This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
What was not clear, or easy, was trying to figure out how DuckDB would LIKE to read default AWS […] The post DuckDB … reading from s3 … with AWS Credentials and more. appeared first on Confessions of a Data Guy.
There is an increasing number of cloud providers offering the ability to rent virtual machines, the largest being AWS, GCP, and Azure. How the product works: they currently monitor four cloud providers (AWS, GCP, Hetzner Cloud, Azure.) We envision building something comparable to AWS Fargate , or Google Cloud Run.
Data is the lifeblood of modern businesses, but unlocking its true insights often requires complex SQL queries. We’re thrilled to announce the public preview of Snowflake Copilot, a new solution on the bleeding edge of text-to-SQL that simplifies data analysis while maintaining robust governance.
Introduction Amazon Athena is an interactive query tool supplied by Amazon Web Services (AWS) that allows you to use conventional SQL queries to evaluate data stored in Amazon S3. Athena is a serverless service. Thus there are no servers to operate, and you pay for the queries you perform.
Summary Stream processing systems have long been built with a code-first design, adding SQL as a layer on top of the existing framework. There are numerous stream processing engines, near-real-time database engines, streaming SQL systems, etc. Can you describe what RisingWave is and the story behind it?
However, scaling LLM data processing to millions of records can pose data transfer and orchestration challenges, easily addressed by the user-friendly SQL functions in Snowflake Cortex. Traditionally, SQL has been limited to structured data neatly organized in tables.
Databricks SQL Serverless is now Generally Available on Google Cloud Platform (GCP)! SQL Serverless is available in 7 GCP regions and 40+ regions across AWS, Azure and GCP.
As backend developers, we needed to stay unblocked while the infrastructure — in this case AWS resources — was being created. It was fair to assume that we would use other AWS services, particularly SQS and AWS Secrets Manager. Use LocalStack to enable locally running AWS resources.
RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. It’s the only true SQL streaming database built from the ground up to meet the needs of modern data products. With Materialize, you can!
dbt Core is an open-source framework that helps you organise data warehouse SQL transformation. AWS, GCP, Azure—the storage price dropped and we became data insatiable, we were in need of all the company data, in one place, in order to join and compare everything. When I write dbt, I often mean dbt Core. Enter the ELT.
Unistore is made possible by Hybrid Tables (now generally available on AWS commercial regions with a few exceptions ), which enables fast, single-row reads and writes in order to support transactional workloads. Sensitive data can have enormous value but is oftentimes locked down due to privacy requirements.
There is a clear shortage of professionals certified with Amazon Web Services (AWS). As far as AWS certifications are concerned, there is always a certain debate surrounding them. AWS certification helps you reach new heights in your career with improved pay and job opportunities. What is AWS?
Summary A data lakehouse is intended to combine the benefits of data lakes (cost effective, scalable storage and compute) and data warehouses (user friendly SQL interface). Multiple open source projects and vendors have been working together to make this vision a reality. Your first 30 days are free! Data lakes are notoriously complex.
AWS Glue is here to put an end to all your worries! Read this blog to understand everything about AWS Glue that makes it one of the most popular data integration solutions in the industry. Well, AWS Glue is the answer to your problems! In 2023, more than 5140 businesses worldwide have started using AWS Glue as a big data tool.
Inference: Model Serving in Snowpark Container Services, now generally available in both AWS and Azure, offers easy and performant distributed inference with CPUs or GPUs for any model, regardless of where it was trained. Snowflake ML now also supports the ability to generate and use synthetic data, now in public preview.
But, instead of GCP, we’ll be using AWS. AWS is, by far, the most popular cloud computing platform, it has an absurd number of products to solve every type of specific problem you imagine. So, join me on this post to develop a full data pipeline from scratch using some pieces from the AWS toolset. S3 is AWS’ blob storage.
Agents use Cortex Analyst (structured SQL) and Cortex Search (unstructured data) as tools, along with LLMs, to analyze and generate answers. Route across tools: The agent selects a tool Cortex Analyst, Cortex Search or SQL generation from natural language to facilitate governed access and enable compliance with enterprise policies.
RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. It’s the only true SQL streaming database built from the ground up to meet the needs of modern data products. With Materialize, you can! Rudderstack :  small: AWS revenue is $80b, Azure is $62b and GCP is $37b. A UX where you buy a single tool combining engine and storage, where all you have to do is flow data in, write SQL, and it's done.
Your host is Tobias Macey and today I’m interviewing Martin Traverso about PrestoSQL, a distributed SQL engine that queries data in place Interview Introduction How did you get involved in the area of data management? Can you start by giving an overview of what Presto is and its origin story?
With AWS rapidly slicing the cost of S3 Express, the blog makes a solid argument that disk-based Kafka is 3.7X The popularity also exposes its Achilles heel, the replication and network bottlenecks. expensive than diskless Kafka out of S3 Express One. Apache Hudi, for example, introduces an indexing technique to Lakehouse.
link] Wealthfront: Our Journey to Building a Scalable SQL Testing Library for Athena Wealthfront introduces an in-house SQL testing library tailored for AWS Athena, emphasizing principles of zero-footprint testing via CTEs, usability through Python integration and existing Avro schemas, dynamic test execution, and clear test feedback.
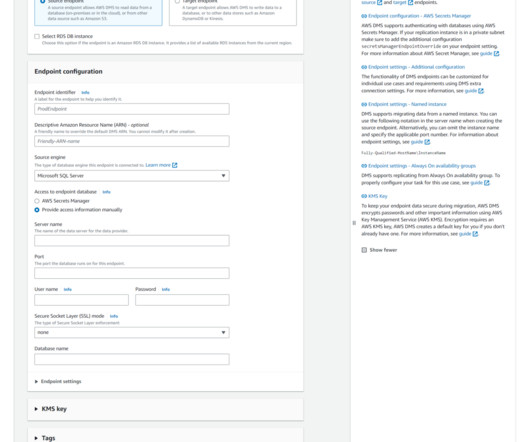
This is where AWS Database Migration Service (DMS) and […] You’re trying to keep everything in sync, but manual updates and batch processing don’t cut it anymore. You need a reliable way to keep your data up-to-date across all platforms.
link] JBarti: Write Manageable Queries With The BigQuery Pipe Syntax Our quest to simplify SQL is always an adventure. The blog narrates a few examples of Pipe Syntax in comparison with the SQL queries. BigQuery's pipe syntax seems exciting to watch, and it is an interesting approach to how it gets adopted.
The Zalando TechRadar guides teams about the database selection and their deployment options – AWS RDS with Postgres as one of the available options. Complex anomaly detection tasks, such as byzantine failures or issues with SQL statements, takes a noticeable investment all over the place. Hidden costs by toil.
Efficiently Intelligent: Arctic excels at enterprise tasks such as SQL generation, coding and instruction following benchmarks even when compared to open source models trained with significantly higher compute budgets. Enterprises want to use LLMs to build conversational SQL data copilots, code copilots and RAG chatbots.
For data engineers who battle to build and scale high quality data workflows on the data lake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics.
Cloudera recently signed a strategic collaboration agreement with Amazon Web Services (AWS), reinforcing our relationship and commitment to accelerating and scaling cloud native data management and data analytics on AWS. Let us dive into what is happening in each of these pillars between AWS and Cloudera.
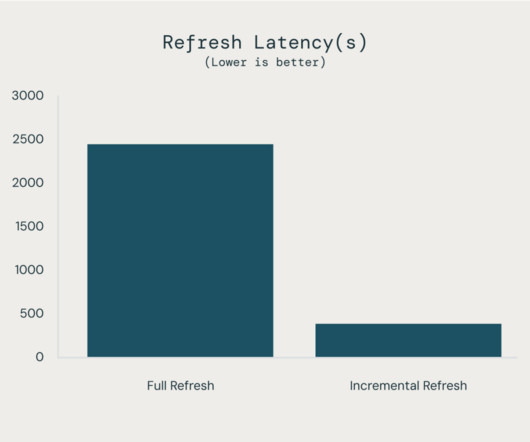
Read Time: 2 Minute, 34 Second Introduction In modern data pipelines, especially in cloud data platforms like Snowflake, data ingestion from external systems such as AWS S3 is common. Snowpark and SQL-based solution. Why is This Framework Important? Manual validations across hundreds of files and tables? Error-prone!
Snowflake Notebooks aim to provide a convenient, easy-to-use interactive environment that seamlessly blends Python, SQL and Markdown, as well as integrations with key Snowflake offerings, like Snowpark ML, Streamlit, Cortex and Iceberg tables. Discover valuable business insights through exploratory data analysis.
Spark has long allowed to run SQL queries on a remote Thrift JDBC server. The appropriate Spark dependencies (spark-core/spark-sql or spark-connect-client-jvm) will be provided later in the Java classpath, depending on the run mode. hadoop-aws since we almost always have interaction with S3 storage on the client side).
As described in our recent blog post , an SQL AI Assistant has been integrated into Hue with the capability to leverage the power of large language models (LLMs) for a number of SQL tasks. This is a real game-changer for data analysts on all levels and will make SQL development faster, easier, and less error-prone.
To add this metric to DJ, they need to provide two pieces of information: The fact table that the metric comesfrom: SELECT account_id, country_iso_code, streaming_hours FROM streaming_fact_table The metric expression: `SUM(streaming_hours)` Then metric consumers throughout the organization can call DJ to request either the SQL or the resulting data.
Databricks clusters and AWS EC2 In todays landscape, big data, which is data too large to fit into a single node machine, is transformed and managed by clusters. Clusters in Databricks Databricks offers Job clusters for data pipeline processing and warehouse clusters used for the SQL lakehouse. But what are clusters?
The AWS training will prepare you to become a master of the cloud, storing, processing, and developing applications for the cloud data. Amazon AWS Kinesis makes it possible to process and analyze data from multiple sources in real-time. It shows how AWS Kinesis can be effectively used for processing the streaming data.
Eventador simplifies the process by allowing users to use SQL to query streams of real-time data without implementing complex code. We recently delivered all three of these streaming capabilities as cloud services through Cloudera Data Platform (CDP) Data Hub on AWS and Azure.
Snowpark Container Services: This additional Snowpark runtime (available in public preview soon on select AWS regions) enables developers to effortlessly deploy, manage and scale custom containerized workloads and models for tasks such as fine-tuning open-source LLMs using secure Snowflake-managed infrastructure with GPU instances.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content