This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As a bigdata architect or a bigdata developer, when working with Microservices-based systems, you might often end up in a dilemma whether to use Apache Kafka or RabbitMQ for messaging. Rabbit MQ vs. Kafka - Which one is a better message broker? What is Kafka? Why Kafka vs RabbitMQ ?
Well, in that case, you must get hold of some excellent bigdatatools that will make your learning journey smooth and easy. Table of Contents What are BigDataTools? Why Are BigDataTools Valuable to Data Professionals? Why Are BigDataTools Valuable to Data Professionals?
Your search for Apache Kafka interview questions ends right here! Let us now dive directly into the Apache Kafka interview questions and answers and help you get started with your BigData interview preparation! What are topics in Apache Kafka? Kafka stores data in topics that are split into partitions.
A powerful BigDatatool, Apache Hadoop alone is far from being almighty. The module can absorb live data streams from Apache Kafka , Apache Flume , Amazon Kinesis , Twitter, and other sources and process them as micro-batches. Just for reference, Spark Streaming and Kafka combo is used by.
Larger organizations and those in industries heavily reliant on data, such as finance, healthcare, and e-commerce, often pay higher salaries to attract top BigData talent. Developers who can work with structured and unstructured data and use machine learning and data visualization tools are highly sought after.
Project Idea : Build a data pipeline to ingest data from APIs like CoinGecko or Kaggle’s crypto datasets. Fetch live data using the CoinMarketCap API to monitor cryptocurrency prices. Use Kafka for real-time data ingestion, preprocess with Apache Spark, and store data in Snowflake.
With the global data volume projected to surge from 120 zettabytes in 2023 to 181 zettabytes by 2025, PySpark's popularity is soaring as it is an essential tool for efficient large scale data processing and analyzing vast datasets. The core engine for large-scale distributed and parallel data processing is SparkCore.
And for fulfilling this need, data engineers have to work in teams and extract data from various sources, transform it into a reliable form, and load that into the systems other teams of data science professionals can use to build other relevant applications.
Features of PySpark Features that contribute to PySpark's immense popularity in the industry- Real-Time Computations PySpark emphasizes in-memory processing, which allows it to perform real-time computations on huge volumes of data. PySpark is used to process real-time data with Kafka and Streaming, and this exhibits low latency.
It plays a key role in streaming in the form of Spark Streaming libraries, interactive analytics in the form of SparkSQL and also provides libraries for machine learning that can be imported using Python or Scala. In this project, you will work on preparing a real-time analytics dashboard using popular BigDatatools.
This article will discuss bigdata analytics technologies, technologies used in bigdata, and new bigdata technologies. Check out the BigData courses online to develop a strong skill set while working with the most powerful BigDatatools and technologies.
Data Engineering is the secret sauce to advances in data analysis and data science that we see nowadays. Data Engineering Roles - Who Handles What? As we can see, it turns out that the data engineering role requires a vast knowledge of different bigdatatools and technologies.
As a bigdata architect or a bigdata developer, when working with Microservices-based systems, you might often end up in a dilemma whether to use Apache Kafka or RabbitMQ for messaging. Rabbit MQ vs. Kafka - Which one is a better message broker? What is Kafka? Why Kafka vs RabbitMQ ?
The team has also added the ability to run Scala for the SparkSQL engine. Kafka was the first, and soon enough, everybody was trying to grab their own share of the market. Kafka: Shareable State Stores – This improvement in Kafka looks very interesting. That wraps up April’s Data Engineering Annotated.
The team has also added the ability to run Scala for the SparkSQL engine. Kafka was the first, and soon enough, everybody was trying to grab their own share of the market. Kafka: Shareable State Stores – This improvement in Kafka looks very interesting. That wraps up April’s Data Engineering Annotated.
Here’s what’s happening in data engineering right now. Apache Spark already has two official APIs for JVM – Scala and Java – but we’re hoping the Kotlin API will be useful as well, as we’ve introduced several unique features. 5 Reasons to Choose Pulsar Over Kafka – The author states his bias upfront, which is nice.
Here’s what’s happening in data engineering right now. Apache Spark already has two official APIs for JVM – Scala and Java – but we’re hoping the Kotlin API will be useful as well, as we’ve introduced several unique features. 5 Reasons to Choose Pulsar Over Kafka – The author states his bias upfront, which is nice.
It hasn’t had its first release yet, but the promise is that it will un-bias your data for you! rc0 – If you like to try new releases of popular products, the time has come to test Kafka 3 and report any issues you find on your staging environment! Support for Scala 2.12 How cool is that? That wraps up August’s Annotated.
Also, this release is compatible with Scala 2.13 – the latest stable language release before the 3.x Future improvements Data engineering technologies are evolving every day. That wraps up October’s Data Engineering Annotated. Follow JetBrains BigDataTools on Twitter and subscribe to our blog for more news!
Also, this release is compatible with Scala 2.13 – the latest stable language release before the 3.x Future improvements Data engineering technologies are evolving every day. That wraps up October’s Data Engineering Annotated. Follow JetBrains BigDataTools on Twitter and subscribe to our blog for more news!
It serves as a foundation for the entire data management strategy and consists of multiple components including data pipelines; , on-premises and cloud storage facilities – data lakes , data warehouses , data hubs ;, data streaming and BigData analytics solutions ( Hadoop , Spark , Kafka , etc.);
Problem-Solving Abilities: Many certification courses provide projects and assessments which require hands-on practice of bigdatatools which enhances your problem solving capabilities. Networking Opportunities: While pursuing bigdata certification course you are likely to interact with trainers and other data professionals.
It hasn’t had its first release yet, but the promise is that it will un-bias your data for you! rc0 – If you like to try new releases of popular products, the time has come to test Kafka 3 and report any issues you find on your staging environment! Support for Scala 2.12 How cool is that? That wraps up August’s Annotated.
Your search for Apache Kafka interview questions ends right here! Let us now dive directly into the Apache Kafka interview questions and answers and help you get started with your BigData interview preparation! How to study for Kafka interview? What is Kafka used for? What are main APIs of Kafka?
In addition to databases running on AWS, Glue can automatically find structured and semi-structured data kept in your data lake on Amazon S3, data warehouse on Amazon Redshift, and other storage locations. Furthermore, AWS Glue DataBrew allows you to visually clean and normalize data without any code.
In addition to databases running on AWS, Glue can automatically find structured and semi-structured data kept in your data lake on Amazon S3, data warehouse on Amazon Redshift, and other storage locations. Furthermore, AWS Glue DataBrew allows you to visually clean and normalize data without any code.
Languages Python, SQL, Java, Scala R, C++, Java Script, and Python ToolsKafka, Tableau, Snowflake, etc. Skills A data engineer should have good programming and analytical skills with bigdata knowledge. The ML engineers act as a bridge between software engineering and data science.
You ought to be able to create a data model that is performance- and scalability-optimized. Programming and Scripting Skills Building data processing pipelines requires knowledge of and experience with coding in programming languages like Python, Scala, or Java.
They use technologies like Storm or Spark, HDFS, MapReduce, Query Tools like Pig, Hive, and Impala, and NoSQL Databases like MongoDB, Cassandra, and HBase. They also make use of ETL tools, messaging systems like Kafka, and BigDataTool kits such as SparkML and Mahout.
Proficiency in programming languages: Knowledge of programming languages such as Python and SQL is essential for Azure Data Engineers. Familiarity with cloud-based analytics and bigdatatools: Experience with cloud-based analytics and bigdatatools such as Apache Spark, Apache Hive, and Apache Storm is highly desirable.
Innovations on BigData technologies and Hadoop i.e. the Hadoop bigdatatools , let you pick the right ingredients from the data-store, organise them, and mix them. Now, thanks to a number of open source bigdata technology innovations, Hadoop implementation has become much more affordable.
Features of PySpark Features that contribute to PySpark's immense popularity in the industry- Real-Time Computations PySpark emphasizes in-memory processing, which allows it to perform real-time computations on huge volumes of data. PySpark is used to process real-time data with Kafka and Streaming, and this exhibits low latency.
Here are some role-specific skills you should consider to become an Azure data engineer- Most data storage and processing systems use programming languages. Data engineers must thoroughly understand programming languages such as Python, Java, or Scala. What is the most popular Azure Certification?
We as Azure Data Engineers should have extensive knowledge of data modelling and ETL (extract, transform, load) procedures in addition to extensive expertise in creating and managing data pipelines, data lakes, and data warehouses. Learn about well-known ETL tools such as Xplenty, Stitch, Alooma, etc.
Here are some role-specific skills to consider if you want to become an Azure data engineer: Programming languages are used in the majority of data storage and processing systems. Data engineers must be well-versed in programming languages such as Python, Java, and Scala.
Other Competencies You should have proficiency in coding languages like SQL, NoSQL, Python, Java, R, and Scala. You should be thorough with technicalities related to relational and non-relational databases, Data security, ETL (extract, transform, and load) systems, Data storage, automation and scripting, bigdatatools, and machine learning.
Here are some role-specific skills you should consider to become an Azure data engineer- Most data storage and processing systems use programming languages. Data engineers must thoroughly understand programming languages such as Python, Java, or Scala. What is the most popular Azure Certification?
PySpark runs a completely compatible Python instance on the Spark driver (where the task was launched) while maintaining access to the Scala-based Spark cluster access. Although Spark was originally created in Scala, the Spark Community has published a new tool called PySpark, which allows Python to be used with Spark.
Furthermore, you will find a few sections on data engineer interview questions commonly asked in various companies leveraging the power of bigdata and data engineering. It involves creating a visual representation of an entire system of data or a part of it. What is a case class in Scala?
It plays a key role in streaming in the form of Spark Streaming libraries, interactive analytics in the form of SparkSQL and also provides libraries for machine learning that can be imported using Python or Scala. In this project, you will work on preparing a real-time analytics dashboard using popular BigDatatools.
Apache Spark is the most active open bigdatatool reshaping the bigdata market and has reached the tipping point in 2015.Wikibon Wikibon analysts predict that Apache Spark will account for one third (37%) of all the bigdata spending in 2022. Partitions in Spark do not span multiple machines.
He currently runs a YouTube channel, E-Learning Bridge , focused on video tutorials for aspiring data professionals and regularly shares advice on data engineering, developer life, careers, motivations, and interviewing on LinkedIn. He also has adept knowledge of coding in Python, R, SQL, and using bigdatatools such as Spark.
Top 100+ Data Engineer Interview Questions and Answers The following sections consist of the top 100+ data engineer interview questions divided based on bigdata fundamentals, bigdatatools/technologies, and bigdata cloud computing platforms. What is a case class in Scala?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















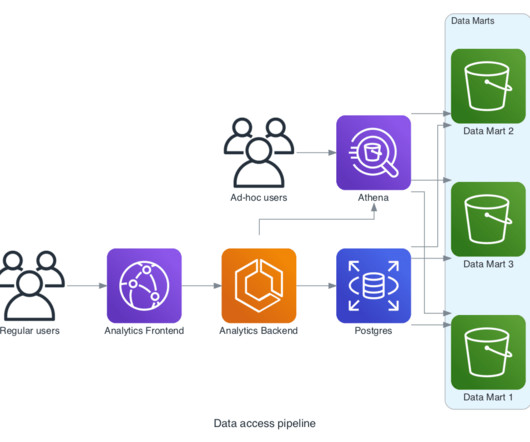
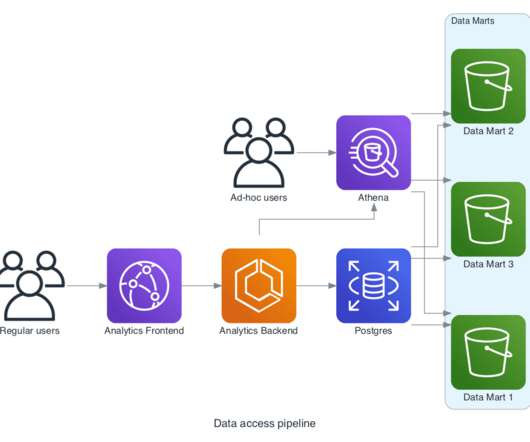






























Let's personalize your content