This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
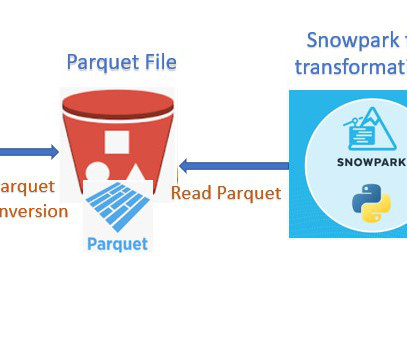
Parquet, columnar storage file format saves both time and space when it comes to bigdata processing. Snowflake Output Happy 0 0 % Sad 0 0 % Excited 0 0 % Sleepy 0 0 % Angry 0 0 % Surprise 0 0 % The post DataIngestion with Glue and Snowpark appeared first on Cloudyard. Technical Implementation: GLUE Job.
Prefetching data from the cloud is employed by many frameworks for accelerating the speed of dataingestion. For example, both PyTorch and TensorFlow support prefetching training-data files for optimizing deep learning training. during runtime to support varying dataingestion patterns.
A dataingestion architecture is the technical blueprint that ensures that every pulse of your organization’s data ecosystem brings critical information to where it’s needed most. A typical dataingestion flow. Popular DataIngestion Tools Choosing the right ingestion technology is key to a successful architecture.
BigData enjoys the hype around it and for a reason. But the understanding of the essence of BigData and ways to analyze it is still blurred. This post will draw a full picture of what BigData analytics is and how it works. BigData and its main characteristics. Key BigData characteristics.
Two popular approaches that have emerged in recent years are data warehouse and bigdata. While both deal with large datasets, but when it comes to data warehouse vs bigdata, they have different focuses and offer distinct advantages. Bigdata offers several advantages.
An end-to-end Data Science pipeline starts from business discussion to delivering the product to the customers. One of the key components of this pipeline is Dataingestion. It helps in integrating data from multiple sources such as IoT, SaaS, on-premises, etc., What is DataIngestion?
Dataingestion is the process of collecting data from various sources and moving it to your data warehouse or lake for processing and analysis. It is the first step in modern data management workflows. Table of Contents What is DataIngestion? Decision making would be slower and less accurate.
DE Zoomcamp 2.2.1 – Introduction to Workflow Orchestration Following last weeks blog , we move to dataingestion. We already had a script that downloaded a csv file, processed the data and pushed the data to postgres database. This week, we got to think about our dataingestion design.
This is where real-time dataingestion comes into the picture. Data is collected from various sources such as social media feeds, website interactions, log files and processing. This refers to Real-time dataingestion. To achieve this goal, pursuing Data Engineer certification can be highly beneficial.
Thus, it is no wonder that the origin of bigdata is a topic many bigdata professionals like to explore. The historical development of bigdata, in one form or another, started making news in the 1990s. These systems hamper data handling to a great extent because errors usually persist.
Bigdata has revolutionized the world of data science altogether. With the help of bigdata analytics, we can gain insights from large datasets and reveal previously concealed patterns, trends, and correlations. What is BigData? What are the 4 V’s of BigData?
In today's data-driven world, the volume and variety of information are growing unprecedentedly. As organizations strive to gain valuable insights and make informed decisions, two contrasting approaches to data analysis have emerged, BigData vs Small Data. Small Data is collected and processed at a slower pace.
The bigdata industry is growing rapidly. Based on the exploding interest in the competitive edge provided by BigData analytics, the market for bigdata is expanding dramatically. BigData startups compete for market share with the blue-chip giants that dominate the business intelligence software market.
If you're looking to break into the exciting field of bigdata or advance your bigdata career, being well-prepared for bigdata interview questions is essential. Get ready to expand your knowledge and take your bigdata career to the next level! Everything is about data these days.
In an earlier VISION post, The Five Markers on Your BigData Journey , Amy O’Connor shared some common traits of many of the most successful data-driven companies. In this blog, I’d like to explore what I believe is the most important of those traits, building and fostering a culture of data. .
I mentioned in an earlier blog titled, “Staffing your bigdata team, ” that data engineers are critical to a successful data journey. And the longer it takes to put a team in place, the likelier it is that your bigdata project will stall.
In conjunction with the evolving data ecosystem are demands by business for reliable, trustworthy, up-to-date data to enable real-time actionable insights. BigData Fabric has emerged in response to modern data ecosystem challenges facing today’s enterprises. What is BigData Fabric? Data access.
Then, the company used Cloudera’s Data Platform as a foundation to build its own Network Real-time Analytics Platform (NRAP) and created the proper infrastructure to collect and analyze large-scale bigdata in real-time. . For this, the RTA transformed its dataingestion and management processes. .
The surge in BigData and Cloud Computing has created a huge demand for real-time Data Analytics. Companies rely on complex ETL (Extract Transform and Load) Pipelines that collect data from sources in the raw form and deliver it to a storage destination in a form suitable for analysis.
Did you know that, according to Linkedin, over 24,000 BigData jobs in the US list Apache Spark as a required skill? Learning Spark has become more of a necessity to enter the BigData industry. Python is one of the most extensively used programming languages for Data Analysis, Machine Learning , and data science tasks.
Data Collection/Ingestion The next component in the data pipeline is the ingestion layer, which is responsible for collecting and bringing data into the pipeline. This is a more efficient data pipeline methodology because it only gets triggered when there is a change to the source.”
The adaptability and technical superiority of such open-source bigdata projects make them stand out for community use. As per the surveyors, Bigdata (35 percent), Cloud computing (39 percent), operating systems (33 percent), and the Internet of Things (31 percent) are all expected to be impacted by open source shortly.
What Are The Main Components Of BigData? The ecosystems of bigdata are akin to ogres. Layers of bigdata components compiled together to form a stack, and it isn’t as straightforward as collecting data and converting it into knowledge. . The main components of bigdata types: .
For instance, partition pruning, data skipping, and columnar storage formats (like Parquet and ORC) allow efficient data retrieval, reducing scan times and query costs. This is invaluable in bigdata environments, where unnecessary scans can significantly drain resources.
Strategically enhancing address mapping during data integration using geocoding and string matching Many individuals in the bigdata industry may encounter the following scenario: Is the acronym “TIL” equivalent to the phrase “Today I learned” when extracting these two entries from distinct systems?
This means that there is out of the box support for Ozone storage in services like Apache Hive , Apache Impala, Apache Spark, and Apache Nifi, as well as in Private Cloud experiences like Cloudera Machine Learning (CML) and Data Warehousing Experience (DWX). Dataingestion through ‘s3’. Ozone Namespace Overview.
DataIngestion. The raw data is in a series of CSV files. We will firstly convert this to parquet format as most data lakes exist as object stores full of parquet files. On June 3, join the NVIDIA and Cloudera teams for our upcoming webinar Enable Faster BigData Science with NVIDIA GPUs. Register Now. .
As a result, a single consolidated and centralized source of truth does not exist that can be leveraged to derive data lineage truth. Therefore, the ingestion approach for data lineage is designed to work with many disparate data sources. push or pull. Today, we are operating using a pull-heavy model.
This CVD is built using Cloudera Data Platform Private Cloud Base 7.1.5 Apache Ozone is one of the major innovations introduced in CDP, which provides the next generation storage architecture for BigData applications, where data blocks are organized in storage containers for larger scale and to handle small objects.
The data journey is not linear, but it is an infinite loop data lifecycle – initiating at the edge, weaving through a data platform, and resulting in business imperative insights applied to real business-critical problems that result in new data-led initiatives. Conclusion.
The organization was locked into a legacy data warehouse with high operational costs and inability to perform exploratory analytics. With more than 25TB of dataingested from over 200 different sources, Telkomsel recognized that to best serve its customers it had to get to grips with its data. .
For a more in-depth exploration, plus advice from Snowflake’s Travis Henry, Director of Sales Development Ops and Enablement, and Ryan Huang, Senior Marketing Data Analyst, register for our Snowflake on Snowflake webinar on boosting market efficiency by leveraging data from Outreach.
Cloudera DataFlow (CDF) is a scalable, real-time streaming data platform that collects, curates, and analyzes data so customers gain key insights for immediate actionable intelligence. CDF, as an end-to-end streaming data platform, emerges as a clear solution for managing data from the edge all the way to the enterprise.
Welcome to the world of data engineering, where the power of bigdata unfolds. If you're aspiring to be a data engineer and seeking to showcase your skills or gain hands-on experience, you've landed in the right spot. If data scientists and analysts are pilots, data engineers are aircraft manufacturers.
Cloudera Data Platform (CDP) is a solution that integrates open-source tools with security and cloud compatibility. Once ready, the model can be operationalized through Cloudera Machine Learning and its RESTful endpoints can be pushed into the streaming dataingestion pipeline, enabling real-time fraudulent activity detection.
Our comprehensive data-level security, auditing and de-identification features eliminate the need for time-consuming manual processes and our focus on data and compliance team collaboration empowers you to deliver quick and valuable data analytics on the most sensitive data to unlock the full potential of your cloud data platforms.
It allows real-time dataingestion, processing, model deployment and monitoring in a reliable and scalable way. This blog post focuses on how the Kafka ecosystem can help solve the impedance mismatch between data scientists, data engineers and production engineers. Kai Waehner works as technology evangelist at Confluent.
📬 Subscribe to the excellent weekly newsletter 📬 A bit of context It's important to take a step back and to understand from where the data engineering is coming from. Data engineering inherits from years of data practices in US big companies. workflows (Airflow, Prefect, Dagster, etc.)
And next to those legacy ERP, HCM, SCM and CRM systems, that mysterious elephant in the room – that “BigData” platform running in the data center that is driving much of the company’s analytics and BI – looks like a great potential candidate. . Streaming data analytics. . Data science & engineering.
In this episode Purvi Shah, the VP of Enterprise BigData Platforms at American Express, explains how they have invested in the cloud to power this visibility and the complex suite of integrations they have built and maintained across legacy and modern systems to make it possible. In fact, while only 3.5% In fact, while only 3.5%
Given the era of bigdata, organizations are producing and analyzing enormous amounts of data daily. They use tools that enable streamlining dataingestion, transformation, and analysis to try to understand it all.
Python tricks and techniques for dataingestion, validation, processing, and testing: a practical walkthrough Continue reading on Towards Data Science »
Did you know the global bigdata market will likely reach $268.4 Businesses are leveraging bigdata now more than ever. Bigdata helps businesses increase operational efficiency, creating a better balance between performance, flexibility, and pricing. billion by 2026? So, how do we overcome this challenge?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content