This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Methodology In order to meet the technical requirements for recommender system development as well as other emerging data needs, the client has built a mature data pipeline through the use of cloud platforms like AWS in order to store user clickstream data, and Databricks in order to process the rawdata.
Methodology In order to meet the technical requirements for recommender system development as well as other emerging data needs, the client has built a mature data pipeline through the use of cloud platforms like AWS in order to store user clickstream data, and Databricks in order to process the rawdata.
The first step is to work on cleaning it and eliminating the unwanted information in the dataset so that data analysts and data scientists can use it for analysis. That needs to be done because rawdata is painful to read and work with. Knowledge of popular bigdatatools like Apache Spark, Apache Hadoop, etc.
As a BigData Engineer, you shall also know and understand the BigData architecture and BigDatatools. Hadoop , Kafka , and Spark are the most popular bigdatatools used in the industry today. You shall look to expand your skills to become a BigData Engineer.
In fact, 95% of organizations acknowledge the need to manage unstructured rawdata since it is challenging and expensive to manage and analyze, which makes it a major concern for most businesses. In 2023, more than 5140 businesses worldwide have started using AWS Glue as a bigdatatool.
Keeping data in data warehouses or data lakes helps companies centralize the data for several data-driven initiatives. While data warehouses contain transformed data, data lakes contain unfiltered and unorganized rawdata.
The collection of meaningful market data has become a critical component of maintaining consistency in businesses today. A company can make the right decision by organizing a massive amount of rawdata with the right data analytic tool and a professional data analyst. What Is BigData Analytics?
Data Science is the field that focuses on gathering data from multiple sources using different tools and techniques. Whereas, Business Intelligence is the set of technologies and applications that are helpful in drawing meaningful information from rawdata.
Factors Data Engineer Machine Learning Definition Data engineers create, maintain, and optimize data infrastructure for data. In addition, they are responsible for developing pipelines that turn rawdata into formats that data consumers can use easily.
Using Hive SQL professionals can use Hadoop like a data warehouse. Hive allows professionals with SQL skills to query the data using a SQL like syntax making it an ideal bigdatatool for integrating Hadoop and other BI tools.
You have probably heard the saying, "data is the new oil". It is extremely important for businesses to process data correctly since the volume and complexity of rawdata are rapidly growing. ETL fully automates the data extraction and can collect data from various sources to assess potential opponents and competitors.
Innovations on BigData technologies and Hadoop i.e. the Hadoop bigdatatools , let you pick the right ingredients from the data-store, organise them, and mix them. Now, thanks to a number of open source bigdata technology innovations, Hadoop implementation has become much more affordable.
Within no time, most of them are either data scientists already or have set a clear goal to become one. Nevertheless, that is not the only job in the data world. And, out of these professions, this blog will discuss the data engineering job role. Ability to adapt to new bigdatatools and technologies.
Data collection revolves around gathering rawdata from various sources, with the objective of using it for analysis and decision-making. It includes manual data entries, online surveys, extracting information from documents and databases, capturing signals from sensors, and more. No wonder only 0.5
Entry-level data engineers make about $77,000 annually when they start, rising to about $115,000 as they become experienced. Roles and Responsibilities of Data Engineer Analyze and organize rawdata. Build data systems and pipelines. Conduct complex data analysis and report on results.
Bigdata operations require specialized tools and techniques since a relational database cannot manage such a large amount of data. Bigdata enables businesses to gain a deeper understanding of their industry and helps them extract valuable information from the unstructured and rawdata that is regularly collected.
Data Analytics tools and technologies offer opportunities and challenges for analyzing data efficiently so you can better understand customer preferences, gain a competitive advantage in the marketplace, and grow your business. What is Data Analytics?
Data Lake vs Data Warehouse - Data Timeline Data lakes retain all data, including data that is not currently in use. Hence, data can be kept in data lakes for all times, to be usfurther analyse the data. Rawdata is allowed to flow into a data lake, sometimes with no immediate use.
Apache Pig bigdatatools, is used in particular for iterative processing, research on rawdata and for traditional ETL data pipelines. 14) What are some of the Apache Pig use cases you can think of?
Bigdata technologies used: Microsoft Azure, Azure Data Factory, Azure Databricks, Spark BigData Architecture: This sample Hadoop real-time project starts off by creating a resource group in azure. To this group, we add a storage account and move the rawdata.
Top 100+ Data Engineer Interview Questions and Answers The following sections consist of the top 100+ data engineer interview questions divided based on bigdata fundamentals, bigdatatools/technologies, and bigdata cloud computing platforms.
Data that can be stored in traditional database systems in the form of rows and columns, for example, the online purchase transactions can be referred to as Structured Data. Data that can be stored only partially in traditional database systems, for example, data in XML records can be referred to as semi-structured data.
Traditional data processing technologies have presented numerous obstacles in analyzing and researching such massive amounts of data. To address these issues, BigData technologies such as Hadoop were established. These BigDatatools aided in the realization of BigData applications. .
Data Cleaning: To improve the data quality and filter the noisy, inaccurate, and irrelevant data for analysis, data cleaning is a key skill needed for all analytics job roles. Microsoft Excel: A successful Excel spreadsheet helps to organize rawdata into a more readable format.
Ace your bigdata interview by adding some unique and exciting BigData projects to your portfolio. This blog lists over 20 bigdata projects you can work on to showcase your bigdata skills and gain hands-on experience in bigdatatools and technologies.
Stream Processing A widespread use case for Kafka is to process data in processing pipelines, where rawdata is consumed from topics and then further processed or transformed into a new topic or topics, that will be consumed for another round of processing. These processing pipelines create channels of real-time data.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

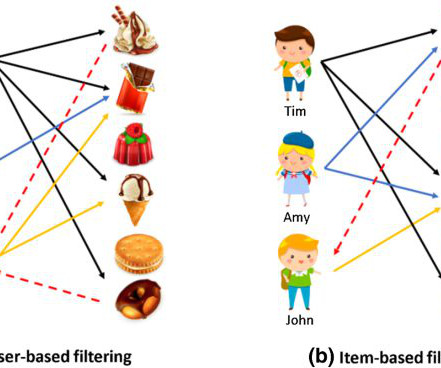
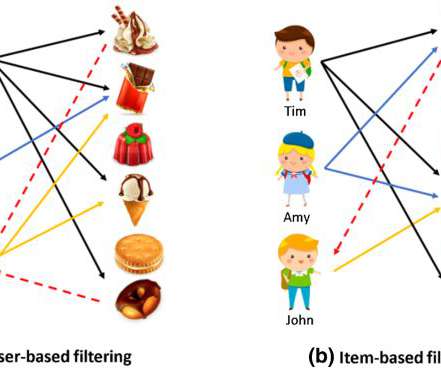






























Let's personalize your content