This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Well, in that case, you must get hold of some excellent bigdatatools that will make your learning journey smooth and easy. Table of Contents What are BigDataTools? Why Are BigDataTools Valuable to Data Professionals? Why Are BigDataTools Valuable to Data Professionals?
They both enable you to deal with huge collections of data no matter its format — from Excel tables to user feedback on websites to images and video files. But which one of the celebrities should you entrust your information assets to? You don’t need to archive or clean data before loading. How does it work? cost-effectiveness.
However, if you're here to choose between Kafka vs. RabbitMQ, we would like to tell you this might not be the right question to ask because each of these bigdatatools excels with its architectural features, and one can make a decision as to which is the best based on the business use case. What is Kafka? What is RabbitMQ?
This blog is your ultimate gateway to transforming yourself into a skilled and successful BigData Developer, where your analytical skills will refine raw data into strategic gems. So, get ready to turn the turbulent sea of 'data chaos' into 'data artistry.' Table of Contents What is a BigData Developer?
In fact, 95% of organizations acknowledge the need to manage unstructured raw data since it is challenging and expensive to manage and analyze, which makes it a major concern for most businesses. In 2023, more than 5140 businesses worldwide have started using AWS Glue as a bigdatatool.
Programming Language.NET and Python Python and Scala AWS Glue vs. Azure Data Factory Pricing Glue prices are primarily based on data processing unit (DPU) hours. Learn more about BigDataTools and Technologies with Innovative and Exciting BigData Projects Examples. Azure Data Factory vs.
Project Idea: Learn to Build a Polynomial Regression Model from Scratch BeautifulSoup This is a well-known library used for data mining and web scraping. You will find data engineers using this to extract information from websites, dealing with JSON/HTML data formats, all for preparing their data.
Learning BigData is Full of Job Prospects and Career opportunities in the Industry. Data professionals work in several industry segments, and their contributions apply to all industries. You can work in any sector, including finance, manufacturing, information technology, telecommunications, retail, logistics, and automotive.
With the global data volume projected to surge from 120 zettabytes in 2023 to 181 zettabytes by 2025, PySpark's popularity is soaring as it is an essential tool for efficient large scale data processing and analyzing vast datasets. The core engine for large-scale distributed and parallel data processing is SparkCore.
With so much information available, it can be overwhelming to know where to begin. This Spark book will teach you the spark application architecture , how to develop Spark applications in Scala and Python, and RDD, SparkSQL, and APIs. Indeed recently posted nearly 2.4k But where do you start?
It involves various technical skills, including database design, data modeling, and ETL (Extract, Transform, Load) processes. Data engineering is a critical function in modern organizations, as it allows companies to extract insights from large volumes of data and make informed decisions.
Bigdata in information technology is used to improve operations, provide better customer service, develop customized marketing campaigns, and take other actions to increase revenue and profits. It is especially true in the world of bigdata. What Is a BigDataTool?
Are you interested in becoming a data architect? Check out this career guide for the most up-to-date information about the role, skills, education, salary, and possible employment information to get you started in this exciting field. Develop application programming interfaces (APIs) for data retrieval.
Project Idea : Build a data pipeline to ingest data from APIs like CoinGecko or Kaggle’s crypto datasets. Fetch live data using the CoinMarketCap API to monitor cryptocurrency prices. This project is an opportunity for data enthusiasts to engage in the information produced and used by the New York City government.
As we step into the latter half of the present decade, we can’t help but notice the way BigData has entered all crucial technology-powered domains such as banking and financial services, telecom, manufacturing, information technology, operations, and logistics.
Transport for London, on the other hand, uses statistical data to map passenger journeys, manage unforeseen scenarios, and provide passengers with customized transportation information. Every sector these days uses data science techniques to improve its operational performances. A solid grasp of natural language processing.
If you're looking to break into the exciting field of bigdata or advance your bigdata career, being well-prepared for bigdata interview questions is essential. Get ready to expand your knowledge and take your bigdata career to the next level! Everything is about data these days.
Additionally, the Tree view has been replaced by the Grid view, which, in my opinion, is much more informative. Apache Hudi 1.11.0 – This release of the well-known data lake has added many interesting changes. The team has also added the ability to run Scala for the SparkSQL engine.
Additionally, the Tree view has been replaced by the Grid view, which, in my opinion, is much more informative. Apache Hudi 1.11.0 – This release of the well-known data lake has added many interesting changes. The team has also added the ability to run Scala for the SparkSQL engine.
Data Engineering Project You Must Explore Once you have completed this fundamental course, you must try working on the Hadoop Project to Perform Hive Analytics using SQL and Scala to help you brush up your skills. Then, explore specialized data engineering courses and certifications online. Oh wait, there’s more!
By the way, we have a video dedicated to the data engineering working principles. Look behind the scenes of the data engineering process Data architect vs data analyst A data analyst is a specialist that makes sense of information provided by a data engineer and finds answers to the questions a business is concerned with.
In fact, 95% of organizations acknowledge the need to manage unstructured raw data since it is challenging and expensive to manage and analyze, which makes it a major concern for most businesses. In 2023, more than 5140 businesses worldwide have started using AWS Glue as a bigdatatool.
Data engineering entails creating and developing data collection, storage, and analysis systems. Data engineers create systems that gather, analyze, and transform raw data into useful information. Data engineers play a significant role in the bigdata industry and are in high demand.
It is an enhanced version of the Azure SQL data warehouse encompassing additional workflow stages and allows users to generate reports and visualizations. It supports various programming languages, including SQL , Python,NET, Java, Scala , and R, making it highly suitable for diverse analysis workloads and engineering profiles.
Embarking on the journey of bigdata opens up a world of amazing career opportunities that can make a difference in people's lives. 2023 is the best time to explore this exciting field by pursuing the top bigdata certifications. Understanding of parallel processing and data architecture patterns. And guess what?
Here’s what’s happening in data engineering right now. Apache Spark already has two official APIs for JVM – Scala and Java – but we’re hoping the Kotlin API will be useful as well, as we’ve introduced several unique features. Now you don’t need smart logic to allow specific people to query and view specific information.
Here’s what’s happening in data engineering right now. Apache Spark already has two official APIs for JVM – Scala and Java – but we’re hoping the Kotlin API will be useful as well, as we’ve introduced several unique features. Now you don’t need smart logic to allow specific people to query and view specific information.
You may thoroughly explore various AWS services while studying for the exam and discover best practises for developing and deploying bigdata solutions. You get in-depth information and practical experience via this process, which helps you become a more well-rounded professional.
Data analytics or data analysis tools refer to software and programs used by data analysts to develop and perform analytic activities that support companies in making better, more informed business decisions while lowering costs and increasing profits.
They typically work with structured data to prepare reports that can easily indicate the trends and insights and can be understood by users who are not experts in the field to informdata-driven decisions. They also make use of ETL tools, messaging systems like Kafka, and BigDataTool kits such as SparkML and Mahout.
You ought to be able to create a data model that is performance- and scalability-optimized. Programming and Scripting Skills Building data processing pipelines requires knowledge of and experience with coding in programming languages like Python, Scala, or Java.
Programming Language.NET and Python Python and Scala AWS Glue vs. Azure Data Factory Pricing Glue prices are primarily based on data processing unit (DPU) hours. Learn more about BigDataTools and Technologies with Innovative and Exciting BigData Projects Examples. Azure Data Factory vs.
You can pick any of these cloud computing project ideas to develop and improve your skills in the field of cloud computing along with other bigdata technologies. It typically showcases basic information without dynamic or interactive elements, such as text, images, and multimedia.
Problem-Solving Abilities: Many certification courses provide projects and assessments which require hands-on practice of bigdatatools which enhances your problem solving capabilities. Networking Opportunities: While pursuing bigdata certification course you are likely to interact with trainers and other data professionals.
Where is the meta-information about topics stored in the Kafka cluster? Currently, in Apache Kafka, meta-information about topics is stored in the ZooKeeper. Information regarding the location of the partitions and the configuration details related to a topic are stored in the ZooKeeper in a separate Kafka cluster.
With so much information available, it can be overwhelming to know where to begin. This Spark book will teach you the spark application architecture , how to develop Spark applications in Scala and Python, and RDD, SparkSQL, and APIs. Indeed recently posted nearly 2.4k But where do you start?
In addition to databases running on AWS, Glue can automatically find structured and semi-structured data kept in your data lake on Amazon S3, data warehouse on Amazon Redshift, and other storage locations. Furthermore, AWS Glue DataBrew allows you to visually clean and normalize data without any code.
In addition to databases running on AWS, Glue can automatically find structured and semi-structured data kept in your data lake on Amazon S3, data warehouse on Amazon Redshift, and other storage locations. Furthermore, AWS Glue DataBrew allows you to visually clean and normalize data without any code.
Already familiar with the term bigdata, right? Despite the fact that we would all discuss BigData, it takes a very long time before you confront it in your career. Apache Spark is a BigDatatool that aims to handle large datasets in a parallel and distributed manner.
Data engineers work on the data to organize and make it usable with the aid of cloud services. Data Engineers and Data Scientists have the highest average salaries, respectively, according to PayScale. Azure data engineer certification pathgives detailed information about the same.
Therefore, keeping up with the latest trends and frameworks and taking online courses like Data Science course review is important. Let's find out the differences between a data scientist and a machine learning engineer below to make an informative decision. Apache Spark, Microsoft Azure, Amazon Web services, etc.
Proficiency in programming languages: Knowledge of programming languages such as Python and SQL is essential for Azure Data Engineers. Familiarity with cloud-based analytics and bigdatatools: Experience with cloud-based analytics and bigdatatools such as Apache Spark, Apache Hive, and Apache Storm is highly desirable.
However, if you're here to choose between Kafka vs. RabbitMQ, we would like to tell you this might not be the right question to ask because each of these bigdatatools excels with its architectural features, and one can make a decision as to which is the best based on the business use case. What is Kafka? What is RabbitMQ?
PySpark runs a completely compatible Python instance on the Spark driver (where the task was launched) while maintaining access to the Scala-based Spark cluster access. Although Spark was originally created in Scala, the Spark Community has published a new tool called PySpark, which allows Python to be used with Spark.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























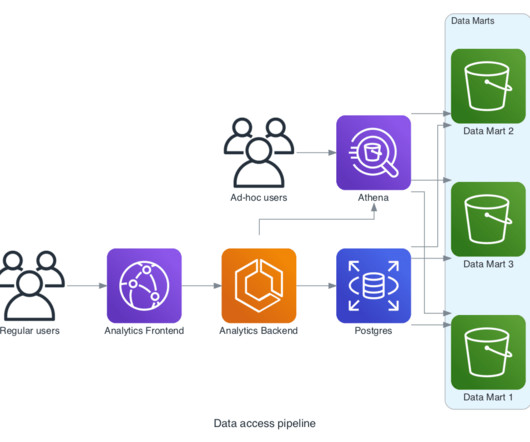
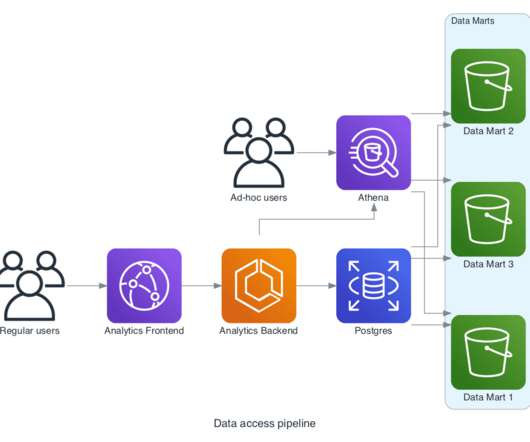























Let's personalize your content