This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
dbt Core is an open-source framework that helps you organise data warehouse SQL transformation. dbt was born out of the analysis that more and more companies were switching from on-premise Hadoop data infrastructure to cloud data warehouses. tests — a way to define SQL tests either at column-level, either with a query.
Prior the introduction of CDP Public Cloud, many organizations that wanted to leverage CDH, HDP or any other on-prem Hadoop runtime in the public cloud had to deploy the platform in a lift-and-shift fashion, commonly known as “Hadoop-on-IaaS” or simply the IaaS model. SQL-driven Streaming App Development. Introduction.
Spark has long allowed to run SQL queries on a remote Thrift JDBC server. The appropriate Spark dependencies (spark-core/spark-sql or spark-connect-client-jvm) will be provided later in the Java classpath, depending on the run mode. hadoop-aws since we almost always have interaction with S3 storage on the client side).
Your host is Tobias Macey and today I’m interviewing Martin Traverso about PrestoSQL, a distributed SQL engine that queries data in place Interview Introduction How did you get involved in the area of data management? Can you start by giving an overview of what Presto is and its origin story?
In the data world Snowflake and Databricks are our dedicated platforms, we consider them big, but when we take the whole tech ecosystem they are (so) small: AWS revenue is $80b, Azure is $62b and GCP is $37b. A UX where you buy a single tool combining engine and storage, where all you have to do is flow data in, write SQL, and it's done.
Striim offers an out-of-the-box adapter for Snowflake to stream real-time data from enterprise databases (using low-impact change data capture ), log files from security devices and other systems, IoT sensors and devices, messaging systems, and Hadoop solutions, and provide in-flight transformation capabilities.
Ozone natively provides Amazon S3 and Hadoop Filesystem compatible endpoints in addition to its own native object store API endpoint and is designed to work seamlessly with enterprise scale data warehousing, machine learning and streaming workloads. Boto3 is the standard python client for the AWS SDK. Spark SQL to access Hive table.
For example, running a SQL request on Postgres means creating a connection, and a cursor, instantiating and configuring some objects, running the SQL query, and so on. COPY stock_transform.py /app/ RUN wget [link] && wget [link] && mv hadoop-aws-3.3.2.jar In production, it will be a service like AWS ECR.
News on Hadoop - February 2018 Kyvos Insights to Host Webinar on Accelerating Business Intelligence with Native Hadoop BI Platforms. The leading big data analytics company Kyvo Insights is hosting a webinar titled “Accelerate Business Intelligence with Native Hadoop BI platforms.” PRNewswire.com, February 1, 2018.
News on Hadoop-April 2017 AI Will Eclipse Hadoop, Says Forrester, So Cloudera Files For IPO As A Machine Learning Platform. Apache Hadoop was one of the revolutionary technology in the big data space but now it is buried deep by Deep Learning. Hortonworks unveiled this use case of SQL through Apache Hive 2.0
For organizations who are considering moving from a legacy data warehouse to Snowflake, are looking to learn more about how the AI Data Cloud can support legacy Hadoop use cases, or are struggling with a cloud data warehouse that just isn’t scaling anymore, it often helps to see how others have done it.
Spark offers over 80 high-level operators that make it easy to build parallel apps and one can use it interactively from the Scala, Python, R, and SQL shells. Spark powers a stack of libraries including SQL and DataFrames, MLlib for machine learning, GraphX, and Spark Streaming. Basic knowledge of SQL. Yarn etc) Or, 2.
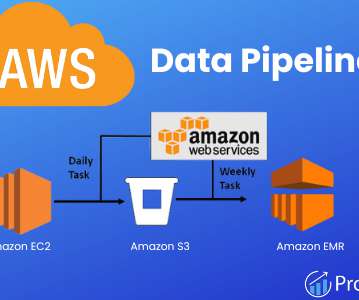
An AWS data pipeline helps businesses move and unify their data to support several data-driven initiatives. Amazon Web Services (AWS) offers an AWS Data Pipeline solution that helps businesses automate the transformation and movement of data. AWS CLI is an excellent tool for managing Amazon Web Services.
It is a cloud-based service by Amazon Web Services (AWS) that simplifies processing large, distributed datasets using popular open-source frameworks, including Apache Hadoop and Spark. Let’s see what is AWS EMR, its features, benefits, and especially how it helps you unlock the power of your big data. What is EMR in AWS?
Both traditional and AI data engineers should be fluent in SQL for managing structured data, but AI data engineers should be proficient in NoSQL databases as well for unstructured data management. Proficiency in Programming Languages Knowledge of programming languages is a must for AI data engineers and traditional data engineers alike.
An open-source implementation of a Data Lake with DuckDB and AWS Lambdas A duck in the cloud. To make the cloud experience as smooth as possible we designed a data lake architecture where data are sitting in a simple cloud storage (AWS S3) and a serverless infrastructure that embeds DuckDB works as a query engine. The cloud is better.
I was in the Hadoop world and all I was doing was denormalisation. The only normalisation I did was back at the engineering school while learning SQL with Normal Forms. Under the hood it uses sqlglot the SQL parser that has been developper by the same developper. Denormalisation everywhere. YAML configured.
I was in the Hadoop world and all I was doing was denormalisation. The only normalisation I did was back at the engineering school while learning SQL with Normal Forms. Under the hood it uses sqlglot the SQL parser that has been developper by the same developper. Denormalisation everywhere. YAML configured.
This job requires a handful of skills, starting from a strong foundation of SQL and programming languages like Python , Java , etc. Most of the Data engineers working in the field enroll themselves in several other training programs to learn an outside skill, such as Hadoop or Big Data querying, alongside their Master's degree and PhDs.
Apache Hadoop and Apache Spark fulfill this need as is quite evident from the various projects that these two frameworks are getting better at faster data storage and analysis. These Apache Hadoop projects are mostly into migration, integration, scalability, data analytics, and streaming analysis. Table of Contents Why Apache Hadoop?
Evolution of Open Table Formats Here’s a timeline that outlines the key moments in the evolution of open table formats: 2008 - Apache Hive and Hive Table Format Facebook introduced Apache Hive as one of the first table formats as part of its data warehousing infrastructure, built on top of Hadoop.
A solid understanding of relational databases and SQL language is a must-have skill, as an ability to manipulate large amounts of data effectively. A good Data Engineer will also have experience working with NoSQL solutions such as MongoDB or Cassandra, while knowledge of Hadoop or Spark would be beneficial. What is AWS Kinesis?
AWS has changed the life of data scientists by making all the data processing, gathering, and retrieving easy. One popular cloud computing service is AWS (Amazon Web Services). Many people are going for Data Science Courses in India to leverage the true power of AWS. What is Amazon Web Services (AWS)?
Datafold shows how a change in SQL code affects your data, both on a statistical level and down to individual rows and values before it gets merged to production. Output data can be streamed into a data lake for query engines like Presto, Trino or Spark SQL, a data warehouse like Snowflake or Redshift., Pricing for SQLake is simple.
When it comes to cloud computing and big data, Amazon Web Services (AWS) has emerged as a leading name. With a versatile platform, AWS has enabled businesses to innovate and scale beyond their potential. Amazon AWS Learning in big data also extends to data management challenges like increasing volume and variations in data.
This week’s episode is also sponsored by Datacoral, an AWS-native, serverless, data infrastructure that installs in your VPC. He started Datacoral with the goal to make SQL the universal data programming language. He started Datacoral with the goal to make SQL the universal data programming language.
It was designed as a native object store to provide extreme scale, performance, and reliability to handle multiple analytics workloads using either S3 API or the traditional Hadoop API. Structured data (such as name, date, ID, and so on) will be stored in regular SQL databases like Hive or Impala databases. Ozone namespace overview.
Apache Oozie — An open-source workflow scheduler system to manage Apache Hadoop jobs. Redgate — SQL tools to help users implement DataOps, monitor database performance, and provision of new databases. . AWS Code Deploy. AWS Code Pipeline. Sandbox Creation and Management. DBMaestro — DevOps for the database. Azure DevOps.
By acting as a virtual hub for data assets ranging from tables and dashboards to SQL snippets & code, Atlan enables teams to create a single source of truth for all their data assets, and collaborate across the modern data stack through deep integrations with tools like Snowflake, Slack, Looker and more.
Hadoop Gigabytes to petabytes of data may be stored and processed effectively using the open-source framework known as Apache Hadoop. Hadoop enables the clustering of many computers to examine big datasets in parallel more quickly than a single powerful machine for data storage and processing. Packages and Software OpenCV.
As an expert in the dynamic world of cloud computing, I am always amazed by the variety of job prospects provided by Amazon Web Services (AWS). Having an Amazon AWS online course certification in your possession will allow you to showcase the most sought-after skills in the industry. Who is an AWS Engineer?
In what ways have you found it necessary/useful to extend SQL? In what ways have you found it necessary/useful to extend SQL? What are some of the most challenging aspects of building a data warehouse platform that is optimized for speed? How do you handle support for nested and semi-structured data?
Well, how do we know a human writes the SQL for an ad-hoc request, which often goes through a zero review process, wrote the correct SQL query? Snowflake is a DataLake Platform Snowflake is moving beyond a SQL data warehouse. AWS EMR replicated the exact Hadoop layer and burned these two companies (combined).
It helps to understand concepts like abstractions, algorithms, data structures, security, and web development and familiarizes learners with many languages like C, Python, SQL, CSS, JavaScript, and HTML. Select and use one of Google Cloud's storage solutions, which include Cloud Storage, Cloud SQL, Cloud Bigtable, and Firestore.
Iceberg supports many catalog implementations: Hive, AWS Glue, Hadoop, Nessie, Dell ECS, any relational database via JDBC, REST, and now Snowflake. show() And you’re not limited to only SQL—you can also query using DataFrames with other languages like Python and Scala. First, let’s see what tables are available to query.
ACID transactions, ANSI 2016 SQL SupportMajor Performance improvements. Support Kafka connectivity to HDFS, AWS S3 and Kafka Streams. This customer’s workloads leverage batch processing of data from 100+ backend database sources like Oracle, SQL Server, and traditional Mainframes using Syncsort. New Features CDH to CDP.
This week’s episode is also sponsored by Datacoral, an AWS-native, serverless, data infrastructure that installs in your VPC. He started Datacoral with the goal to make SQL the universal data programming language. He started Datacoral with the goal to make SQL the universal data programming language.
Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java. Ascend automates workloads on Snowflake, Databricks, BigQuery, and open source Spark, and can be deployed in AWS, Azure, or GCP.
[link] Dani: Apache Iceberg: The Hadoop of the Modern Data Stack? The comment on Iceber, a Hadoop of the modern data stack, surprises me. Iceberg has not reduced the complexity of the data stack, and all the legacy Hadoop complexity still exists on top of Apache Iceberg. However, I 100% agree with the complex stack to maintain.
With the demand for big data technologies expanding rapidly, Apache Hadoop is at the heart of the big data revolution. Here are top 6 big data analytics vendors that are serving Hadoop needs of various big data companies by providing commercial support. The Global Hadoop Market is anticipated to reach $8.74 billion by 2020.
It serves as a foundation for the entire data management strategy and consists of multiple components including data pipelines; , on-premises and cloud storage facilities – data lakes , data warehouses , data hubs ;, data streaming and Big Data analytics solutions ( Hadoop , Spark , Kafka , etc.);
AWS vs. GCP blog compares the two major cloud platforms to help you choose the best one. So, are you ready to explore the differences between two cloud giants, AWS vs. google cloud? Amazon and Google are the big bulls in cloud technology, and the battle between AWS and GCP has been raging on for a while. Let’s get started!
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content