This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A powerful BigDatatool, Apache Hadoop alone is far from being almighty. The module can absorb live data streams from Apache Kafka , Apache Flume , Amazon Kinesis , Twitter, and other sources and process them as micro-batches. Just for reference, Spark Streaming and Kafka combo is used by.
This article will discuss bigdata analytics technologies, technologies used in bigdata, and new bigdata technologies. Check out the BigData courses online to develop a strong skill set while working with the most powerful BigDatatools and technologies.
As a bigdata architect or a bigdata developer, when working with Microservices-based systems, you might often end up in a dilemma whether to use Apache Kafka or RabbitMQ for messaging. Rabbit MQ vs. Kafka - Which one is a better message broker? What is Kafka? Why Kafka vs RabbitMQ ?
Rack-aware Kafka streams – Kafka has already been rack-aware for a while, which gives its users more confidence. When data is replicated between different racks housed in different locations, if anything bad happens to one rack, it won’t happen to another. Flink plans to add support for async sinks to address this question.
Rack-aware Kafka streams – Kafka has already been rack-aware for a while, which gives its users more confidence. When data is replicated between different racks housed in different locations, if anything bad happens to one rack, it won’t happen to another. Flink plans to add support for async sinks to address this question.
Kafka was the first, and soon enough, everybody was trying to grab their own share of the market. In the case of RocketMQ, their attempt is very interesting because, unlike Kafka and Pulsar, RocketMQ is closer to traditional MQs like ActiveMQ (which isn’t really surprising, seeing how it’s based on ActiveMQ).
Kafka was the first, and soon enough, everybody was trying to grab their own share of the market. In the case of RocketMQ, their attempt is very interesting because, unlike Kafka and Pulsar, RocketMQ is closer to traditional MQs like ActiveMQ (which isn’t really surprising, seeing how it’s based on ActiveMQ).
It hasn’t had its first release yet, but the promise is that it will un-bias your data for you! rc0 – If you like to try new releases of popular products, the time has come to test Kafka 3 and report any issues you find on your staging environment! Change Data Capture at DeviantArt – I think we all know what Debezium is.
Kafka: Mark KRaft as Production Ready – One of the most interesting changes to Kafka from recent years is that it now works without ZooKeeper. This is possible thanks to implementations of KRaft, a Raft consensus protocol designed specifically for the needs of Kafka. Of course, the main topic is data streaming.
Kafka: Mark KRaft as Production Ready – One of the most interesting changes to Kafka from recent years is that it now works without ZooKeeper. This is possible thanks to implementations of KRaft, a Raft consensus protocol designed specifically for the needs of Kafka. Of course, the main topic is data streaming.
Zingg is a tool that integrates with Spark and tries to answer this question automatically, without the quadratic complexity of the task! Kafka 3.0.0 – The Apache Software Foundation needed less than one month to go from Kafka version 3.0.0-rc0 That wraps up September’s Data Engineering Annotated.
Zingg is a tool that integrates with Spark and tries to answer this question automatically, without the quadratic complexity of the task! Kafka 3.0.0 – The Apache Software Foundation needed less than one month to go from Kafka version 3.0.0-rc0 That wraps up September’s Data Engineering Annotated.
It’s developed by LinkedIn, which means it has very tight integrations with other LinkedIn tools, like Apache Kafka! This release brings 2 big features: Segment Merge and Rollup, both of which can be used for better (i.e. And, unlike Kafka, it doesn’t need ZooKeeper and it supports message scheduling! Apache Pinot 0.9.0
It’s developed by LinkedIn, which means it has very tight integrations with other LinkedIn tools, like Apache Kafka! This release brings 2 big features: Segment Merge and Rollup, both of which can be used for better (i.e. And, unlike Kafka, it doesn’t need ZooKeeper and it supports message scheduling! Apache Pinot 0.9.0
There are also multiple improvements for streaming support (for Kafka and Kinesis ), along with many other changes. It wouldn’t be quite right to call it “Kafka on steroids” because it includes lots of batteries. Of course, the main topic is data streaming, as always. That wraps up June’s Data Engineering Annotated.
There are also multiple improvements for streaming support (for Kafka and Kinesis ), along with many other changes. It wouldn’t be quite right to call it “Kafka on steroids” because it includes lots of batteries. Of course, the main topic is data streaming, as always. That wraps up June’s Data Engineering Annotated.
Future improvements Data engineering technologies are evolving every day. Kafka: Allow configuring num.network.threads per listener – Sometimes you find yourself in a situation with Kafka brokers where some listeners are less active than others (and are in some sense more equal than others).
Future improvements Data engineering technologies are evolving every day. Kafka: Allow configuring num.network.threads per listener – Sometimes you find yourself in a situation with Kafka brokers where some listeners are less active than others (and are in some sense more equal than others).
Your search for Apache Kafka interview questions ends right here! Let us now dive directly into the Apache Kafka interview questions and answers and help you get started with your BigData interview preparation! How to study for Kafka interview? What is Kafka used for? What are main APIs of Kafka?
One of the use cases from the product page that stood out to me in particular was the effort to mirror multiple Kafka clusters in one Brooklin cluster! Ambry v0.3.870 – It turns out that last month was rich in releases from LinkedIn, all of them related in one way or another to data engineering. This is no doubt very interesting.
One of the use cases from the product page that stood out to me in particular was the effort to mirror multiple Kafka clusters in one Brooklin cluster! Ambry v0.3.870 – It turns out that last month was rich in releases from LinkedIn, all of them related in one way or another to data engineering. This is no doubt very interesting.
It hasn’t had its first release yet, but the promise is that it will un-bias your data for you! rc0 – If you like to try new releases of popular products, the time has come to test Kafka 3 and report any issues you find on your staging environment! Change Data Capture at DeviantArt – I think we all know what Debezium is.
Kafka: The Next Generation of the Consumer Rebalance Protocol – The current rebalance protocol in Kafka has existed for a long time. That wraps up October’s Data Engineering Annotated. Follow JetBrains BigDataTools on Twitter and subscribe to our blog for more news!
Kafka: The Next Generation of the Consumer Rebalance Protocol – The current rebalance protocol in Kafka has existed for a long time. That wraps up October’s Data Engineering Annotated. Follow JetBrains BigDataTools on Twitter and subscribe to our blog for more news!
It serves as a foundation for the entire data management strategy and consists of multiple components including data pipelines; , on-premises and cloud storage facilities – data lakes , data warehouses , data hubs ;, data streaming and BigData analytics solutions ( Hadoop , Spark , Kafka , etc.);
So, work on projects that guide you on how to build end-to-end ETL/ELT data pipelines. BigDataTools: Without learning about popular bigdatatools, it is almost impossible to complete any task in data engineering. Finally, the data is published and visualized on a Java-based custom Dashboard.
Problem-Solving Abilities: Many certification courses provide projects and assessments which require hands-on practice of bigdatatools which enhances your problem solving capabilities. Networking Opportunities: While pursuing bigdata certification course you are likely to interact with trainers and other data professionals.
Amazon Web Service (AWS) offers the Amazon Kinesis service to process a vast amount of data, including, but not limited to, audio, video, website clickstreams, application logs, and IoT telemetry, every second in real-time. Compared to BigDatatools, Amazon Kinesis is automated and fully managed.
In other words, you will write codes to carry out one step at a time and then feed the desired data into machine learning models for training sentimental analysis models or evaluating sentiments of reviews, depending on the use case. You can use big-data processing tools like Apache Spark , Kafka , and more to create such pipelines.
Innovations on BigData technologies and Hadoop i.e. the Hadoop bigdatatools , let you pick the right ingredients from the data-store, organise them, and mix them. Now, thanks to a number of open source bigdata technology innovations, Hadoop implementation has become much more affordable.
Proficiency in programming languages: Knowledge of programming languages such as Python and SQL is essential for Azure Data Engineers. Familiarity with cloud-based analytics and bigdatatools: Experience with cloud-based analytics and bigdatatools such as Apache Spark, Apache Hive, and Apache Storm is highly desirable.
As a BigData Engineer, you shall also know and understand the BigData architecture and BigDatatools. Hadoop , Kafka , and Spark are the most popular bigdatatools used in the industry today. You shall look to expand your skills to become a BigData Engineer.
Data Aggregation Working with a sample of bigdata allows you to investigate real-time data processing, bigdata project design, and data flow. Learn how to aggregate real-time data using several bigdatatools like Kafka, Zookeeper, Spark, HBase, and Hadoop.
The Schema Registry supports Java client apps and the Apache Avro and JSON Schema data formats. The Schema Registry is compatible with apps made for Apache Kafka, Amazon Managed Streaming for Apache Kafka (MSK), Amazon Kinesis Data Streams, Apache Flink, Amazon Kinesis Data Analytics for Apache Flink, and AWS Lambda.
Languages Python, SQL, Java, Scala R, C++, Java Script, and Python ToolsKafka, Tableau, Snowflake, etc. Skills A data engineer should have good programming and analytical skills with bigdata knowledge. The ML engineers act as a bridge between software engineering and data science.
They use technologies like Storm or Spark, HDFS, MapReduce, Query Tools like Pig, Hive, and Impala, and NoSQL Databases like MongoDB, Cassandra, and HBase. They also make use of ETL tools, messaging systems like Kafka, and BigDataTool kits such as SparkML and Mahout.
Features of PySpark Features that contribute to PySpark's immense popularity in the industry- Real-Time Computations PySpark emphasizes in-memory processing, which allows it to perform real-time computations on huge volumes of data. PySpark is used to process real-time data with Kafka and Streaming, and this exhibits low latency.
The main objective of Impala is to provide SQL-like interactivity to bigdata analytics just like other bigdatatools - Hive, Spark SQL, Drill, HAWQ , Presto and others. The massively parallel processing engine born at Cloudera acquired the status of a top-level project within the Apache Foundation.
is looking to churn more data in place and share BI analytics of the data within and outside the organization.To enhance the efficiency, Count Komatsu has combined several bigdatatools that include Spark, Hadoop, Kafka , Kudu, and Impala from Cloudera.
If you have not sharpened your bigdata skills then you will likely get the boot, as your company will start looking for developers with Hadoop experience. These bigdata skills not only help you move up your ranks in the current position, but they will make you more marketable with big paychecks.
Data engineers don’t just work with traditional data; they’re frequently tasked with handling massive amounts of data. A data engineer should be familiar with popular BigDatatools and technologies such as Hadoop, MongoDB, and Kafka.
Data engineers must therefore have a thorough understanding of programming languages like Python, Java, or Scala. Candidates looking for Azure data engineering positions should also be familiar with bigdatatools like Hadoop.
Using scripts, data engineers ought to be able to automate routine tasks. Data engineers handle vast volumes of data on a regular basis and don't only deal with normal data. Popular BigDatatools and technologies that a data engineer has to be familiar with include Hadoop, MongoDB, and Kafka.
You should be thorough with technicalities related to relational and non-relational databases, Data security, ETL (extract, transform, and load) systems, Data storage, automation and scripting, bigdatatools, and machine learning.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




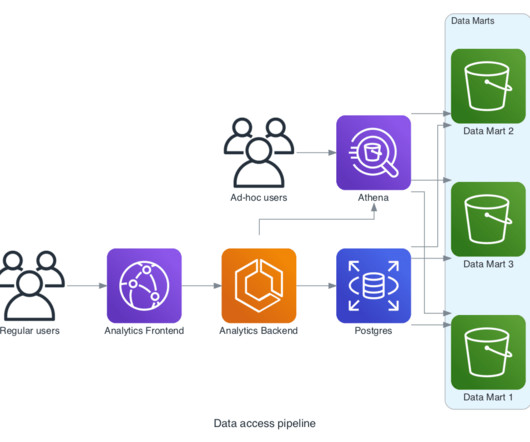
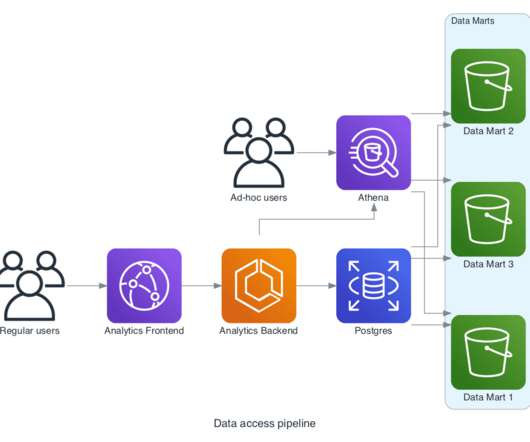













































Let's personalize your content