This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A powerful BigDatatool, Apache Hadoop alone is far from being almighty. MapReduce performs batch processing only and doesn’t fit time-sensitive data or real-time analytics jobs. Data storage options. Its in-memory processing engine allows for quick, real-time access to data stored in HDFS.
This article will discuss bigdata analytics technologies, technologies used in bigdata, and new bigdata technologies. Check out the BigData courses online to develop a strong skill set while working with the most powerful BigDatatools and technologies.
Variety : Refers to the professed formats of data, from structured, numeric data in traditional databases, to unstructured text documents, emails, videos, audios, stock ticker data and financial transactions. Some examples of BigData: 1.
They should know SQL queries, SQL Server Reporting Services (SSRS), and SQL Server Integration Services (SSIS) and a background in Data Mining and Data Warehouse Design. They are also responsible for improving the performance of data pipelines. In other words, they develop, maintain, and test BigData solutions.
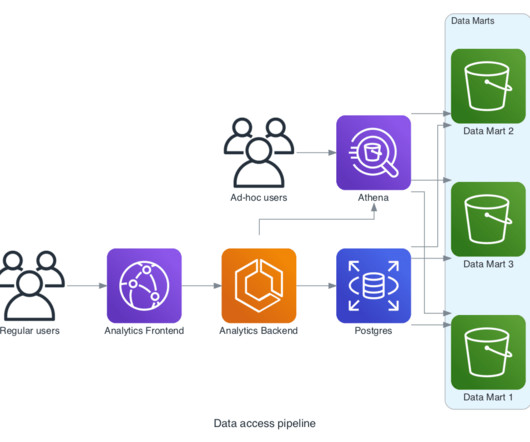
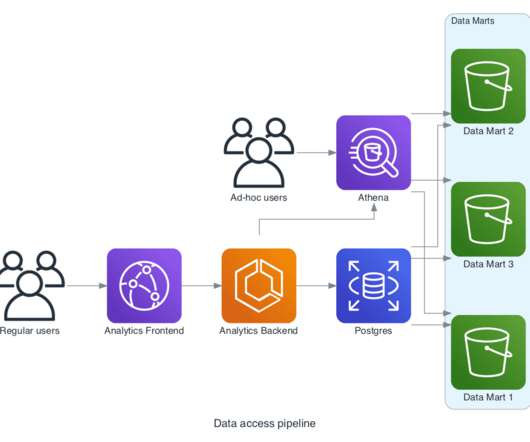
Methodology In order to meet the technical requirements for recommender system development as well as other emerging data needs, the client has built a mature data pipeline through the use of cloud platforms like AWS in order to store user clickstream data, and Databricks in order to process the raw data.
Methodology In order to meet the technical requirements for recommender system development as well as other emerging data needs, the client has built a mature data pipeline through the use of cloud platforms like AWS in order to store user clickstream data, and Databricks in order to process the raw data.
With the help of these tools, analysts can discover new insights into the data. Hadoop helps in data mining, predictive analytics, and ML applications. Why are Hadoop BigDataTools Needed? NoSQLdatabases can handle node failures. Different databases have different patterns of data storage.
Release – The first major release of NoSQLdatabase in five years! Future improvements Data engineering technologies are evolving every day. Follow JetBrains BigDataTools on Twitter and subscribe to our blog for more news! No artificial multi-tenancy and so on – Snowflake does that for you! Cassandra 4.0
Release – The first major release of NoSQLdatabase in five years! Future improvements Data engineering technologies are evolving every day. Follow JetBrains BigDataTools on Twitter and subscribe to our blog for more news! No artificial multi-tenancy and so on – Snowflake does that for you! Cassandra 4.0
Apache Hive and Apache Spark are the two popular BigDatatools available for complex data processing. To effectively utilize the BigDatatools, it is essential to understand the features and capabilities of the tools. Explore SQL Database Projects to Add them to Your Data Engineer Resume.
Hands-on experience with a wide range of data-related technologies The daily tasks and duties of a data architect include close coordination with data engineers and data scientists. It also involves creating a visual representation of data assets. Your business needs optimization of the existing databases.
A Master’s degree in Computer Science, Information Technology, Statistics, or a similar field is preferred with 2-5 years of experience in Software Engineering/Data Management/Database handling is preferred at an intermediate level. You must have good knowledge of the SQL and NoSQLdatabase systems.
You can simultaneously work on your skills, knowledge, and experience and launch your career in data engineering. Soft Skills You should have the right verbal and written communication skills required for a data engineer. Data warehousing to aggregate unstructured data collected from multiple sources.
NetworkAsia.net Hadoop is emerging as the framework of choice while dealing with bigdata. It can no longer be classified as a specialized skill, rather it has to become the enterprise data hub of choice and relational database to deliver on its promise of being the go to technology for BigData Analytics.
Ability to demonstrate expertise in database management systems. Knowledge of popular bigdatatools like Apache Spark, Apache Hadoop, etc. Good communication skills as a data engineer directly works with the different teams. You may skip chapters 11 and 12 as they are less useful for a database engineer.
You can check out the BigData Certification Online to have an in-depth idea about bigdatatools and technologies to prepare for a job in the domain. To get your business in the direction you want, you need to choose the right tools for bigdata analysis based on your business goals, needs, and variety.
BigData is a collection of large and complex semi-structured and unstructured data sets that have the potential to deliver actionable insights using traditional data management tools. Bigdata operations require specialized tools and techniques since a relational database cannot manage such a large amount of data.
Data collection revolves around gathering raw data from various sources, with the objective of using it for analysis and decision-making. It includes manual data entries, online surveys, extracting information from documents and databases, capturing signals from sensors, and more. No wonder only 0.5
The complex data activities, such as data ingestion, unification, structuring, cleaning, validating, and transforming, are made simpler by its self-service. It also makes it easier to load the data into destination databases. Tech Mahindra is among the important data analytics companies in India.
This profile is more in demand in midsize and big businesses. Database-Centric Engineer: The implementation, upkeep, and populating of analytics databases are the responsibilities of a Database-Centric Engineer. This profile is mostly seen in big organizations when data gets shared across several databases.
This closed-source software caters to a wide range of data science functionalities through its graphical interface, along with its SAS programming language, and via Base SAS. A lot of MNCs and Fortune 500 companies are utilizing this tool for statistical modeling and data analysis. BigDataTools 23.
Skills: Develop your skill set by learning new programming languages (Java, Python, Scala), as well as by mastering Apache Spark, HBase, and Hive, three bigdatatools and technologies. Think about the following tactics to increase your Hadoop Developer salary: 1.
Innovations on BigData technologies and Hadoop i.e. the Hadoop bigdatatools , let you pick the right ingredients from the data-store, organise them, and mix them. Now, thanks to a number of open source bigdata technology innovations, Hadoop implementation has become much more affordable.
Problem-Solving Abilities: Many certification courses provide projects and assessments which require hands-on practice of bigdatatools which enhances your problem solving capabilities. Networking Opportunities: While pursuing bigdata certification course you are likely to interact with trainers and other data professionals.
These companies are migrating their data and servers from on-premises to Azure Cloud. As a result, businesses always need Azure Data Engineers to monitor bigdata and other operations. Data engineers will be in high demand as long as there is data to process. According to the 2020 U.S.
Data Migration RDBMSs were inefficient and failed to manage the growing demand for current data. This failure of relational database management systems triggered organizations to move their data from RDBMS to Hadoop. Hadoop Sample Real-Time Project #8 : Facebook Data Analysis Image Source:jovian.ai
Deepanshu’s skills include SQL, data engineering, Apache Spark, ETL, pipelining, Python, and NoSQL, and he has worked on all three major cloud platforms (Google Cloud Platform, Azure, and AWS). He also has adept knowledge of coding in Python, R, SQL, and using bigdatatools such as Spark.
According to IDC, the amount of data will increase by 20 times - between 2010 and 2020, with 77% of the data relevant to organizations being unstructured. 81% of the organizations say that BigData is a top 5 IT priority.
Data Warehouse Architecture The Data Warehouse Architecture essentially consists of the following layers: Source Layer: Data warehouses collect data from multiple, heterogeneous sources. Staging Area: Once the data is collected from the external sources in the source layer, the data has to be extracted and cleaned.
Top 100+ Data Engineer Interview Questions and Answers The following sections consist of the top 100+ data engineer interview questions divided based on bigdata fundamentals, bigdatatools/technologies, and bigdata cloud computing platforms. There is a large amount of data involved.
Differentiate between Structured and Unstructured data. Data that can be stored in traditional database systems in the form of rows and columns, for example, the online purchase transactions can be referred to as Structured Data. are all examples of unstructured data. RowKey is internally regarded as a byte array.
Clickstream data is captured in semi structured web log files that contain various data elements like data and timestamp, IP address of the visitor, visitor identification number , web browser information, device information, referral page info, destination URL, etc. Implementing a BigData project on AWS.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content