This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Jia Zhan, Senior Staff Software Engineer, Pinterest Sachin Holla, Principal Solution Architect, AWS Summary Pinterest is a visual search engine and powers over 550 million monthly active users globally. Pinterests infrastructure runs on AWS and leverages Amazon EC2 instances for its compute fleet. 4xl with up to 12.5 4xl with up to 12.5
In a recent session with the Delta Lake project I was able to share the work led Kuntal Basu and a number of other people to dramatically improve the efficiency and reliability of our online dataingestion pipeline. as they take you behind the scenes of Scribds dataingestion setup.
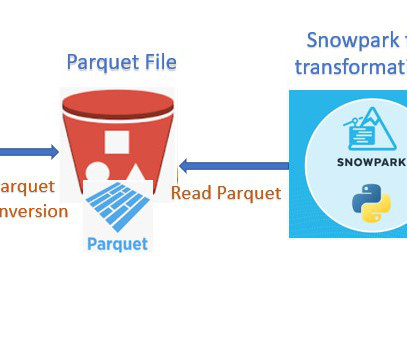
Read Time: 2 Minute, 39 Second During this post we will discuss a simple scenario using AWS Glue and Snowpark. As per the requirement source system has fed a CSV file to our S3 bucket which needs to be ingested into Snowflake. Parquet, columnar storage file format saves both time and space when it comes to big data processing.
Snowflake Unistore consolidates both into a single database so users get a drastically simplified architecture with less data movement and consistent security and governance controls. Ingestdata more efficiently and manage costs For data managed by Snowflake, we are introducing features that help you access data easily and cost-effectively.
Snowflake ML now also supports the ability to generate and use synthetic data, now in public preview. Inference: Model Serving in Snowpark Container Services, now generally available in both AWS and Azure, offers easy and performant distributed inference with CPUs or GPUs for any model, regardless of where it was trained.
Do ETL and data integration activities seem complex to you? AWS Glue is here to put an end to all your worries! Read this blog to understand everything about AWS Glue that makes it one of the most popular data integration solutions in the industry. Did you know the global big data market will likely reach $268.4
We left off last time concluding finance has the largest demand for data engineers who have skills with AWS, and sketched out what our dataingestion pipeline will look like. I began building out the dataingestion pipeline by launching an EC2 instance.
I can now begin drafting my dataingestion/ streaming pipeline without being overwhelmed. The remaining tech (stages 3, 4, 7 and 8) are all AWS technologies. What's Next I'll be documenting how I build this setup in the AWS console (with screenshots).
This foundational layer is a repository for various data types, from transaction logs and sensor data to social media feeds and system logs. By storing data in its native state in cloud storage solutions such as AWS S3, Google Cloud Storage, or Azure ADLS, the Bronze layer preserves the full fidelity of the data.
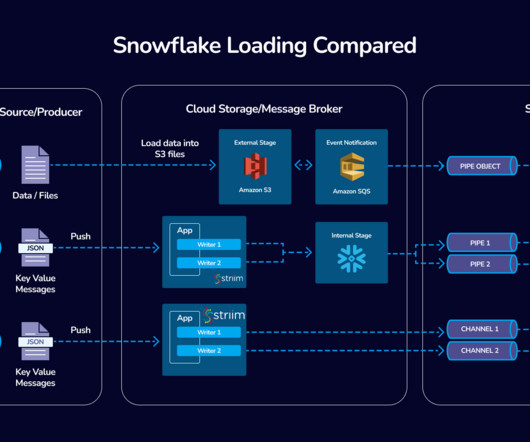
Read Time: 2 Minute, 34 Second Introduction In modern data pipelines, especially in cloud data platforms like Snowflake, dataingestion from external systems such as AWS S3 is common.
At the heart of every data-driven decision is a deceptively simple question: How do you get the right data to the right place at the right time? The growing field of dataingestion tools offers a range of answers, each with implications to ponder. Fivetran Image courtesy of Fivetran.
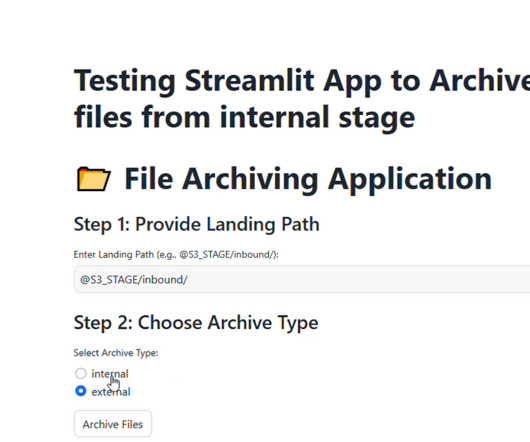
Handling feed files in data pipelines is a critical task for many organizations. These files, often stored in stages such as Amazon S3 or Snowflake internal stages, are the backbone of dataingestion workflows. Without a proper archival strategy, these files can clutter staging areas, leading to operational challenges.
But at Snowflake, we’re committed to making the first step the easiest — with seamless, cost-effective dataingestion to help bring your workloads into the AI Data Cloud with ease. Like any first step, dataingestion is a critical foundational block. Ingestion with Snowflake should feel like a breeze.
Introduction In the fast-evolving world of data integration, Striim’s collaboration with Snowflake stands as a beacon of innovation and efficiency. This mode is particularly useful for audit trails or scenarios where preserving the historical sequence of data changes is important.
With AWS rapidly slicing the cost of S3 Express, the blog makes a solid argument that disk-based Kafka is 3.7X The popularity also exposes its Achilles heel, the replication and network bottlenecks. expensive than diskless Kafka out of S3 Express One. Apache Hudi, for example, introduces an indexing technique to Lakehouse.
Dataingestion is the process of collecting data from various sources and moving it to your data warehouse or lake for processing and analysis. It is the first step in modern data management workflows. Table of Contents What is DataIngestion? Decision making would be slower and less accurate.
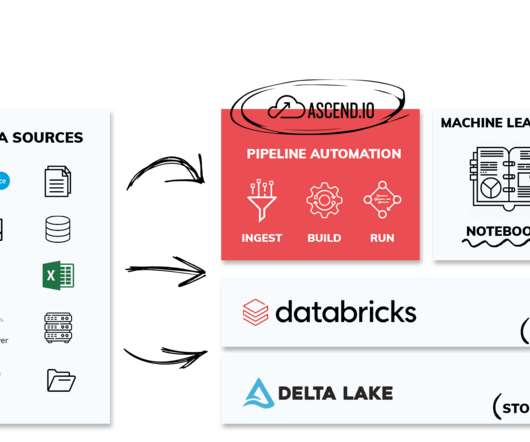
The Ascend Data Automation Cloud provides a unified platform for dataingestion, transformation, orchestration, and observability. Ascend automates workloads on Snowflake, Databricks, BigQuery, and open source Spark, and can be deployed in AWS, Azure, or GCP. Support Data Engineering Podcast
This is where real-time dataingestion comes into the picture. Data is collected from various sources such as social media feeds, website interactions, log files and processing. This refers to Real-time dataingestion. To achieve this goal, pursuing Data Engineer certification can be highly beneficial.
Companies with expertise in Microsoft Fabric are in high demand, including Microsoft, Accenture, AWS, and Deloitte Are you prepared to influence the data-driven future? Programming Languages: Hands-on experience with SQL, Kusto Query Language (KQL), and Data Analysis Expressions ( DAX ).
Thank you to the hundreds of AWS re:Invent attendees who stopped by our booth! We hope the real-time demonstrations of Ascend automating data pipelines were a real treat—a long with the special edition T-Shirt designed specifically for the show (picture of our founder and CEO rocking the t-shirt below).
Snowflake Horizon Snowflake enhances network security – general availability on AWS and Azure Snowflake enhances network security for customers with network rules, schema-level objects that group network identifiers into logical units. support in Snowpark – general availability Get support for Python 3.11 Learn more here.
The accuracy of decisions improves dramatically once you can use live data in real-time. The AWS training will prepare you to become a master of the cloud, storing, processing, and developing applications for the cloud data. Amazon AWS Kinesis makes it possible to process and analyze data from multiple sources in real-time.
However, going from data to the shape of a model in production can be challenging as it comprises data preprocessing, training, and deployment at a large scale. Amazon SageMaker, an AWS-managed AI service, is created to support enterprises on this journey and make it efficient and easy. Table of Content What is Amazon SageMaker?
The Ascend Data Automation Cloud provides a unified platform for dataingestion, transformation, orchestration, and observability. Ascend automates workloads on Snowflake, Databricks, BigQuery, and open source Spark, and can be deployed in AWS, Azure, or GCP.
Dataingestion pipeline with Operation Management — At Netflix they annotate video which can lead to thousand of annotation but they need to manage the annotation lifecycle each time the annotation algorithm runs. AWS lambdas are still on Python 3.9 — Corey rant about AWS lambdas that are still using Python 3.9
SNP Group is tackling this challenge head-on, leveraging the Snowflake Native App Framework (generally available on AWS and Azure, private preview on GCP) to create its SNP Glue Connector for SAP. Customers can process changed data once or twice a day — or at whatever cadence they prefer — to the main table.
The company quickly realized maintaining 10 years’ worth of production data while enabling real-time dataingestion led to an unscalable situation that would have necessitated a data lake. That began with migrating those massive stores of data from SQL Server to Snowflake.
The Cloud represents an iteration beyond the on-prem data warehouse, where computing resources are delivered over the Internet and are managed by a third-party provider. Examples include: Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP). Data integrations and pipelines can also impact latency.
The Ascend Data Automation Cloud provides a unified platform for dataingestion, transformation, orchestration, and observability. Ascend automates workloads on Snowflake, Databricks, BigQuery, and open source Spark, and can be deployed in AWS, Azure, or GCP.
The Ascend Data Automation Cloud provides a unified platform for dataingestion, transformation, orchestration, and observability. Ascend automates workloads on Snowflake, Databricks, BigQuery, and open source Spark, and can be deployed in AWS, Azure, or GCP.
AWS is the gold standard of Cloud Computing and has some reasons for it. It offers more than 170 AWS services to the developers so they can use them from anywhere when required. AWS Applications provide many services, from storage to serverless computing, and can be tailored to meet diverse business requirements. What is AWS?
Schedule dataingestion, processing, model training and insight generation to enhance efficiency and consistency in your data processes. Snowflake Notebooks is now available in Warehouse Runtime (PuPr) for all Snowflake accounts deployed across AWS, Azure and GCP.
In 2019, the company embarked on a mission to modernize and simplify its data platform. Now, the team is on an ongoing mission to use Snowflake’s data platform to simplify the complexity of its tech stack. With Snowflake’s Kafka connector, the technology team can ingest tokenized data as JSON into tables as VARIANT.
The Ascend Data Automation Cloud provides a unified platform for dataingestion, transformation, orchestration, and observability. Ascend automates workloads on Snowflake, Databricks, BigQuery, and open source Spark, and can be deployed in AWS, Azure, or GCP.
For AWS this means at least P3 instances. DataIngestion. The raw data is in a series of CSV files. We will firstly convert this to parquet format as most data lakes exist as object stores full of parquet files. Common problems at this stage can be related to GPU versions. P2 GPU instances are not supported.
While we walk through the steps one by one from dataingestion to analysis, we will also demonstrate how Ozone can serve as an ‘S3’ compatible object store. Learn more about the impacts of global data sharing in this blog, The Ethics of Data Exchange. Dataingestion through ‘s3’. Ozone Namespace Overview.
Druid at Lyft Apache Druid is an in-memory, columnar, distributed, open-source data store designed for sub-second queries on real-time and historical data. Druid enables low latency (real-time) dataingestion, flexible data exploration and fast data aggregation resulting in sub-second query latencies.
After the launch of Cloudera DataFlow for the Public Cloud (CDF-PC) on AWS a few months ago, we are thrilled to announce that CDF-PC is now generally available on Microsoft Azure, allowing NiFi users on Azure to run their data flows in a cloud-native runtime. . DataIngest for Microsoft Sentinel .
The Ascend Data Automation Cloud provides a unified platform for dataingestion, transformation, orchestration, and observability. Ascend automates workloads on Snowflake, Databricks, BigQuery, and open source Spark, and can be deployed in AWS, Azure, or GCP.
The Ascend Data Automation Cloud provides a unified platform for dataingestion, transformation, orchestration, and observability. Ascend automates workloads on Snowflake, Databricks, BigQuery, and open source Spark, and can be deployed in AWS, Azure, or GCP. Email hosts@dataengineeringpodcast.com ) with your story.
Securely manage and deploy full-stack applications with Snowpark Container Services Snowpark Container Services, public preview soon in select AWS regions, makes it easy for developers to deploy, manage and scale containerized workloads – all with Snowflake’s secure and fully managed infrastructure. Let’s dive in!
It allows real-time dataingestion, processing, model deployment and monitoring in a reliable and scalable way. This blog post focuses on how the Kafka ecosystem can help solve the impedance mismatch between data scientists, data engineers and production engineers. For now, we’ll focus on Kafka.
AWS, for example, offers services such as Amazon FSx and Amazon EFS for mirroring your data in a high-performance file system in the cloud. AI Store offers a kubernetes -based solution for a lightweight storage stack adjacent to the data consuming applications. client('s3') s3.upload_file('2GB.bin',
The Ascend Data Automation Cloud provides a unified platform for dataingestion, transformation, orchestration, and observability. Ascend automates workloads on Snowflake, Databricks, BigQuery, and open source Spark, and can be deployed in AWS, Azure, or GCP.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content