This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Apache Hadoop is an open-source framework written in Java for distributed storage and processing of huge datasets. The keyword here is distributed since the data quantities in question are too large to be accommodated and analyzed by a single computer. A powerful BigDatatool, Apache Hadoop alone is far from being almighty.
The more effectively a company is able to collect and handle bigdata the more rapidly it grows. Because bigdata has plenty of advantages, hence its importance cannot be denied. Ecommerce businesses like Alibaba, Amazon use bigdata in a massive way. We are discussing here the top bigdatatools: 1.
Here’s what’s happening in data engineering right now. Apache Spark already has two official APIs for JVM – Scala and Java – but we’re hoping the Kotlin API will be useful as well, as we’ve introduced several unique features. Notably, they’ve added experimental support for Java 11 (finally) and virtual tables. Cassandra 4.0
Here’s what’s happening in data engineering right now. Apache Spark already has two official APIs for JVM – Scala and Java – but we’re hoping the Kotlin API will be useful as well, as we’ve introduced several unique features. Notably, they’ve added experimental support for Java 11 (finally) and virtual tables. Cassandra 4.0
We all know Apache NiFi, a stream processing tool with its own processing engine. It has a web interface, allowing you to build the pipeline you need. Furthermore, its interface is not web, but rather a desktop application written in Java (but with a native look and feel). That wraps up January’s Data Engineering Annotated.
We all know Apache NiFi, a stream processing tool with its own processing engine. It has a web interface, allowing you to build the pipeline you need. Furthermore, its interface is not web, but rather a desktop application written in Java (but with a native look and feel). That wraps up January’s Data Engineering Annotated.
As Data Science is an intersection of fields like Mathematics and Statistics, Computer Science, and Business, every role would require some level of experience and skills in each of these areas. To build these necessary skills, a comprehensive course from a reputed source is a great place to start.
and Java 8 still exists but is deprecated. How Uber Achieves Operational Excellence in the Data Quality Experience – Uber is known for having a huge Hadoop installation in Kubernetes. This blog post is more about data quality, though, describing how they built their data quality platform. Support for Scala 2.12
Apache Hive and Apache Spark are the two popular BigDatatools available for complex data processing. To effectively utilize the BigDatatools, it is essential to understand the features and capabilities of the tools. The tool also does not have an automatic code optimization process.
How much Java is required to learn Hadoop? “I want to work with bigdata and hadoop. Building a strong foundation, focusing on the basic skills required for learning Hadoop and comprehensive hands-on training can help neophytes become Hadoop experts. Can students or professionals without Java knowledge learn Hadoop?
However, in practice, many companies don’t necessarily have data architects so there are only data engineers and this distinction won’t be applicable. The daily tasks of a data architect require more of a strategic thinking, while a data engineer’s workload is more about building the software infrastructure, which are technical tasks.
You can also become a self-taught bigdata engineer by working on real-time hands-on bigdata projects on database architecture, data science, or data engineering to qualify for a bigdata engineer job. Data Scientists use ML algorithms to make predictions on the data sets.
and Java 8 still exists but is deprecated. How Uber Achieves Operational Excellence in the Data Quality Experience – Uber is known for having a huge Hadoop installation in Kubernetes. This blog post is more about data quality, though, describing how they built their data quality platform. Support for Scala 2.12
The data engineers are responsible for creating conversational chatbots with the Azure Bot Service and automating metric calculations using the Azure Metrics Advisor. Data engineers must know data management fundamentals, programming languages like Python and Java, cloud computing and have practical knowledge on data technology.
An expert who uses the Hadoop environment to design, create, and deploy BigData solutions is known as a Hadoop Developer. They are skilled in working with tools like MapReduce, Hive, and HBase to manage and process huge datasets, and they are proficient in programming languages like Java and Python. What do they do?
ProjectPro has precisely that in this section, but before presenting it, we would like to answer a few common questions to strengthen your inclination towards data engineering further. What is Data Engineering? Data Engineering refers to creating practical designs for systems that can extract, keep, and inspect data at a large scale.
Thus, as a learner, your goal should be to work on projects that help you explore structured and unstructured data in different formats. Data Warehousing: Data warehousing utilizes and builds a warehouse for storing data. A data engineer interacts with this warehouse almost on an everyday basis.
The role of Azure Data Engineer is in high demand in the field of data management and analytics. As an Azure Data Engineer, you will be in charge of designing, building, deploying, and maintaining data-driven solutions that meet your organization’s business needs. Contents: Who is an Azure Data Engineer?
Languages Python, SQL, Java, Scala R, C++, Java Script, and Python Tools Kafka, Tableau, Snowflake, etc. Skills A data engineer should have good programming and analytical skills with bigdata knowledge. The ML engineers act as a bridge between software engineering and data science.
Innovations on BigData technologies and Hadoop i.e. the Hadoop bigdatatools , let you pick the right ingredients from the data-store, organise them, and mix them. Now, thanks to a number of open source bigdata technology innovations, Hadoop implementation has become much more affordable.
However, if you're here to choose between Kafka vs. RabbitMQ, we would like to tell you this might not be the right question to ask because each of these bigdatatools excels with its architectural features, and one can make a decision as to which is the best based on the business use case. What is Kafka?
Data Aggregation Working with a sample of bigdata allows you to investigate real-time data processing, bigdata project design, and data flow. Learn how to aggregate real-time data using several bigdatatools like Kafka, Zookeeper, Spark, HBase, and Hadoop.
The main objective of Impala is to provide SQL-like interactivity to bigdata analytics just like other bigdatatools - Hive, Spark SQL, Drill, HAWQ , Presto and others. include - Hadoop shell scripts have been rewritten Hadoop JARS have been compiled to run in Java 8.
This blog on BigData Engineer salary gives you a clear picture of the salary range according to skills, countries, industries, job titles, etc. BigData gets over 1.2 Several industries across the globe are using BigDatatools and technology in their processes and operations. So, let's get started!
You can check out the BigData Certification Online to have an in-depth idea about bigdatatools and technologies to prepare for a job in the domain. To get your business in the direction you want, you need to choose the right tools for bigdata analysis based on your business goals, needs, and variety.
It is a popular ETL tool well-suited for bigdata environments and extensively used by data engineers today to build and maintain data pipelines with minimal effort. What client languages, data formats, and integrations does AWS Glue Schema Registry support?
It caters to various built-in Machine Learning APIs that allow machine learning engineers and data scientists to create predictive models. Along with all these, Apache spark caters to different APIs that are Python, Java, R, and Scala programmers can leverage in their program. BigDataTools 23.
If your career goals are headed towards BigData, then 2016 is the best time to hone your skills in the direction, by obtaining one or more of the bigdata certifications. Acquiring bigdata analytics certifications in specific bigdata technologies can help a candidate improve their possibilities of getting hired.
Problem-Solving Abilities: Many certification courses provide projects and assessments which require hands-on practice of bigdatatools which enhances your problem solving capabilities. Networking Opportunities: While pursuing bigdata certification course you are likely to interact with trainers and other data professionals.
Python has a large library set, which is why the vast majority of data scientists and analytics specialists use it at a high level. If you are interested in landing a bigdata or Data Science job, mastering PySpark as a bigdatatool is necessary. Is PySpark a BigDatatool?
Exploratory data analysis (EDA) is crucial in determining data collection structure in a data science workflow, and PySpark can be used for exploratory data analysis and building machine learning pipelines. PySpark is used to process real-time data with Kafka and Streaming, and this exhibits low latency.
The end of a data block points to the location of the next chunk of data blocks. DataNodes store data blocks, whereas NameNodes store these data blocks. Learn more about BigDataTools and Technologies with Innovative and Exciting BigData Projects Examples. Steps for Data preparation.
” or “What are the various bigdatatools in the Hadoop stack that you have worked with?”- What are sinks and sources in Apache Flume when working with Twitter data? Why cannot you use Java primitive data types in Hadoop MapReduce? How many JVMs run on a DataNode and what is their use?
Assume that you are a Java Developer and suddenly your company hops to join the bigdata bandwagon and requires professionals with Java+Hadoop experience. If you have not sharpened your bigdata skills then you will likely get the boot, as your company will start looking for developers with Hadoop experience.
Roles and Responsibilities of Data Engineer Analyze and organize raw data. Builddata systems and pipelines. Conduct complex data analysis and report on results. Prepare data for prescriptive and predictive modeling. Build algorithms and prototypes. It is a must to build appropriate data structures.
Other Competencies You should have proficiency in coding languages like SQL, NoSQL, Python, Java, R, and Scala. You should be thorough with technicalities related to relational and non-relational databases, Data security, ETL (extract, transform, and load) systems, Data storage, automation and scripting, bigdatatools, and machine learning.
Read this blog till the end to learn more about the roles and responsibilities, necessary skillsets, average salaries, and various important certifications that will help you build a successful career as an Azure Data Engineer. The bigdata industry is flourishing, particularly in light of the pandemic's rapid digitalization.
By considering the needs of the business, a Microsoft Certified Data Engineer designs the whole architecture of the data flow. To store analytical data properly, data engineers also manage it by building a data warehouse. ETL activities are also the responsibility of data engineers.
They know how to build well-architected data science products. They mentor mid-level and junior data scientists and are also answerable to the management and stakeholders on any business questions. Today, data scientists are useful in almost every industry.
Modes of Execution for Apache Pig Frequently Asked Apache Pig Interview Questions and Answers Before the advent of Apache Pig, the only way to process huge volumes of data stores on HDFS was - Java based MapReduce programming. The initial step of a PigLatin program is to load the data from HDFS.
Many organizations across these industries have started increasing awareness about the new bigdatatools and are taking steps to develop the bigdata talent pool to drive industrialisation of the analytics segment in India. ” Experts estimate a dearth of 200,000 data analysts in India by 2018.Gartner
Data Integration 3.Scalability Specialized Data Analytics 7.Streaming Apache Spark uses in-memory storage and computing capabilities as its niche to give users the power to handle petabytes of complex data. From Data Engineering Fundamentals to full hands-on example projects , check out data engineering projects by ProjectPro 2.
Follow Joseph on LinkedIn 2) Charles Mendelson Associate Data Engineer at PitchBook Data Charles is a skilled data engineer focused on telling stories with data and buildingtools to empower others to do the same, all in the pursuit of guiding a variety of audiences and stakeholders to make meaningful decisions.
According to IDC, the amount of data will increase by 20 times - between 2010 and 2020, with 77% of the data relevant to organizations being unstructured. 81% of the organizations say that BigData is a top 5 IT priority. What other bigdata use cases you can think of that measure the success of an organization?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



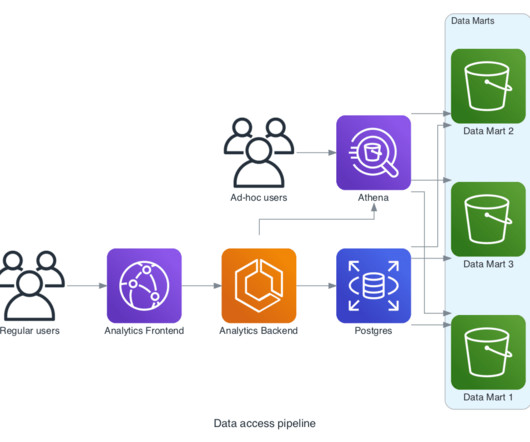
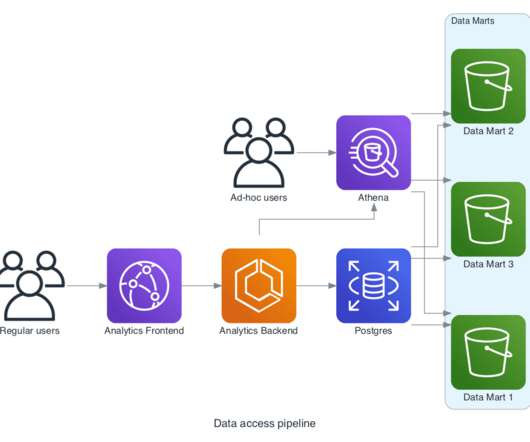














































Let's personalize your content