This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
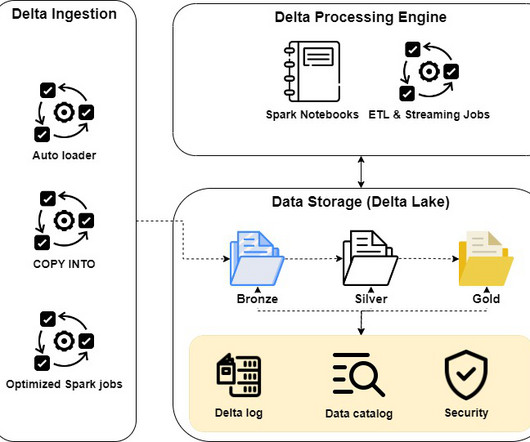
“DataLake vs Data Warehouse = Load First, Think Later vs Think First, Load Later” The terms datalake and data warehouse are frequently stumbled upon when it comes to storing large volumes of data. Data Warehouse Architecture What is a Datalake? What is a Datalake?
The fast-growing pace of bigdata volumes produced by modern data-driven systems often drives the development of bigdatatools and environments that aim to support data professionals in efficiently handling data for various purposes.
Apache Hudi 1.11.0 – This release of the well-known datalake has added many interesting changes. There’s at least one interesting twist that goes like this: “A data pipeline has five stages grouped into three heads.” Corrections in data lakehouse table format comparisons – Quasi-mutable (a.k.a.
Apache Hudi 1.11.0 – This release of the well-known datalake has added many interesting changes. There’s at least one interesting twist that goes like this: “A data pipeline has five stages grouped into three heads.” Corrections in data lakehouse table format comparisons – Quasi-mutable (a.k.a.
Who would have thought that building a data quality platform could be this challenging and exciting? Apache Hudi – The DataLake Platform – Quasi-mutable data storage formats are not only trending, but also mysterious. Follow JetBrains BigDataTools on Twitter and subscribe to our blog for more news!
In fact, 95% of organizations acknowledge the need to manage unstructured raw data since it is challenging and expensive to manage and analyze, which makes it a major concern for most businesses. In 2023, more than 5140 businesses worldwide have started using AWS Glue as a bigdatatool. How Does AWS Glue Work?
Azure Data Ingestion Pipeline Create an Azure Data Factory data ingestion pipeline to extract data from a source (e.g., Azure SQL Database, Azure DataLake Storage). Data Aggregation Working with a sample of bigdata allows you to investigate real-time data processing, bigdata project design, and data flow.
Who would have thought that building a data quality platform could be this challenging and exciting? Apache Hudi – The DataLake Platform – Quasi-mutable data storage formats are not only trending, but also mysterious. Follow JetBrains BigDataTools on Twitter and subscribe to our blog for more news!
Some of the top skills to include are: Experience with Azure data storage solutions: Azure Data Engineers should have hands-on experience with various Azure data storage solutions such as Azure Cosmos DB, Azure DataLake Storage, and Azure Blob Storage.
Here are some great articles and posts that can help inspire us all to learn from the experience of other people, teams, and companies who work in data engineering. That wraps up September’s Data Engineering Annotated. Follow JetBrains BigDataTools on Twitter and subscribe to our blog for more news!
Here are some great articles and posts that can help inspire us all to learn from the experience of other people, teams, and companies who work in data engineering. That wraps up September’s Data Engineering Annotated. Follow JetBrains BigDataTools on Twitter and subscribe to our blog for more news!
To provide end users with a variety of ready-made models, Azure Data engineers collaborate with Azure AI services built on top of Azure Cognitive Services APIs. Data engineers must therefore have a thorough understanding of programming languages like Python, Java, or Scala.
Sztanko announced at Computing’s 2016 BigData & Analytics Summit that, they are using a combination of BigDatatools to tackle the data problem. Hadoop adoption and production still rules the bigdata space. Source: [link] ) Cool new products from bigdata’s Hadoop World show.
You can leverage AWS Glue to discover, transform, and prepare your data for analytics. In addition to databases running on AWS, Glue can automatically find structured and semi-structured data kept in your datalake on Amazon S3, data warehouse on Amazon Redshift, and other storage locations.
Generally, data pipelines are created to store data in a data warehouse or datalake or provide information directly to the machine learning model development. Keeping data in data warehouses or datalakes helps companies centralize the data for several data-driven initiatives.
It serves as a foundation for the entire data management strategy and consists of multiple components including data pipelines; , on-premises and cloud storage facilities – datalakes , data warehouses , data hubs ;, data streaming and BigData analytics solutions ( Hadoop , Spark , Kafka , etc.);
Programming Language.NET and Python Python and Scala AWS Glue vs. Azure Data Factory Pricing Glue prices are primarily based on data processing unit (DPU) hours. It is important to note that both Glue and Data Factory have a free tier but offer various pricing options to help reduce costs with pay-per-activity and reserved capacity.
It provides an advanced features to process and analyze the huge amount of data in a day to day world. Why Prefer Cloud for Data Analytics? Cloud technology can be used to build entire datalakes, data warehousing, and data analytics solutions.
So, work on projects that guide you on how to build end-to-end ETL/ELT data pipelines. BigDataTools: Without learning about popular bigdatatools, it is almost impossible to complete any task in data engineering. Upload it to Azure Datalake storage manually.
We as Azure Data Engineers should have extensive knowledge of data modelling and ETL (extract, transform, load) procedures in addition to extensive expertise in creating and managing data pipelines, datalakes, and data warehouses. Using scripts, data engineers ought to be able to automate routine tasks.
The main objective of Impala is to provide SQL-like interactivity to bigdata analytics just like other bigdatatools - Hive, Spark SQL, Drill, HAWQ , Presto and others. might take some time for all the tooling to settle in an enterprise setting and become compatible with Hadoop 3.0.
Top ETL Business Use Cases for Streamlining Data Management Data Quality - ETL tools can be used for data cleansing, validation, enriching, and standardization before loading the data into a destination like a datalake or data warehouse.
This blog on BigData Engineer salary gives you a clear picture of the salary range according to skills, countries, industries, job titles, etc. BigData gets over 1.2 Several industries across the globe are using BigDatatools and technology in their processes and operations. So, let's get started!
Luckily, the situation has been gradually changing for the better with the evolution of bigdatatools and storage architectures capable of handling large datasets, no matter their type (we’ll discuss different types of data repositories later on.) The difference between data warehouses, lakes, and marts.
Learn about popular ETL tools such as Xplenty, Stitch, Alooma, and others. To store various types of data, various methods are used. It is preferable to understand when to use a datalake versus a data warehouse to create data solutions for an organisation.
ETL (extract, transform, and load) techniques move data from databases and other systems into a single hub, such as a data warehouse. Get familiar with popular ETL tools like Xplenty, Stitch, Alooma, etc. Different methods are used to store different types of data. This real-world data engineering project has three steps.
Top 100+ Data Engineer Interview Questions and Answers The following sections consist of the top 100+ data engineer interview questions divided based on bigdata fundamentals, bigdatatools/technologies, and bigdata cloud computing platforms.
Bob also hosts The Engineering Side of Data podcast , which is dedicated to discussions around data engineering and features a variety of guests from the data engineering space. His specialties include Microsoft SQL Server, Azure Databricks, Azure Data Factory, SQL Server Integration Services (SSIS), and Azure DataLake.
BigDataTools 23. Apache Hadoop: Apache's Hadoop, written in Java, has large-scale implementation over data science. This open-source software is widely accepted for its parallel data processing. You can combine it with other Microsoft data science tools like MS.
Certification provider: AWS Duration: Dedicated preparation of 2 to 3 months Cost: $300 Importance: Achieving AWS Certified Data Analytics - Specialty status is a remarkable professional accomplishment that attests to your proficiency in using AWS datalakes and analytics services to derive insights from data.
The end of a data block points to the location of the next chunk of data blocks. DataNodes store data blocks, whereas NameNodes store these data blocks. Learn more about BigDataTools and Technologies with Innovative and Exciting BigData Projects Examples. Steps for Data preparation.
Objective and Summary of the project: With so much use of online applications the inflow of data has increased exponentially. To manage all the information it is quite essential to have something like a data hub or datalake for easy access of the same.
We can use python to read the incoming data into pandas data frames and perform various checks on the data and transform the data into the required format, clean the data, validate the data, and store it into the datalake or HDFS for further processing 2) What are the challenges that you encounter when testing large datasets?
Traditional data processing technologies have presented numerous obstacles in analyzing and researching such massive amounts of data. To address these issues, BigData technologies such as Hadoop were established. These BigDatatools aided in the realization of BigData applications. .
Source : [link] ) BigDataTool For Trump’s Big Government Immigration Plans. ICM will provide ICE agents access to large amounts of data to help immigration officials discover targets and after that create and administer cases against them. iii) Zaloni introduced DataLake in a Box.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content