This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Well, in that case, you must get hold of some excellent bigdatatools that will make your learning journey smooth and easy. Table of Contents What are BigDataTools? Why Are BigDataTools Valuable to Data Professionals? Why Are BigDataTools Valuable to Data Professionals?
Your search for Apache Kafka interview questions ends right here! Let us now dive directly into the Apache Kafka interview questions and answers and help you get started with your BigData interview preparation! What are topics in Apache Kafka? Kafka stores data in topics that are split into partitions.
78% of the employees across European organizations claim that the data keeps growing too rapidly for them to process, thus getting siloed on-premise. So, how can businesses leverage the untapped potential of all the data that is available to them? The answer is-Cloud! as needed for bigdata processing.
A powerful BigDatatool, Apache Hadoop alone is far from being almighty. Currently, the framework supports four options: Standalone , a simple pre-built cluster manager, Hadoop YARN, which is the most common choice for Spark, Apache Mesos , used to control resources of entire data centers and heavy-duty services; and.
In 2024, the data engineering job market is flourishing, with roles like database administrators and architects projected to grow by 8% and salaries averaging $153,000 annually in the US (as per Glassdoor ). These trends underscore the growing demand and significance of data engineering in driving innovation across industries.
Data Collection The first step is to collect real-time data (purchase_data) from various sources, such as sensors, IoT devices, and web applications, using data collectors or agents. These collectors send the data to a central location, typically a message broker like Kafka.
Consequently, data engineers implement checkpoints so that no event is missed or processed twice. It not only consumes more memory but also slackens data transfer. Modern cloud-based data pipelines are agile and elastic to automatically scale compute and storage resources.
ironSource has to collect and store vast amounts of data from millions of devices. ironSource started making use of Upsolver as its data lake for storing raw event data. Kafka streams, consisting of 500,000 events per second, get ingested into Upsolver and stored in AWS S3. Is Hadoop a data lake or data warehouse?
Skills of a Data Engineer Apart from the existing skills of an ETL developer, one must acquire the following additional skills to become a data engineer. Cloud Computing Every business will eventually need to move its data-related activities to the cloud. How to Transition from ETL Developer to Data Engineer?
The advantage of gaining access to data from any device with the help of the internet has become possible because of cloud computing. The birth of cloud computing has been a boon for many individuals and the whole tech industry. Such exciting benefits of cloud computing have led to its rapid adoption by various companies.
Many organizations are struggling to store, manage, and analyze data due to its exponential growth. Cloud-based data lakes allow organizations to gather any form of data, whether structured or unstructured, and make this data accessible for usage across various applications, to address these issues.
Showcase Your Data Engineering Skills with ProjectPro's Complete Data Engineering Certification Course ! Google Trends shows the large-scale demand and popularity of BigData Engineer compared with other similar roles, such as IoT Engineer, AI Programmer, and Cloud Computing Engineer. Who is a BigData Engineer?
Check out the BigData courses online to develop a strong skill set while working with the most powerful BigDatatools and technologies. Look for a suitable bigdata technologies company online to launch your career in the field. What Is a BigDataTool?
These Apache Hadoop projects are mostly into migration, integration, scalability, data analytics, and streaming analysis. These Apache Spark projects are mostly into link prediction, cloud hosting, data analysis, and speech analysis. Data Migration RDBMSs were inefficient and failed to manage the growing demand for current data.
“Unlock the potential of your data with Azure Databricks: a unified analytics platform that combines the power of Apache Spark with the ease of Azure.” ” Azure Databricks is a fully managed service provided by Microsoft that offers the capabilities to create an open data lake house within the Azure cloud environment.
These DStreams allow developers to cache data in memory, which may be particularly handy if the data from a DStream is utilized several times. The cache() function or the persist() method with proper persistence settings can be used to cache data. What are some tools that Spark commonly integrates with, apart from Hadoop?
YuniKorn 1.0.0 – If you’ve been anxiously waiting for Kubernetes to come to data engineering, your wishes have been granted. is a scheduler targeting bigdata and ML workflows, and of course, it is cloud-native. Kafka was the first, and soon enough, everybody was trying to grab their own share of the market.
YuniKorn 1.0.0 – If you’ve been anxiously waiting for Kubernetes to come to data engineering, your wishes have been granted. is a scheduler targeting bigdata and ML workflows, and of course, it is cloud-native. Kafka was the first, and soon enough, everybody was trying to grab their own share of the market.
Data Engineering is the secret sauce to advances in data analysis and data science that we see nowadays. Data Engineering Roles - Who Handles What? As we can see, it turns out that the data engineering role requires a vast knowledge of different bigdatatools and technologies.
Rack-aware Kafka streams – Kafka has already been rack-aware for a while, which gives its users more confidence. When data is replicated between different racks housed in different locations, if anything bad happens to one rack, it won’t happen to another. Enter Mindgrammer – a tool for keeping your diagrams as code.
Rack-aware Kafka streams – Kafka has already been rack-aware for a while, which gives its users more confidence. When data is replicated between different racks housed in different locations, if anything bad happens to one rack, it won’t happen to another. Enter Mindgrammer – a tool for keeping your diagrams as code.
Impala 4.1.0 – While almost all data engineering SQL query engines are written in JVM languages, Impala is written in C++. And yet it is still compatible with different clouds, storage formats (including Kudu , Ozone , and many others), and storage engines. Of course, the main topic is data streaming.
Impala 4.1.0 – While almost all data engineering SQL query engines are written in JVM languages, Impala is written in C++. And yet it is still compatible with different clouds, storage formats (including Kudu , Ozone , and many others), and storage engines. Of course, the main topic is data streaming.
Future improvements Data engineering technologies are evolving every day. Kafka: Allow configuring num.network.threads per listener – Sometimes you find yourself in a situation with Kafka brokers where some listeners are less active than others (and are in some sense more equal than others). What else can I even add?
Future improvements Data engineering technologies are evolving every day. Kafka: Allow configuring num.network.threads per listener – Sometimes you find yourself in a situation with Kafka brokers where some listeners are less active than others (and are in some sense more equal than others). What else can I even add?
What are the advantages of a cloud-based data warehouse? The advantages of a cloud-based data warehouse are listed below: Reduced Cost : Reduced cost is one of the main benefits of using a cloud-based data warehouse. As a result, these servers handle massive volumes of data rapidly and effectively.
It serves as a foundation for the entire data management strategy and consists of multiple components including data pipelines; , on-premises and cloud storage facilities – data lakes , data warehouses , data hubs ;, data streaming and BigData analytics solutions ( Hadoop , Spark , Kafka , etc.);
Your search for Apache Kafka interview questions ends right here! Let us now dive directly into the Apache Kafka interview questions and answers and help you get started with your BigData interview preparation! How to study for Kafka interview? What is Kafka used for? What are main APIs of Kafka?
One of the use cases from the product page that stood out to me in particular was the effort to mirror multiple Kafka clusters in one Brooklin cluster! Ambry v0.3.870 – It turns out that last month was rich in releases from LinkedIn, all of them related in one way or another to data engineering. This is no doubt very interesting.
One of the use cases from the product page that stood out to me in particular was the effort to mirror multiple Kafka clusters in one Brooklin cluster! Ambry v0.3.870 – It turns out that last month was rich in releases from LinkedIn, all of them related in one way or another to data engineering. This is no doubt very interesting.
So, work on projects that guide you on how to build end-to-end ETL/ELT data pipelines. BigDataTools: Without learning about popular bigdatatools, it is almost impossible to complete any task in data engineering. Finally, the data is published and visualized on a Java-based custom Dashboard.
AWS has a broad ecosystem of tools that combine with and extend AWS services. Declarative AWS Cloud Formation templates allow you to deploy AWS resources and your entire AWS infrastructure. Prepare for Your Next BigData Job Interview with Kafka Interview Questions and Answers 3. Secure working environment.
Apache Pig bigdatatools , is used in particular for iterative processing, research on raw data and for traditional ETL data pipelines. Let us know in comments below, to help the bigdata community. 14) What are some of the Apache Pig use cases you can think of?
Azure Data Engineering is a rapidly growing field that involves designing, building, and maintaining data processing systems using Microsoft Azure technologies. As a certified Azure Data Engineer, you have the skills and expertise to design, implement and manage complex data storage and processing solutions on the Azure cloud platform.
are all present in logical data models. The process of creating logical data models is known as logical data modeling. Prepare for Your Next BigData Job Interview with Kafka Interview Questions and Answers 2. How would you create a Data Model using SQL commands? What is Amazon's RDBMS service?
The accuracy of decisions improves dramatically once you can use live data in real-time. The AWS training will prepare you to become a master of the cloud, storing, processing, and developing applications for the clouddata. Compared to BigDatatools, Amazon Kinesis is automated and fully managed.
Furthermore, you will find a few sections on data engineer interview questions commonly asked in various companies leveraging the power of bigdata and data engineering. It involves creating a visual representation of an entire system of data or a part of it. What logging capabilities does AWS Security offer?
Consequently, data engineers implement checkpoints so that no event is missed or processed twice. It not only consumes more memory but also slackens data transfer. Modern cloud-based data pipelines are agile and elastic to automatically scale compute and storage resources.
Problem-Solving Abilities: Many certification courses provide projects and assessments which require hands-on practice of bigdatatools which enhances your problem solving capabilities. Networking Opportunities: While pursuing bigdata certification course you are likely to interact with trainers and other data professionals.
ironSource has to collect and store vast amounts of data from millions of devices. ironSource started making use of Upsolver as its data lake for storing raw event data. Kafka streams, consisting of 500,000 events per second, get ingested into Upsolver and stored in AWS S3. Is Hadoop a data lake or data warehouse?
According to the World Economic Forum, the amount of data generated per day will reach 463 exabytes (1 exabyte = 10 9 gigabytes) globally by the year 2025. Thus, almost every organization has access to large volumes of rich data and needs “experts” who can generate insights from this rich data.
Who is Azure Data Engineer? An Azure Data Engineer is a professional who is in charge of designing, implementing, and maintaining data processing systems and solutions on the Microsoft Azure cloud platform. Learn how to aggregate real-time data using several bigdatatools like Kafka, Zookeeper, Spark, HBase, and Hadoop.
Languages Python, SQL, Java, Scala R, C++, Java Script, and Python ToolsKafka, Tableau, Snowflake, etc. Skills A data engineer should have good programming and analytical skills with bigdata knowledge. A machine learning engineer should know deep learning, scaling on the cloud, working with APIs, etc.
The main objective of Impala is to provide SQL-like interactivity to bigdata analytics just like other bigdatatools - Hive, Spark SQL, Drill, HAWQ , Presto and others. Bigdatacloud service is evolving quickly and the list of supported Apache tools will keep changing over time.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















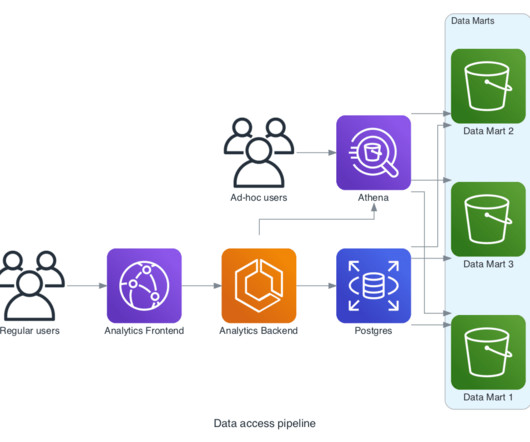
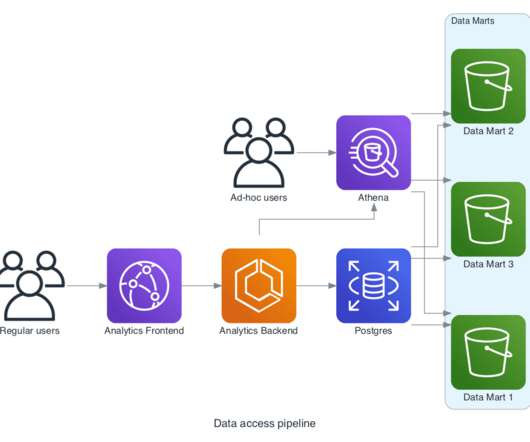





























Let's personalize your content