers an out-of-the-box adapter for Snowflake to stream real-time data from enterprise databases (using low-impact change data capture ), log files from security devices and other systems, IoT sensors and devices, messaging systems, and Hadoop solutions, and provide in-flight transformation capabilities.
Key Differences Between AI Data Engineers and Traditional Data Engineers While traditional data engineers and AI data engineers have similar responsibilities, they ultimately differ in where they focus their efforts.
Additionally, the optimized query execution and data pruning features reduce the compute cost associated with querying large datasets. Scaling data infrastructure while maintaining efficiency is one of the primary challenges of modern dataarchitecture.
Big data has taken over many aspects of our lives and as it continues to grow and expand, big data is creating the need for better and faster data storage and analysis. These Apache Hadoop projects are mostly into migration, integration, scalability, data analytics, and streaming analysis. Data Migration 2.
This specialist works closely with people on both business and IT sides of a company to understand the current needs of the stakeholders and help them unlock the full potential of data. To get a better understanding of a data architect’s role, let’s clear up what dataarchitecture is.
This week’s episode is also sponsored by Datacoral, an AWS-native, serverless, data infrastructure that installs in your VPC. We have partnered with organizations such as O’Reilly Media, Dataversity, Corinium Global Intelligence, Alluxio, and Data Council.
This week’s episode is also sponsored by Datacoral, an AWS-native, serverless, data infrastructure that installs in your VPC. We have partnered with organizations such as O’Reilly Media, Dataversity, Corinium Global Intelligence, Alluxio, and Data Council.
Most of the Data engineers working in the field enroll themselves in several other training programs to learn an outside skill, such as Hadoop or Big Data querying, alongside their Master's degree and PhDs. Data Engineers use the AWS platform to design the flow of data.
Data Engineer Bootcamp : The Data Engineer Bootcamp course is designed to give students the skills and knowledge they need to become successful data engineers. The course covers the basics of data engineering, including dataarchitecture, data modeling, and data management.
Lineage and chain of custody, advanced data discovery and business glossary. Support Kafka connectivity to HDFS, AWS S3 and Kafka Streams. The customer team included several Hadoop administrators, a program manager, a database administrator and an enterprise architect. Customer A was able to upgrade successfully from CDH 5.14.2
Typically, data processing is done using frameworks such as Hadoop, Spark, MapReduce, Flink, and Pig, to mention a few. How is Hadoop related to Big Data? Explain the difference between Hadoop and RDBMS. Data Variety Hadoop stores structured, semi-structured and unstructured data.
Amazon Web Services (AWS) – Most programmers utilize the well-known cloud computing platform AWS to increase their flexibility, originality, and scalability. To create autonomous data streams, Data Engineering teams use AWS. Big Data analytics can benefit from it because of this.
Data engineering involves a lot of technical skills like Python, Java, and SQL (Structured Query Language). For a data engineer career, you must have knowledge of data storage and processing technologies like Hadoop, Spark, and NoSQL databases. Understanding of Big Data technologies such as Hadoop, Spark, and Kafka.
Go for the best courses for Data Engineering and polish your big data engineer skills to take up the following responsibilities: You should have a systematic approach to creating and working on various dataarchitectures necessary for storing, processing, and analyzing large amounts of data.
Part of the Data Engineer’s role is to figure out how to best present huge amounts of different data sets in a way that an analyst, scientist, or product manager can analyze. What does a data engineer do? A data engineer is an engineer who creates solutions from raw data.
AWS or Azure? With so many data engineering certifications available , choosing the right one can be a daunting task. This section mainly focuses on the three most valuable and popular vendor-specific data engineering certifications- AWS, Azure , and GCP. Cloudera or Databricks?
Source: Databricks Delta Lake is an open-source, file-based storage layer that adds reliability and functionality to existing data lakes built on Amazon S3, Google Cloud Storage, Azure Data Lake Storage, Alibaba Cloud, HDFS ( Hadoop distributed file system), and others. Databricks focuses on data engineering and data science.
Without a fixed schema, the data can vary in structure and organization. File systems, data lakes, and Big Data processing frameworks like Hadoop and Spark are often utilized for managing and analyzing unstructured data. There are several widely used unstructured data storage solutions such as data lakes (e.g.,
Big Data Engineer performs a multi-faceted role in an organization by identifying, extracting, and delivering the data sets in useful formats. A Big Data Engineer also constructs, tests, and maintains the Big Dataarchitecture. Your organization will use internal and external sources to port the data.
Skills For Azure Data Engineer Resumes Here are examples of popular skills from Azure Data Engineer Hadoop: An open-source software framework called Hadoop is used to store and process large amounts of data on a cluster of inexpensive servers.
Follow Charles on LinkedIn 3) Deepak Goyal Azure Instructor at Microsoft Deepak is a certified big data and Azure Cloud Solution Architect with more than 13 years of experience in the IT industry. On LinkedIn, he focuses largely on Spark, Hadoop, big data, big data engineering, and data engineering.
Hadoop and Spark: The cavalry arrived in the form of Hadoop and Spark, revolutionizing how we process and analyze large datasets. Cloud Era: Cloud platforms like AWS and Azure took center stage, making sophisticated data solutions accessible to all.
The Importance of a Data Pipeline What is an ETL Data Pipeline? What is a Big Data Pipeline? Features of a Data Pipeline Data Pipeline Architecture How to Build an End-to-End Data Pipeline from Scratch? What is a Big Data Pipeline?
Data Warehousing: Experience in using tools like Amazon Redshift, Google BigQuery, or Snowflake. Big Data Technologies: Aware of Hadoop, Spark, and other platforms for big data. With experience and skills, you can advance to roles such as: Mid-level Data Engineer: Lead small teams; deliver more complex data tasks.
They work together with stakeholders to get business requirements and develop scalable and efficient dataarchitectures. Role Level Advanced Responsibilities Design and architect data solutions on Azure, considering factors like scalability, reliability, security, and performance.
Data engineers working on healthcare product development may build data systems to support AI-powered medical image analysis. On the other hand, a data engineer working in a hospital system might design a dataarchitecture that manages and integrates electronic medical records.
A data warehouse can contain unstructured data too. How does Network File System (NFS) differ from Hadoop Distributed File System (HDFS)? Network File System Hadoop Distributed File System NFS can store and process only small volumes of data. Explain how Big Data and Hadoop are related to each other.
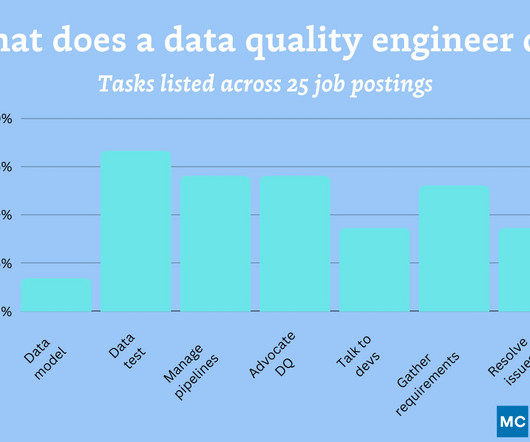
The most common use case data quality engineers support are: Analytical dashboards : Mentioned in 56% of job postings Machine learning or data science teams : Mentioned in 34% of postings Gen AI : Mentioned in one job posting (but really emphatically).
Also, data lakes support ELT (Extract, Load, Transform) processes, in which transformation can happen after the data is loaded in a centralized store. A data lakehouse may be an option if you want the best of both worlds. Real-time ingestion immediately brings data into the data lake as it is generated.
Technical Data Engineer Skills 1.Python Python Python is one of the most looked upon and popular programming languages, using which data engineers can create integrations, data pipelines, integrations, automation, and data cleansing and analysis. Knowledge of requirements and knowledge of machine learning libraries.
Snowflake Features that Make Data Science Easier Building Data Applications with Snowflake Data Warehouse Snowflake Data Warehouse Architecture How Does Snowflake Store Data Internally? Snowflake is not based on existing database systems or big data software platforms like Hadoop.
5 Data pipeline architecture designs and their evolution The Hadoop era , roughly 2011 to 2017, arguably ushered in big data processing capabilities to mainstream organizations. Data then, and even today for some organizations, was primarily hosted in on-premises databases with non-scalable storage.
The pun being obvious, there’s more to that than just a new term: Data lakehouses combine the best features of both data lakes and data warehouses and this post will explain this all. What is a data lakehouse? Data lakehouse architecture designs. Storage layer. Metadata layer.
It covers popular technologies such as Apache Kafka, Apache Storm, and Apache Hadoop, giving users practical advice on developing and executing effective data pipelines. Key Benefits and Takeaways: Learn the core concepts of big data systems. Investigate real-time data processing methods by employing distributed systems.
However, if you require a platform that can handle a broader spectrum of data processing tasks, including real-time analytics and machine learning, Databricks' Apache Spark-based architecture is more appropriate. Azure Synapse also supports integration with Azure Data Lake Storage and other Azure data services.
Senior data engineers design and implement robust dataarchitectures, mentor junior engineers in their Craft, and drive critical strategic data initiatives. Average Salary for Data Engineers Based on Location The salary of data engineers can vary significantly based on their geographical location.
Machine learning engineers must also have experience in working on standard ML frameworks like TensorFlow, Scikit-learn, Apache Hadoop, PyTorch, and a few others. They should be familiar with major coding languages like R, Python, Scala, and Java and scientific computing tools like MATLAB.
Deloitte: The average annual compensation for data scientists in Deloitte is about ₹7,00,000 in India. PwC: The average salary for a PwC data scientist in India is about 5. Amazon and AWS: The average salary of a data scientist working at Amazon is about ₹13,00,000.
This indicates that Microsoft Azure Data Engineers are in high demand. Azure's usage graph grows every year, bringing it closer to AWS. These companies are migrating their data and servers from on-premises to Azure Cloud. This exam assesses your ability to set up a data processing pipeline and configure each component.
The Apache Hadoop open source big data project ecosystem with tools such as Pig, Impala, Hive, Spark, Kafka Oozie, and HDFS can be used for storage and processing. Big Data Project using Hadoop with Source Code for Web Server Log Processing 5. Raw page data counts from Wikipedia can be collected and processed via Hadoop.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content