This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This continues a series of posts on the topic of efficient ingestion of data from the cloud (e.g., Before we get started, let’s be clear…when using cloudstorage, it is usually not recommended to work with files that are particularly large. here , here , and here ). CPU cores and TCP connections).
And that’s the target of today’s post — We’ll be developing a data pipeline using Apache Spark, Google CloudStorage, and Google Big Query (using the free tier) not sponsored. The tools Spark is an all-purpose distributed memory-based data processing framework geared towards processing extremely large amounts of data.
For instance, partition pruning, data skipping, and columnar storage formats (like Parquet and ORC) allow efficient data retrieval, reducing scan times and query costs. This is invaluable in bigdata environments, where unnecessary scans can significantly drain resources.
Educating Data Analysts at Scale. Cloudera is pleased to announce, in partnership with Coursera, the launch of Modern BigData Analysis with SQL , a three-course specialization now available on the Coursera platform. This sequence of courses teaches the essential skills for working with data of any size using SQL.
Accessing and storing huge data volumes for analytics was going on for a long time. But ‘bigdata’ as a concept gained popularity in the early 2000s when Doug Laney, an industry analyst, articulated the definition of bigdata as the 3Vs. What is BigData? Some examples of BigData: 1.
With this expanded scope, the organization has introduced its CloudStorage Connector, which has become a fully integrated component for data access and processing of Hadoop and Spark workloads. This has increased operational efficiencies significantly because now teams are able to leverage data much more quickly than before.
Cloud elasticity, combined with the right user applications, can reduce the friction of waiting for IT to fulfill requests and provision resources and data. As such, we’re seeing cloud-based bigdata growing exponentially for Cloudera customers and across the market as a whole.
In the age of AI, enterprises are increasingly looking to extract value from their data at scale but often find it difficult to establish a scalable data engineering foundation that can process the large amounts of data required to build or improve models.
You listen to this show to learn and stay up to date with what’s happening in databases, streaming platforms, bigdata, and everything else you need to know about modern data management.For even more opportunities to meet, listen, and learn from your peers you don’t want to miss out on this year’s conference season.
*For clarity, the scope of the current certification covers CDP-Private Cloud Base. Certification of CDP-Private Cloud Experiences will be considered in the future. The certification process is designed to validate Cloudera products on a variety of Cloud, Storage & Compute Platforms.
Welcome to the world of data engineering, where the power of bigdata unfolds. If you're aspiring to be a data engineer and seeking to showcase your skills or gain hands-on experience, you've landed in the right spot. If data scientists and analysts are pilots, data engineers are aircraft manufacturers.
A database is a structured data collection that is stored and accessed electronically. File systems can store small datasets, while computer clusters or cloudstorage keeps larger datasets. According to a database model, the organization of data is known as database design.
It serves as a foundation for the entire data management strategy and consists of multiple components including data pipelines; , on-premises and cloudstorage facilities – data lakes , data warehouses , data hubs ;, data streaming and BigData analytics solutions ( Hadoop , Spark , Kafka , etc.);
The Cloudera platform delivers a one-stop shop that allows you to store any kind of data, process and analyze it in many different ways in a single environment, and integrate with the rest of your data infrastructure. But working with cloudstorage has often been a compromise. As a Hadoop developer, I loved that!
Apache Kafka is an open-source, distributed streaming platform for messaging, storing, processing, and integrating large data volumes in real time. It offers high throughput, low latency, and scalability that meets the requirements of BigData. Cloudera , focusing on BigData analytics.
Indeed, why would we build a data connector from scratch if it already exists and is being managed in the cloud? Very often it is row-based and might become quite expensive on an enterprise level of data ingestion, i.e. bigdata pipelines. The downside of this approach is it’s pricing model though. Image by author.
You will retain use of the following Google Cloud application deployment environments: App Engine, Kubernetes Engine, and Compute Engine. Select and use one of Google Cloud's storage solutions, which include CloudStorage, Cloud SQL, Cloud Bigtable, and Firestore.
Object Storage, also known as distributed object storage, is hosted services used to store and access a large number of blobs or binary data. Google Compute Engine uses Google CloudStorage to provide this service, while AWS uses the S3 service for this. Bigdata and machine learning are the main areas of GCP.
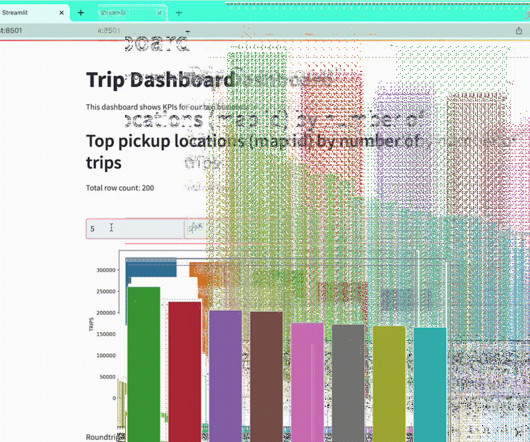
In that case, queries are still processed using the BigQuery compute infrastructure but read data from GCS instead. Such external tables come with some disadvantages but in some cases it can be more cost efficient to have the data stored in GCS. Load data For data ingestion Google CloudStorage is a pragmatic way to solve the task.
Moreover, the data will need to leave the cloud env to go on our machine, which is not exactly secure and auditable. At the end of the cycle, we will have an analytics app that can be used to both visualize and query the data in real time with virtually no infra costs.
As the data world evolves, more formats may emerge, and existing formats may be adapted to accommodate new unstructured data types. Unstructured data and bigdata Unstructured and bigdata are related concepts, but they aren’t the same. MongoDB, Cassandra), and bigdata processing frameworks (e.g.,
Build a Job Winning Data Engineer Portfolio with Solved End-to-End BigData Projects. Features of Pub/Sub Let us look at some of the useful features Google Cloud Pub/Sub offers. Global Availability Users can access Google Cloud Pub/Sub from anywhere in the world. PREVIOUS NEXT <
Look for AWS Cloud Practitioner Essentials Training online to learn the fundamentals of AWS Cloud Computing and become an expert in handling the AWS Cloud platform. Civis Analytics Civis Analytics is a bigdataCloud tool used to centralize data, manage services, and scale up organizations.
And yet it is still compatible with different clouds, storage formats (including Kudu , Ozone , and many others), and storage engines. It shouldn’t come as a surprise that Cloudera managed to achieve this, as they know how to create on-premise data engineering products. Of course, the main topic is data streaming.
And yet it is still compatible with different clouds, storage formats (including Kudu , Ozone , and many others), and storage engines. It shouldn’t come as a surprise that Cloudera managed to achieve this, as they know how to create on-premise data engineering products. Of course, the main topic is data streaming.
Snowflake architecture provides flexibility with bigdata. It allows decoupling of the storage and compute functions, which allows the organizations to conveniently scale up or down as needed and pay only for the resources that are used. The data objects are accessible only through SQL query operations run using Snowflake.
Artificial Intelligence Course With the availability of bigdata and the rapid development of Machine Learning, Artificial Intelligence is the game’s name, as witnessed by the massive rise in the number of businesses depending on AI. And what better solution than cloudstorage?
The intent of this article is to articulate and quantify the value proposition of CDP Public Cloud versus legacy IaaS deployments and illustrate why Cloudera technology is the ideal cloud platform to migrate bigdata workloads off of IaaS deployments. Multi-Cloud Management. Single-cloud visibility with Ambari.
The Singapore-based company boasts a robust cloud infrastructure and provides a wide range of cloud services to users. Some prominent cloud services offered by Alibaba Cloud include database storage, large-scale computing, network visualization, elastic computing, bigdata analytics, and management services.
Amazon brought innovation in technology and enjoyed a massive head start compared to Google Cloud, Microsoft Azure , and other cloud computing services. It developed and optimized everything from cloudstorage, computing, IaaS, and PaaS. AWS S3 and GCP Storage Amazon and Google both have their solution for cloudstorage.
Why Use Azure for Data Science? Data Science is heavily reliant on computing resources. Building Machine Learning (ML) or Artificial Intelligence ( AI ) models, requires work on bigdata. The computing needs to manage the bigdata is costly if we decide to set up an on-premises server and computing capabilities.
BigQuery enables users to store data in tables, allowing them to quickly and easily access their data. It supports structured and unstructured data, allowing users to work with various formats. BigQuery also supports many data sources, including Google CloudStorage, Google Drive, and Sheets.
Data Sourcing: Building pipelines to source data from different company data warehouses is fundamental to the responsibilities of a data engineer. So, work on projects that guide you on how to build end-to-end ETL/ELT data pipelines. This bigdata project discusses IoT architecture with a sample use case.
Think back to the early 2000s, a time of bigdata warehouses with rigid structures. Organizations searched for ways to add more data, more variety of data, bigger sets of data, and faster computing speed. There was a massive expansion of efforts to design and deploy bigdata technologies.
Demand for ETL Developer Jobs With the increasing importance of ETL in data management for data-driven decision-making, the need for ETL developers is likely to grow in the coming years. Gartner lists ETL among the top 10 in-demand skills for bigdata professionals. PREVIOUS NEXT <
To dive deeper into details, read our article Data Lakehouse: Concept, Key Features, and Architecture Layers. The lakehouse platform was founded by the creators of Apache Spark , a processing engine for bigdata workloads. The platform can become a pillar of a modern data stack , especially for large-scale companies.
The AWS services cheat sheet will provide you with the basics of Amazon Web Service, like the type of cloud, services, tools, commands, etc. Opt for Cloud Computing Courses online to develop your knowledge of cloudstorage, databases, networking, security, and analytics and launch a career in Cloud Computing.
Say you wanted to build one integration pipeline from MQTT to Kafka with KSQL for data preprocessing, and use Kafka Connect for data ingestion into HDFS, AWS S3 or Google CloudStorage, where you do the model training. New MQTT input data can directly be used in real time to make predictions.
BigData Analysis: UBER Uber is a smartphone app that summons transportation and connects users to go to places if they are looking for a ride. It helps in storing user data and connects them with other users who are providing them with services. The entire business model is based on the bigdata principle for crowdsourcing.
Data lakes, however, are sometimes used as cheap storage with the expectation that they are used for analytics. For building data lakes, the following technologies provide flexible and scalable data lake storage : . Gen 2 Azure Data Lake Storage . Cloudstorage provided by Google .
Choosing the Right AWS Certificate Most enterprises have switched over to cloud-based platforms, tweaking their marketing strategies to suit the needs of their customers. Cloudstorage, sharing, and services have been in vogue for a few years now, gaining more popularity and business with each passing year.
In the realm of bigdata and AI, managing and securing data assets efficiently is crucial. Databricks addresses this challenge with Unity Catalog, a comprehensive governance solution designed to streamline and secure data management across Databricks workspaces. GCS buckets on Google Cloud.
It’s frustrating…[Lake Formation] is a step-level change for how easy it is to set up data lakes,” he said. Google Cloud Platform and/or BigLake Google offers a couple options for building data lakes. Teradata VantageCloud Teradata offers a comprehensive data lake solution through its VantageCloud platform.
Cloud computing interview questions and answers. The collection of networking, gear, applications and data that provides or sells computing through the internet is known as the cloud. Computational and data capabilities that suppliers might sell over the web. 2) What advantages does cloud computing offer?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content