This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A powerful BigDatatool, Apache Hadoop alone is far from being almighty. It also provides tools for statistics, creating ML pipelines, model evaluation, and more. Spark core engine, data structures, and libraries are available via developer-friendly APIs. Hadoop limitations. It comes with multiple limitations.
This article will discuss bigdata analytics technologies, technologies used in bigdata, and new bigdata technologies. Check out the BigData courses online to develop a strong skill set while working with the most powerful BigDatatools and technologies.
Also, this release is compatible with Scala 2.13 – the latest stable language release before the 3.x That wraps up October’s Data Engineering Annotated. Follow JetBrains BigDataTools on Twitter and subscribe to our blog for more news! You can also get in touch with our team at big-data-tools@jetbrains.com.
The team has also added the ability to run Scala for the SparkSQL engine. That wraps up April’s Data Engineering Annotated. Follow JetBrains BigDataTools on Twitter and subscribe to our blog for more news! You can also get in touch with our team at big-data-tools@jetbrains.com.
Support for Scala 2.12 Follow JetBrains BigDataTools on Twitter and subscribe to our blog for more news! You can always reach me, Pasha Finkelshteyn, at asm0dey@jetbrains.com or send a DM to my personal Twitter , or you can get in touch with our team at big-data-tools@jetbrains.com.
Also, this release is compatible with Scala 2.13 – the latest stable language release before the 3.x That wraps up October’s Data Engineering Annotated. Follow JetBrains BigDataTools on Twitter and subscribe to our blog for more news! You can also get in touch with our team at big-data-tools@jetbrains.com.
The team has also added the ability to run Scala for the SparkSQL engine. That wraps up April’s Data Engineering Annotated. Follow JetBrains BigDataTools on Twitter and subscribe to our blog for more news! You can also get in touch with our team at big-data-tools@jetbrains.com.
In fact, 95% of organizations acknowledge the need to manage unstructured raw data since it is challenging and expensive to manage and analyze, which makes it a major concern for most businesses. In 2023, more than 5140 businesses worldwide have started using AWS Glue as a bigdatatool.
Here’s what’s happening in data engineering right now. Apache Spark already has two official APIs for JVM – Scala and Java – but we’re hoping the Kotlin API will be useful as well, as we’ve introduced several unique features. Follow JetBrains BigDataTools on Twitter and subscribe to our blog for more news!
Here’s what’s happening in data engineering right now. Apache Spark already has two official APIs for JVM – Scala and Java – but we’re hoping the Kotlin API will be useful as well, as we’ve introduced several unique features. Follow JetBrains BigDataTools on Twitter and subscribe to our blog for more news!
Hands-on experience with a wide range of data-related technologies The daily tasks and duties of a data architect include close coordination with data engineers and data scientists. The candidates for this certification should be able to transform, integrate and consolidate both structured and unstructured data.
Support for Scala 2.12 Follow JetBrains BigDataTools on Twitter and subscribe to our blog for more news! You can always reach me, Pasha Finkelshteyn, at asm0dey@jetbrains.com or send a DM to my personal Twitter , or you can get in touch with our team at big-data-tools@jetbrains.com.
Apache Hive and Apache Spark are the two popular BigDatatools available for complex data processing. To effectively utilize the BigDatatools, it is essential to understand the features and capabilities of the tools. The tool also does not have an automatic code optimization process.
ETL pipelines for batch data processing can also use airflow. Airflow functions effectively on pipelines that perform data transformations or receive data from numerous sources. Learn more about BigDataTools and Technologies with Innovative and Exciting BigData Projects Examples.
You ought to be able to create a data model that is performance- and scalability-optimized. Programming and Scripting Skills Building data processing pipelines requires knowledge of and experience with coding in programming languages like Python, Scala, or Java.
Programming Language.NET and Python Python and Scala AWS Glue vs. Azure Data Factory Pricing Glue prices are primarily based on data processing unit (DPU) hours. Learn more about BigDataTools and Technologies with Innovative and Exciting BigData Projects Examples.
Problem-Solving Abilities: Many certification courses provide projects and assessments which require hands-on practice of bigdatatools which enhances your problem solving capabilities. Networking Opportunities: While pursuing bigdata certification course you are likely to interact with trainers and other data professionals.
In addition to databases running on AWS, Glue can automatically find structured and semi-structured data kept in your data lake on Amazon S3, data warehouse on Amazon Redshift, and other storage locations. Furthermore, AWS Glue DataBrew allows you to visually clean and normalize data without any code.
This Spark book will teach you the spark application architecture , how to develop Spark applications in Scala and Python, and RDD, SparkSQL, and APIs. The book also contains some real-world applications, including a data pipeline for processing NASA satellite data.
Developers proficient in various programming languages, tools, and frameworks are likely to get paid more. Skills: Develop your skill set by learning new programming languages (Java, Python, Scala), as well as by mastering Apache Spark, HBase, and Hive, three bigdatatools and technologies.
They use technologies like Storm or Spark, HDFS, MapReduce, Query Tools like Pig, Hive, and Impala, and NoSQL Databases like MongoDB, Cassandra, and HBase. They also make use of ETL tools, messaging systems like Kafka, and BigDataTool kits such as SparkML and Mahout.
Languages Python, SQL, Java, Scala R, C++, Java Script, and Python Tools Kafka, Tableau, Snowflake, etc. Skills A data engineer should have good programming and analytical skills with bigdata knowledge. The ML engineers act as a bridge between software engineering and data science.
We as Azure Data Engineers should have extensive knowledge of data modelling and ETL (extract, transform, load) procedures in addition to extensive expertise in creating and managing data pipelines, data lakes, and data warehouses. Learn about well-known ETL tools such as Xplenty, Stitch, Alooma, etc.
Already familiar with the term bigdata, right? Despite the fact that we would all discuss BigData, it takes a very long time before you confront it in your career. Apache Spark is a BigDatatool that aims to handle large datasets in a parallel and distributed manner.
Proficiency in programming languages: Knowledge of programming languages such as Python and SQL is essential for Azure Data Engineers. Familiarity with cloud-based analytics and bigdatatools: Experience with cloud-based analytics and bigdatatools such as Apache Spark, Apache Hive, and Apache Storm is highly desirable.
However, if you're here to choose between Kafka vs. RabbitMQ, we would like to tell you this might not be the right question to ask because each of these bigdatatools excels with its architectural features, and one can make a decision as to which is the best based on the business use case. What is Kafka?
If your career goals are headed towards BigData, then 2016 is the best time to hone your skills in the direction, by obtaining one or more of the bigdata certifications. Acquiring bigdata analytics certifications in specific bigdata technologies can help a candidate improve their possibilities of getting hired.
Here are some role-specific skills to consider if you want to become an Azure data engineer: Programming languages are used in the majority of data storage and processing systems. Data engineers must be well-versed in programming languages such as Python, Java, and Scala.
Innovations on BigData technologies and Hadoop i.e. the Hadoop bigdatatools , let you pick the right ingredients from the data-store, organise them, and mix them. Now, thanks to a number of open source bigdata technology innovations, Hadoop implementation has become much more affordable.
Here are some role-specific skills you should consider to become an Azure data engineer- Most data storage and processing systems use programming languages. Data engineers must thoroughly understand programming languages such as Python, Java, or Scala. What is the most popular Azure Certification?
What all Hadoop certifications have in common, is a promise of industry knowledge which is a demonstrable skill potential bigdata employers are looking for, when hiring Hadoop professionals. They also need to know how to convert data values and use DDL for data analysis.
PySpark runs a completely compatible Python instance on the Spark driver (where the task was launched) while maintaining access to the Scala-based Spark cluster access. Although Spark was originally created in Scala, the Spark Community has published a new tool called PySpark, which allows Python to be used with Spark.
Many organizations across these industries have started increasing awareness about the new bigdatatools and are taking steps to develop the bigdata talent pool to drive industrialisation of the analytics segment in India. ” Experts estimate a dearth of 200,000 data analysts in India by 2018.Gartner
Other Competencies You should have proficiency in coding languages like SQL, NoSQL, Python, Java, R, and Scala. You should be thorough with technicalities related to relational and non-relational databases, Data security, ETL (extract, transform, and load) systems, Data storage, automation and scripting, bigdatatools, and machine learning.
It caters to various built-in Machine Learning APIs that allow machine learning engineers and data scientists to create predictive models. Along with all these, Apache spark caters to different APIs that are Python, Java, R, and Scala programmers can leverage in their program. BigDataTools 23.
PySpark is used to process real-time data with Kafka and Streaming, and this exhibits low latency. Multi-Language Support PySpark platform is compatible with various programming languages, including Scala, Java, Python, and R. Because of its interoperability, it is the best framework for processing large datasets.
Let us look at some of the functions of Data Engineers: They formulate data flows and pipelines Data Engineers create structures and storage databases to store the accumulated data, which requires them to be adept at core technical skills, like design, scripting, automation, programming, bigdatatools , etc.
The end of a data block points to the location of the next chunk of data blocks. DataNodes store data blocks, whereas NameNodes store these data blocks. Learn more about BigDataTools and Technologies with Innovative and Exciting BigData Projects Examples. Steps for Data preparation.
It plays a key role in streaming in the form of Spark Streaming libraries, interactive analytics in the form of SparkSQL and also provides libraries for machine learning that can be imported using Python or Scala. In this project, you will work on preparing a real-time analytics dashboard using popular BigDatatools.
Apache Spark is the most active open bigdatatool reshaping the bigdata market and has reached the tipping point in 2015.Wikibon Wikibon analysts predict that Apache Spark will account for one third (37%) of all the bigdata spending in 2022.
He currently runs a YouTube channel, E-Learning Bridge , focused on video tutorials for aspiring data professionals and regularly shares advice on data engineering, developer life, careers, motivations, and interviewing on LinkedIn. He also has adept knowledge of coding in Python, R, SQL, and using bigdatatools such as Spark.
config/server.properties Why is Kafka technology significant in the BigData industry? It is written in Scala and Java. Kafka aims to provide a platform for real-time handling data feeds and can handle trillions of events on a daily basis. It also involves gaining expert-level practical knowledge of these tools.
Top 100+ Data Engineer Interview Questions and Answers The following sections consist of the top 100+ data engineer interview questions divided based on bigdata fundamentals, bigdatatools/technologies, and bigdata cloud computing platforms. What is a case class in Scala?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









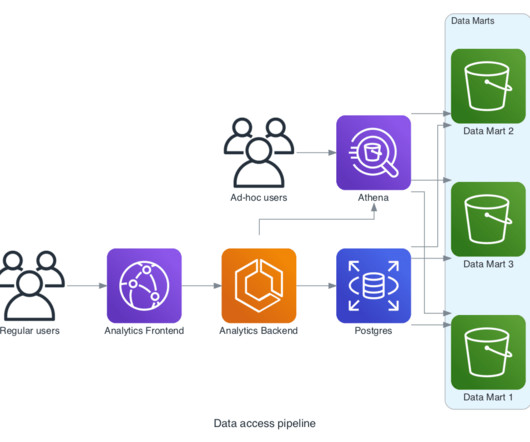
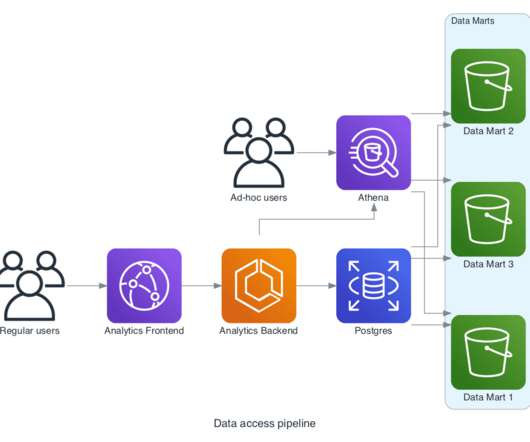






































Let's personalize your content