This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Bigdata is revolutionizing the healthcare industry and changing how we think about patient care. In this case, bigdata refers to the vast amounts of data generated by healthcare systems and patients, including electronic health records, claims data, and patient-generated data.
Introduction BigData is a large and complex dataset generated by various sources and grows exponentially. It is so extensive and diverse that traditional data processing methods cannot handle it. The volume, velocity, and variety of BigData can make it difficult to process and analyze.
In the data-driven world […] The post Monitoring Data Quality for Your BigData Pipelines Made Easy appeared first on Analytics Vidhya. Determine success by the precision of your charts, the equipment’s dependability, and your crew’s expertise. A single mistake, glitch, or slip-up could endanger the trip.
Introduction In this technical era, BigData is proven as revolutionary as it is growing unexpectedly. According to the survey reports, around 90% of the present data was generated only in the past two years. Bigdata is nothing but the vast volume of datasets measured in terabytes or petabytes or even more.
With all the recent data events I have put together I inevitably run into new dataengineers who are either finishing up college or looking to transition into a dataengineer or data scientist position. In fact I have talked to several newly graduated engineers who are struggling to find work.
Introduction HDFS (Hadoop Distributed File System) is not a traditional database but a distributed file system designed to store and process bigdata. It provides high-throughput access to data and is optimized for […] The post A Dive into the Basics of BigData Storage with HDFS appeared first on Analytics Vidhya.
After a 2-years break, I had a chance to speak again, this time at the BigData Warsaw 2023. Even though I couldn't be at Warsaw that day, I enjoyed the experience and also watched other sessions available through the conference platform.
An estimated 8,650% growth of the volume of Data to 175 zetabytes from 2010 to 2025 has created an enormous need for DataEngineers to build an organization's bigdata platform to be fast, efficient and scalable.
Dataengineering can help with it. It is the force behind seamless data flow, enabling everything from AI-driven automation to real-time analytics. Key Trends in DataEngineering for 2025 In the fast-paced world of technology, dataengineering services keep companies that focus on data running.
Are dataengineers all learning Rust? Our team is putting together an all day event focused on helping answer some… Read more The post What Is The State Of DataEngineering And Infrastructure In 2023 appeared first on Seattle Data Guy. Are Snowflake and Databricks still fighting over total cost of ownership?
One job that has become increasingly popular across enterprise data teams is the role of the AI dataengineer. Demand for AI dataengineers has grown rapidly in data-driven organizations. But what does an AI dataengineer do? Table of Contents What Does an AI DataEngineer Do?
Get the report → Editor’s Note: Data Council 2025, Apr 22-24, Oakland, CA Data Council has always been one of my favorite events to connect with and learn from the dataengineering community. Data Council 2025 is set for April 22-24 in Oakland, CA. DeepSeek’s smallpond Takes on BigData.
Should companies go full blowing bigdata/data science platform right away? Are you in the Proof-of-Concept phase, where you are just working with offline data, where you are proving your concepts? To answer the question at the beginning: No, I wouldn't go for a bigdata solution. What do you think about it?
BigData has become the dominant innovation in all high-performing companies. Notable businesses today focus their decision-making capabilities on knowledge gained from the study of bigdata. BigData gives you an advantage in competition as true for businesses as it is for professionals working in the area of analytics.
In that time there have been a number of generational shifts in how dataengineering is done. Go to [dataengineeringpodcast.com/materialize]([link] Support DataEngineering Podcast Summary This podcast started almost exactly six years ago, and the technology landscape was much different than it is now.
Foresighted enterprises are the ones who will be able to leverage this data for maximum profitability through data processing and handling techniques. With the rise in opportunities related to BigData, challenges are also bound to increase. Below are the 5 major BigData challenges that enterprises face in 2024: 1.
Apache Airflow is a very popular tool that dataengineers rely on. Why do dataengineers like Airflow? What are… Read more The post What Is Apache Airflow – DataEngineering Consulting appeared first on Seattle Data Guy. Also, what does Apache Airflow event do? What is a DAG?
Learn dataengineering, all the references ( credits ) This is a special edition of the Data News. But right now I'm in holidays finishing a hiking week in Corsica 🥾 So I wrote this special edition about: how to learn dataengineering in 2024. Who are the dataengineers?
The funny thing is, at the time, and today, it […] The post Why did Golang lose to Rust for DataEngineering? appeared first on Confessions of a Data Guy. When I first wrote a little Golang (~2+ years ago) I was just trying to see what the hype was all about.
Starting new dataengineering projects can be challenging. Dataengineers can get stuck on finding the right data for their dataengineering project or picking the right tools.
[link] Alireza Sadeghi: The rise of single-node processing engines The article highlights the growing popularity of single-node processing frameworks like DuckDB, Apache DataFusion, and Polars in 2024, challenging the distributed-first mindset of the "bigdata" era.
A collaborative and interactive workspace allows users to perform bigdata processing and machine learning tasks easily. Introduction Azure Databricks is a fast, easy, and collaborative Apache Spark-based analytics platform that is built on top of the Microsoft Azure cloud.
From online transactions and social media interactions to sensor readings and scientific research, the sheer volume, velocity, and variety of data have given rise to the concept of “Bigdata.”
Bigdata in information technology is used to improve operations, provide better customer service, develop customized marketing campaigns, and take other actions to increase revenue and profits. It is especially true in the world of bigdata. It is especially true in the world of bigdata.
There are probably few things in life that will strike more fear and tumult in the heart of the DataEngineer than historical loads. How could it possibly be, just take a bunch of data stored somewhere and shove it into a table. […] The post Introduction to Historical Loads – for DataEngineers.
One thing I find myself doing these days (I am unsure how I feel about this), is teaching others to solve problems … DataEngineering problems to be specific. I […] The post How to Solve DataEngineering Problems appeared first on Confessions of a Data Guy.
Parquet vs ORC vs Avro vs Delta Lake Photo by Viktor Talashuk on Unsplash The bigdata world is full of various storage systems, heavily influenced by different file formats. These are key in nearly all data pipelines, allowing for efficient data storage and easier querying and information extraction. schema(schema).load("s3a://mybucket/ten_million_parquet.csv")
Soam Acharya | DataEngineering Oversight; Keith Regier | Data Privacy Engineering Manager Background Businesses collect many different types of data. The result is a multi-tenant DataEngineering platform, allowing users and services access to only the data they require for their work.
Platform Specific Tools and Advanced Techniques Photo by Christopher Burns on Unsplash The modern data ecosystem keeps evolving and new data tools emerge now and then. In this article, I want to talk about crucial things that affect dataengineers. What is it? The downside of this approach is it’s pricing model though.
It’s unavoidable that as businesses demand that their data teams implement AI, they will also realize that dataengineers are a crucial piece of the data pipeline.
Welcome to the world of dataengineering, where the power of bigdata unfolds. If you're aspiring to be a dataengineer and seeking to showcase your skills or gain hands-on experience, you've landed in the right spot. What are DataEngineering Projects?
Data scientists and engineers are two of the most important data professions and it is important to understand the difference between dataengineering vs data science.
DataEngineering is typically a software engineering role that focuses deeply on data – namely, data workflows, data pipelines, and the ETL (Extract, Transform, Load) process. What is Data Science? What are the roles and responsibilities of a DataEngineer? And many more. And many more.
Did you know there are only 3 types of DataEngineers? The post The 3 Types of DataEngineers. appeared first on Confessions of a Data Guy. It’s true. I hope you are the right one.
Announcements Hello and welcome to the DataEngineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
Summary In this post we have covered the topic of pulling bigdata files from cloud storage. We have seen that the best approach will likely vary based on the particular needs of the data application in question. Be sure to run your own in-depth, use-case driven experiments before making any design decisions.
This post is for those poor souls that need to scan terabytes of data in BigQuery to calculate some counts, sums, or rolling totals over huge event data on a daily or even at a higher frequency basis. In this post, I will go over a technique for enabling a cheap data injestion and cheap data consumption for “bigdata”.
Introduction BigQuery is a robust data warehousing and analytics solution that allows businesses to store and query large amounts of data in real time. Its importance lies in its ability to handle bigdata and provide insights that can inform business decisions.
In the age of AI, enterprises are increasingly looking to extract value from their data at scale but often find it difficult to establish a scalable dataengineering foundation that can process the large amounts of data required to build or improve models.
Introduction Bigdata processing is crucial today. Bigdata analytics and learning help corporations foresee client demands, provide useful recommendations, and more. Hadoop, the Open-Source Software Framework for scalable and scattered computation of massive data sets, makes it easy.
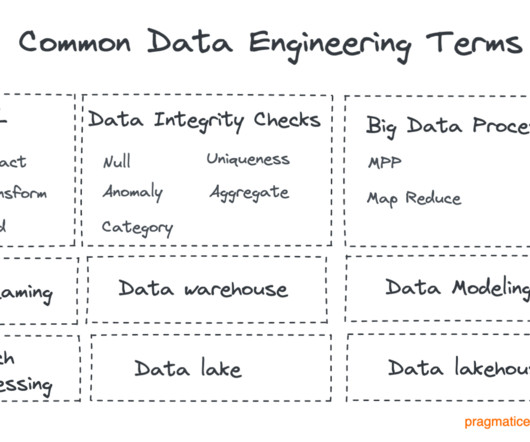
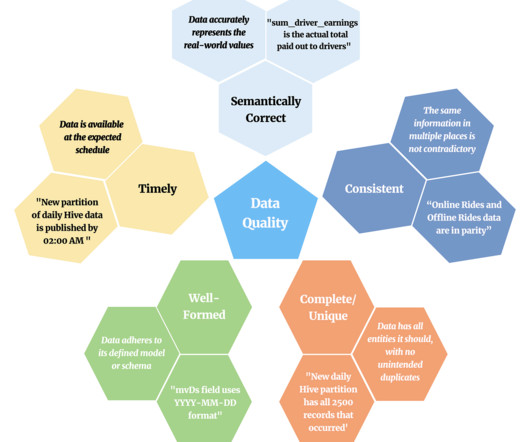
This delay increased the difficulty and cost of data backfills. The lack of centralization in data quality also made the data discovery process inefficient, making it hard for data scientists and dataengineers to identify trustworthy data.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content