This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Digital tools and technologies help organizations generate large amounts of data daily, requiring efficient governance and management. This is where the AWSdatalake comes in. With the AWSdatalake, organizations and businesses can store, analyze, and process structured and unstructured data of any size.
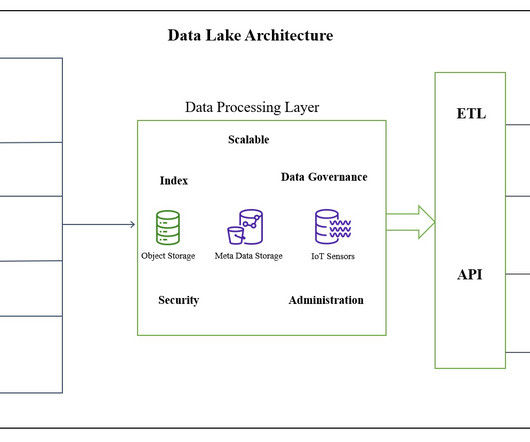
Introduction A datalake is a centralized and scalable repository storing structured and unstructured data. The need for a datalake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Datalakes are notoriously complex. And Starburst does all of this on an open architecture with first-class support for Apache Iceberg, Delta Lake and Hudi, so you always maintain ownership of your data.
AWS Infrastructure costs 4.3 Datalake structure 5. Loading user purchase data into the data warehouse 5.2 Loading classified movie review data into the data warehouse 5.3 Introduction 2. Objective 3. Prerequisite 4.2 Code walkthrough 5.1 Generating user behavior metric 5.4. Checking results 6.
Summary A data lakehouse is intended to combine the benefits of datalakes (cost effective, scalable storage and compute) and data warehouses (user friendly SQL interface). Datalakes are notoriously complex. Visit [dataengineeringpodcast.com/data-council]([link] and use code *depod20* to register today!
Datalakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the datalake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics.
Snowflake Unistore consolidates both into a single database so users get a drastically simplified architecture with less data movement and consistent security and governance controls. Ingest data more efficiently and manage costs For data managed by Snowflake, we are introducing features that help you access data easily and cost-effectively.
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. These patterns include both centralized storage patterns like data warehouse , datalake and data lakehouse , and distributed patterns such as data mesh.
Summary The Presto project has become the de facto option for building scalable open source analytics in SQL for the datalake. Another area that has been seeing a lot of activity is datalakes and projects to make them more manageable and feature complete (e.g. Hudi, Delta Lake, Iceberg, Nessie, LakeFS, etc.).
Data Access API over DataLake Tables Without the Complexity Build a robust GraphQL API service on top of your S3 datalake files with DuckDB and Go Photo by Joshua Sortino on Unsplash 1. This data might be primarily used for internal reporting, but might also be valuable for other services in our organization.
It incorporates elements from several Microsoft products working together, like Power BI, Azure Synapse Analytics, Data Factory, and OneLake, into a single SaaS experience. It provides real multi-cloud flexibility in its operations on AWS , Azure, and Google Cloud.
Do ETL and data integration activities seem complex to you? AWS Glue is here to put an end to all your worries! Read this blog to understand everything about AWS Glue that makes it one of the most popular data integration solutions in the industry. Did you know the global big data market will likely reach $268.4
In this episode Yingjun Wu explains how it is architected to power analytical workflows on continuous data flows, and the challenges of making it responsive and scalable. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Datalakes are notoriously complex.
In this episode Kevin Liu shares some of the interesting features that they have built by combining those technologies, as well as the challenges that they face in supporting the myriad workloads that are thrown at this layer of their data platform.
Datalakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the datalake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics.
Data warehouse vs. datalake, each has their own unique advantages and disadvantages; it’s helpful to understand their similarities and differences. In this article, we’ll focus on a datalake vs. data warehouse. It is often used as a foundation for enterprise datalakes.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management RudderStack helps you build a customer data platform on your warehouse or datalake. Rudderstack]([link] RudderStack provides all your customer data pipelines in one platform.
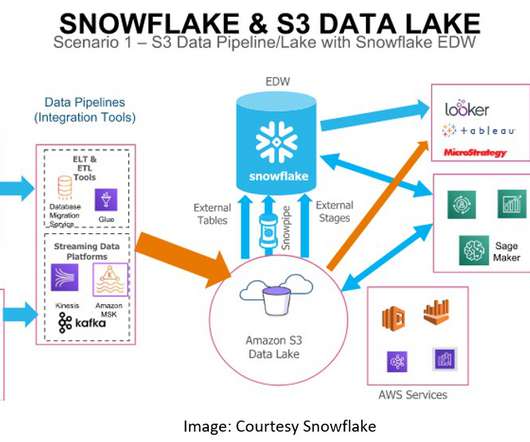
Read Time: 4 Minute, 23 Second During this post we will discuss how AWS S3 service and Snowflake integration can be used as DataLake in current organizations. How customer has migrated On Premises EDW to Snowflake to leverage snowflake DataLake capabilities. Create S3 bucket to hold the tables data.
Summary Data lakehouse architectures are gaining popularity due to the flexibility and cost effectiveness that they offer. The link that bridges the gap between datalake and warehouse capabilities is the catalog. Datalakes are notoriously complex. What is involved in integrating Nessie into a given data stack?
The authorization furthers Snowflake’s commitment to helping our government customers secure and mobilize their mission-critical data It’s a milestone moment for Snowflake to have achieved FedRAMP High authorization on the AWS GovCloud (US-West and US-East Regions).
A datalake is essentially a vast digital dumping ground where companies toss all their raw data, structured or not. A modern data stack can be built on top of this data storage and processing layer, or a data lakehouse or data warehouse, to store data and process it before it is later transformed and sent off for analysis.
Datalakes are useful, flexible data storage repositories that enable many types of data to be stored in its rawest state. Traditionally, after being stored in a datalake, raw data was then often moved to various destinations like a data warehouse for further processing, analysis, and consumption.
This brings us to todays topic: exploring strategies to manage your organizations data infrastructure in the most efficient and cost-efficient way possible. Databricks clusters and AWS EC2 In todays landscape, big data, which is data too large to fit into a single node machine, is transformed and managed by clusters.
Note : Cloud Data warehouses like Snowflake and Big Query already have a default time travel feature. However, this feature becomes an absolute must-have if you are operating your analytics on top of your datalake or lakehouse. It can also be integrated into major data platforms like Snowflake. Contact phData Today!
Establish the Infrastructure The project began with establishing the data infrastructure. They opted for Snowflake, a cloud-native data platform ideal for SQL-based analysis. AWS Redshift, GCP Big Query, or Azure Synapse work well, too. It is necessary to have more than a datalake and a database.
Next — working backwards — collaboration tooling such as dashboards and developer environments like those on Amazon Web Services (AWS), are also key components to consider. Underneath all of this are the data assets themselves, with appropriate governance (e.g.
One of the most important innovations in data management is open table formats, specifically Apache Iceberg , which fundamentally transforms the way data teams manage operational metadata in the datalake. Try Cloudera’s open data lakehouse on AWS for 5 days for free here , or try Snowflake for free for 30 days here.
Acryl Data provides DataHub as an easy to consume SaaS product which has been adopted by several companies. Signup for the SaaS product at dataengineeringpodcast.com/acryl RudderStack helps you build a customer data platform on your warehouse or datalake. Stop struggling to speed up your datalake.
CMS Chief Information Security Officer Rob Wood and Chief information Architect Amine Raounak led an in-depth presentation on their security datalake initiative with Snowflake. The security datalake project enables data-driven decision-making for system and product security at scale within CMS.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
Datafold integrates with all major data warehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows. RudderStack helps you build a customer data platform on your warehouse or datalake. runs natively on datalakes and warehouses and in AWS, Google Cloud and Microsoft Azure.
An open-source implementation of a DataLake with DuckDB and AWS Lambdas A duck in the cloud. Moreover, the data will need to leave the cloud env to go on our machine, which is not exactly secure and auditable. The idea is to start from a DataLake where our data are stored.
In 2010, a transformative concept took root in the realm of data storage and analytics — a datalake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. What is a datalake?
“DataLake vs Data Warehouse = Load First, Think Later vs Think First, Load Later” The terms datalake and data warehouse are frequently stumbled upon when it comes to storing large volumes of data. Data Warehouse Architecture What is a Datalake? What is a Datalake?
The terms “ Data Warehouse ” and “ DataLake ” may have confused you, and you have some questions. Structuring data refers to converting unstructured data into tables and defining data types and relationships based on a schema. What is DataLake? . Athena on AWS. .
With this public preview, those external catalog options are either “GLUE”, where Snowflake can retrieve table metadata snapshots from AWS Glue Data Catalog, or “OBJECT_STORE”, where Snowflake retrieves metadata snapshots directly from the specified cloud storage location. With these three options, which one should you use?
[link] Alireza Sadeghi: Open Source Data Engineering Landscape 2025 This article comprehensively overviews the 2025 open-source data engineering landscape, highlighting key trends, active projects, and emerging technologies.
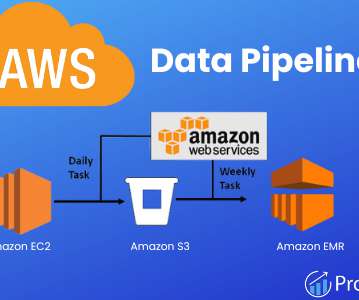
An AWSdata pipeline helps businesses move and unify their data to support several data-driven initiatives. It enables flow from a datalake to an analytics database or an application to a data warehouse. AWS CLI is an excellent tool for managing Amazon Web Services.
[link] Affirm: Expressive Time Travel and Data Validation for Financial Workloads Affirm migrated from daily MySQL snapshots to Change Data Capture (CDC) replay using Apache Iceberg for its datalake, improving data integrity and governance.
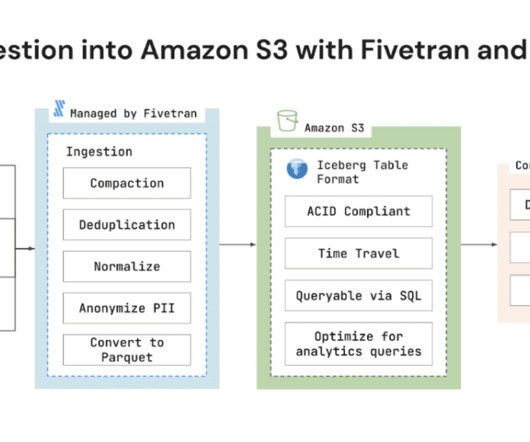
Fivetran today announced support for Amazon Simple Storage Service (Amazon S3) with Apache Iceberg datalake format. Amazon S3 is an object storage service from Amazon Web Services (AWS) that offers industry-leading scalability, data availability, security, and performance.
However, going from data to the shape of a model in production can be challenging as it comprises data preprocessing, training, and deployment at a large scale. Amazon SageMaker, an AWS-managed AI service, is created to support enterprises on this journey and make it efficient and easy. Table of Content What is Amazon SageMaker?
Summary The "data lakehouse" architecture balances the scalability and flexibility of datalakes with the ease of use and transaction support of data warehouses. Mention the podcast to get a free "In Data We Trust World Tour" t-shirt.
Notably, there are several prominent cloud service providers in the market, such as Amazon AWS, Google GCP, and Microsoft Azure. In this blog, we will focus on the certifications offered by Amazon AWS. We will specifically talk about the AWS certification exam, AWS certification cost, and Amazon certification path.
Cloudera customers run some of the biggest datalakes on earth. These lakes power mission critical large scale data analytics, business intelligence (BI), and machine learning use cases, including enterprise data warehouses. On data warehouses and datalakes.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content