This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
If you want to stay ahead of the curve, you need to be aware of the top bigdata technologies that will be popular in 2024. In this blog post, we will discuss such technologies. This article will discuss bigdata analytics technologies, technologies used in bigdata, and new bigdata technologies.
There are multiple differences, of course; for example, Pinot is intended to work in big clusters. There are a couple of comparisons on the internet, like this one , but it’s worth mentioning that they are quite old and both systems have changed a lot, so if you’re aware of more recent comparisons, please let me know!
Traditional scheduling solutions used in bigdatatools come with several drawbacks. The system is slow to respond to the increased load as well as to the potential opportunities to scale down the cluster when jobs are finished. That’s why turning to traditional resource scheduling is not sufficient.
Some systems think that it should be in milliseconds, and some think that it should be in seconds. That wraps up April’s Data Engineering Annotated. Follow JetBrains BigDataTools on Twitter and subscribe to our blog for more news! You can also get in touch with our team at big-data-tools@jetbrains.com.
Some systems think that it should be in milliseconds, and some think that it should be in seconds. That wraps up April’s Data Engineering Annotated. Follow JetBrains BigDataTools on Twitter and subscribe to our blog for more news! You can also get in touch with our team at big-data-tools@jetbrains.com.
For example, null-safe joins may be implemented only in a language with a null-aware type system, like Kotlin. Async sinks in Flink – Apache Flink may be one of the most popular on-premises streaming tools. It can put data virtually anywhere, but there is still some room for improvement. That wraps up our Annotated this month.
For example, null-safe joins may be implemented only in a language with a null-aware type system, like Kotlin. Async sinks in Flink – Apache Flink may be one of the most popular on-premises streaming tools. It can put data virtually anywhere, but there is still some room for improvement. That wraps up our Annotated this month.
they’ve built JetStream, which is actually a persistent message queue system inside NATS. Future improvements Data engineering technologies are evolving every day. That wraps up November’s Data Engineering Annotated. Follow JetBrains BigDataTools on Twitter and subscribe to our blog for more news!
they’ve built JetStream, which is actually a persistent message queue system inside NATS. Future improvements Data engineering technologies are evolving every day. That wraps up November’s Data Engineering Annotated. Follow JetBrains BigDataTools on Twitter and subscribe to our blog for more news!
If you haven’t found your perfect metadata management system just yet, maybe it’s time to try DataHub! The most notable change in the latest release is support for streaming, which means you can now ingest data from streaming sources. Pulsar Manager 0.3.0 – Lots of enterprise systems lack a nice management interface.
If you haven’t found your perfect metadata management system just yet, maybe it’s time to try DataHub! The most notable change in the latest release is support for streaming, which means you can now ingest data from streaming sources. Pulsar Manager 0.3.0 – Lots of enterprise systems lack a nice management interface.
Here are some great articles and posts that can help us all learn from the experience of other people, teams, and companies who work in data engineering. Real-Time Exactly-Once Ad Event Processing with Apache Flink, Kafka, and Pinot – As an expert in distributed systems, I’m always very skeptical when I read or hear the words “exactly once”.
Here are some great articles and posts that can help us all learn from the experience of other people, teams, and companies who work in data engineering. Real-Time Exactly-Once Ad Event Processing with Apache Flink, Kafka, and Pinot – As an expert in distributed systems, I’m always very skeptical when I read or hear the words “exactly once”.
In this world of bigdata, whereevery nugget of information is precious but overwhelming, Apach Splunk shines as a beacon of hope with its cutting-edge data management and analysis capabilities. This log data can be generated from various sources, including servers, applications, network devices, and security systems.
How is it possible to support distributed transactions and solve the other complex problems of distributed systems? I’ve already shared a similar piece by Matt Turck , who does this every year for the whole data landscape. That wraps up June’s Data Engineering Annotated. To be honest, I’m a little skeptical.
How is it possible to support distributed transactions and solve the other complex problems of distributed systems? I’ve already shared a similar piece by Matt Turck , who does this every year for the whole data landscape. That wraps up June’s Data Engineering Annotated. To be honest, I’m a little skeptical.
Azure Data Engineering is a rapidly growing field that involves designing, building, and maintaining data processing systems using Microsoft Azure technologies. Contents: What is the role of an Azure Data Engineer? Azure data engineers are essential in the design, implementation, and upkeep of cloud-based data solutions.
There are multiple differences, of course; for example, Pinot is intended to work in big clusters. There are a couple of comparisons on the internet, like this one , but it’s worth mentioning that they are quite old and both systems have changed a lot, so if you’re aware of more recent comparisons, please let me know!
Many years ago, when Java seemed slow, and its JIT compiler was not as cool as it is today, some of the people working on the OSv operating system recognized that they could make many more optimizations in user space than they could in kernel space. That wraps up October’s Data Engineering Annotated.
Many years ago, when Java seemed slow, and its JIT compiler was not as cool as it is today, some of the people working on the OSv operating system recognized that they could make many more optimizations in user space than they could in kernel space. That wraps up October’s Data Engineering Annotated.
.); machine learning and deep learning models; and business intelligence tools. If you are not familiar with the above-mentioned concepts, we suggest you to follow the links above to learn more about each of them in our blog posts. Let’s discuss and compare them to avoid misconceptions. Problem-solving skills.
ProjectPro has precisely that in this section, but before presenting it, we would like to answer a few common questions to strengthen your inclination towards data engineering further. What is Data Engineering? Data Engineering refers to creating practical designs for systems that can extract, keep, and inspect data at a large scale.
According to a recent report from Report Ocean, the ETL Tools Market is likely to reach US$ Million by 2030. If you're wondering how the ETL process can drive your company to a new era of success, this blog will help you discover what use cases of ETL make it a critical component in many data management and analytic systems.
Data professionals who work with raw data like data engineers, data analysts, machine learning scientists , and machine learning engineers also play a crucial role in any data science project. And, out of these professions, this blog will discuss the data engineering job role.
It’s ability to handle large volumes of data and provide real-time insights makes it a goldmine for organization looking to leverage data analytics for competitive advantage. To generate e-commerce company statistics for this dashboard, you can combine test data with internal index data from your own instance.
It is a well-known fact that we inhabit a data-rich world. Businesses are generating, capturing, and storing vast amounts of data at an enormous scale. This influx of data is handled by robust bigdatasystems which are capable of processing, storing, and querying data at scale.
Do ETL and data integration activities seem complex to you? Read this blog to understand everything about AWS Glue that makes it one of the most popular data integration solutions in the industry. Did you know the global bigdata market will likely reach $268.4 AWS Glue is here to put an end to all your worries!
Already familiar with the term bigdata, right? Despite the fact that we would all discuss BigData, it takes a very long time before you confront it in your career. Apache Spark is a BigDatatool that aims to handle large datasets in a parallel and distributed manner.
One of the core features of ADF is the ability to preview your data while creating your data flows efficiently and to evaluate the outcome against a sample of data before completing and implementing your pipelines. Such features make Azure data flow a highly popular tool among data engineers.
This position requires knowledge of Microsoft Azure services such as Azure Data Factory, Azure Stream Analytics, Azure Databricks, Azure Cosmos DB, and Azure Storage. The following are some of the fundamental foundational skills required of data engineers: A data engineer should be aware of changes in the data landscape.
Apache Spark is an open-source, distributed computing system for bigdata processing and analytics. It has become a popular bigdata and machine learning analytics engine. Spark is used by some of the world's largest and fastest-growing firms to analyze data and allow downstream analytics and machine learning.
1) Joseph Machado Senior Data Engineer at LinkedIn Joseph is an experienced data engineer, holding a Master’s degree in Electrical Engineering from Columbia University and having spent time on the teams at Annalect, Narrativ, and most recently LinkedIn. Deepak regularly shares blog content and similar advice on LinkedIn.
From monitoring and searching through bigdata to generating alerts, reports, and visualizations, Splunk offers several such features to help businesses achieve their goals. This clearly shows how crucial it is for data engineers to be familiar with the Splunk platform if they want to succeed in the bigdata industry.
The blog starts with an introduction to MLOps, skills required to become an MLOps engineer, and then lays out an MLOps learning path for beginners. If all these advantages excite you to dig deeper into this exciting world of MLOps and you have decided to learn more about it, continue reading this blog. Strong communication skills.
Read this blog to find out! This blog on BigData Engineer salary gives you a clear picture of the salary range according to skills, countries, industries, job titles, etc. BigData gets over 1.2 Several industries across the globe are using BigDatatools and technology in their processes and operations.
The rising demand for data analysts along with the increasing salary potential of these roles is making this an increasingly attractive field. But which are the highest-paying data analytics jobs available? This blog lists some of the most lucrative positions for aspiring data analysts. Build datasystems and pipelines.
To store analytical data properly, data engineers also manage it by building a data warehouse. ETL activities are also the responsibility of data engineers. Data needs to be extracted from a variety of sources, transformed, and loaded into the storage systems of businesses.
This blog contains sample projects for business analyst beginners and professionals. So, continue reading this blog to know more about different business analyst projects ideas. Understanding of various analytical tools and their implementation in revealing insights about the business. The blog hasn’t ended yet.
Data pipelines are a significant part of the bigdata domain, and every professional working or willing to work in this field must have extensive knowledge of them. Data Pipeline Tools AWS Data Pipeline Azure Data Pipeline Airflow Data Pipeline Learn to Create a Data Pipeline FAQs on Data Pipeline What is a Data Pipeline?
If you're looking to break into the exciting field of bigdata or advance your bigdata career, being well-prepared for bigdata interview questions is essential. Get ready to expand your knowledge and take your bigdata career to the next level! RDBMS stores structured data.
Many professionals who are investing time to learn Hadoop, for making a transition to bigdata careers often have this question when pursuing a Hadoop certification – “ Is Cloudera Hadoop Certification worth the investment?” They also need to know how to convert data values and use DDL for data analysis.
A quick search for the term “learn hadoop” showed up 856,000 results on Google with thousands of blogs, tutorials, bigdata application demos, online MOOC offering hadoop training and best hadoop books for anyone willing to learn hadoop. Which bigdatatools and technologies should you try to master?
”, “Is it hard to get a data science job?” ” Are you a data science enthusiast who believes data science is hard and keeps thinking about such questions? Allow us to challenge your thoughts and read this blog as we will help you answer all those questions. Is Learning Data Science Worth It?
The increasing number of startups, boom in the e-commerce industry, consumer driven market and growing economy are all set to create huge bigdata job opportunities in the analytics space with commanding salaries in India. India has the second highest demand for bigdata , data science and analytics professionals, US being the first.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






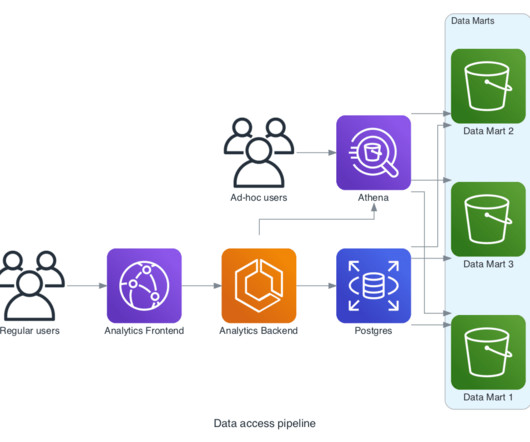
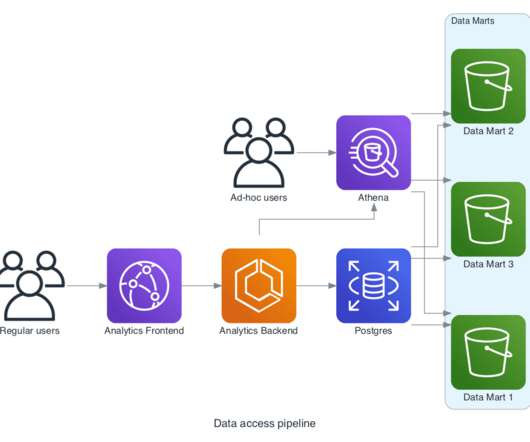











































Let's personalize your content