This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Before the rise of this technology, StackOverflow was the superior option to Googling in the hope of finding a blog post which answered a question. And if you couldn’t find an answer to a problem, you could post a question on StackOverflow and someone would probably answer it.
for the simulation engine Go on the backend PostgreSQL for the data layer React and TypeScript on the frontend Prometheus and Grafana for monitoring and observability And if you were wondering how all of this was built, Juraj documented his process in an incredible, 34-part blog series. You can read this here. Serving a web page.
A few months ago I wrote a blog post about event skew and how dangerous it is for a stateful streaming job. Since it was a high-level explanation, I didn't cover Apache Spark Structured Streaming deeply at that moment.
In this blog post, we will take a closer look at Azure Databricks, its key features, […] The post Azure Databricks: A Comprehensive Guide appeared first on Analytics Vidhya. Introduction Azure Databricks is a fast, easy, and collaborative Apache Spark-based analytics platform that is built on top of the Microsoft Azure cloud.
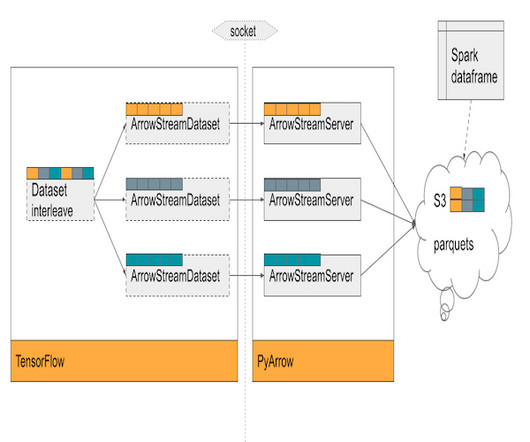
This blog post delves into our journey of optimizing training time using TensorFlow and Horovod, along with the development of ArrowStreamServer, our in-house library for low-latency data streaming and serving. These models handle large tabular datasets with small parameter spaces, requiring innovative data solutions.
In this blog post, we […] The post Explore the World of Data-Tech with DataHour appeared first on Analytics Vidhya. Current professionals seeking to transition into the data-tech domain or data science professionals seeking to enhance their career growth and development can also benefit from these sessions.
In this blog, we will delve into an early stage in PAI implementation: data lineage. This took Meta multiple years to complete across our millions of disparate data assets, and well cover each of these more deeply in future blog posts: Inventorying involves collecting various code and data assets (e.g.,
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. For more information regarding this, refer to our previous blog.
The blog post reviews an Apache Incubating project called Apache XTable, which aims to provide cross-format interoperability among Delta Lake, Apache Hudi, and Apache Iceberg. Below is a concise breakdown from some time I spend playing around this this new tool and some technical observations: 1. What is Apache XTable?
In this blog, we will […] The post How to Implement a Data Pipeline Using Amazon Web Services? To make these processes efficient, data pipelines are necessary. Data engineers specialize in building and maintaining these data pipelines that underpin the analytics ecosystem. appeared first on Analytics Vidhya.
The blog highlights how moving from 6-character base-64 to 20-digit base-2 file distribution brings more distribution in S3 and reduces request failures. The blog is a good summary of how to use Snowflake QUERY_TAG to measure and monitor query performance. The blog post made me curious to understand DataFusion's internals.
The blog is an excellent summary of the existing unstructured data landscape. It is exciting to read probably the first blog on building a vector search infrastructure at scale. The blog from Meta discusses how it designed a privacy-preserving storage. link] Alibaba: Evolution of Flink 2.0
This blog post is the second in a three-part series on migrations. That’s why we’ve collected these migration success stories to help you get started on your migration to Snowflake. Today we’re focusing on customers who migrated from a cloud data warehouse to Snowflake and some of the benefits they saw.
This blog provides detailed information on data Platform as a Service (PaaS),, how it differs from other cloud computing models, its working principles, and its benefits. PaaS is a fundamental cloud computing model that offers developers and organizations a robust environment for building, deploying, and managing applications efficiently.
An explanation on why such a short blog post: I wanted to reply in a tweet, but, apparently, Twitter does not allow posting more than a few links in a reply. OpsGenie is clearly more critical of a system than the ones like JIRA or Confluence, but it is not treated with priority within the Atlassian stack, at least now it seems like it.
And specifically, I was reading one of your blog posts recently that talked about the dark ages of data. The post The Struggle Between Data Dark Ages and LLM Accuracy appeared first on Cloudera Blog. Here are some key takeaways from Ray in that conversation. 85% accuracy for customer experience means that number isnt bad.
The blog took out the last edition’s recommendation on AI and summarized the current state of AI adoption in enterprises. The simplistic model expressed in the blog made it easy for me to reason about the transactional system design. Kafka is probably the most reliable data infrastructure in the modern data era.
Over the past four weeks, I took a break from blogging and LinkedIn to focus on building nao. We published videos about the Forward Data Conference, you can watch Hannes, DuckDB co-creator, keynote about Changing Large Tables.
In this blog, we are excited to share Databricks's journey in migrating to Unity Catalog for enhanced data governance. We'll discuss our high-level strategy and the tools we developed to facilitate the migration. Our goal is to highlight the benefits of Unity Catalog and make you feel confident about transitioning to it.
I found the blog to be a fresh take on the skill in demand by layoff datasets. The blog provides an excellent analysis of smallpond compared to Spark and Daft. Understanding which skills are in growing demand and the need for upskilling as the software abstraction changes is critical. link] Mehdio: DuckDB goes distributed?
(Written by Kirill Voloshin & Abdullah Abusamrah ) In our previous blog posts , we have covered our server-driven UI framework called Picnic Page Platform. This blog post explores how weve further evolved our framework to support more complex flows that interact with our back-end systems, persist data andmore.
Even though I was blogging less in the second half of the previous year, the retrospective is still the blog post I'm waiting for each year. Every year I summarize what happened in the past 12 months and share with you my future plans. It's time for the 2024 Edition!
Delivers Enhanced Efficiency and Adaptability appeared first on Cloudera Blog. Learn More: To explore the new capabilities of Cloudera DataFlow 2.9 and discover how it can transform your data pipelines, watch this video. link] [link] The post Fueling the Future of GenAI with NiFi: Cloudera DataFlow 2.9
In this blog, we will go through the technical design and share some offline and online results for our LLM-based search relevance pipeline. Pin Text Representations Pins on Pinterest are rich multimedia entities that feature images, videos, and other contents, often linked to external webpages or blogs.
Learn Python through tutorials, blogs, books, project work, and exercises. Access all of it on GitHub for free and join a supportive open-source community.
You can learn more in our SwiftKV research blog post. Because SwiftKV is fully open source, you can also deploy it on your own with model checkpoints on Hugging Face and optimized inference on vLLM.
This blog explores the fundamentals of the private cloud framework. A private or enterprise cloud is the type of cloud computing in which all the resources are dedicated to a single tenant. Private cloud allows organizations a high level of cloud computing benefits such as scalability, flexibility, access control, and faster service delivery.
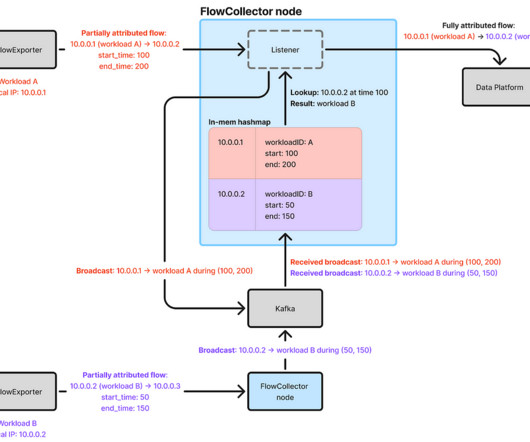
By Cheng Xie , Bryan Shultz , and Christine Xu In a previous blog post , we described how Netflix uses eBPF to capture TCP flow logs at scale for enhanced network insights. In this post, we delve deeper into how Netflix solved a core problem: accurately attributing flow IP addresses to workload identities.
I found the product blog from QuantumBlack gives a view of data quality in unstructured data. The blog post highlights the industry trend of search engines transitioning towards embedding-based systems, moving beyond traditional IDF models.
Read the popular blog article. Get the DataOps Advantage: Learn how to apply DataOps to monitor, iterate, and automate quality checkskeeping data quality high without slowing down. Practical Tools to Sprint Ahead: Dive into hands-on tips with open-source tools that supercharge data validation and observability. Want More Detail?
The post Introducing Accelerator for Machine Learning (ML) Projects: Summarization with Gemini from Vertex AI appeared first on Cloudera Blog. Stay tuned for future AMPs well build using Cloudera AI and Vertex AI.
This blog explores the current landscape of […] The post Hybrid Cloud appeared first on WeCloudData. It has emerged as a pivotal strategy for organizations aiming to balance scalability, agility, and control. The hybrid cloud empowers businesses to optimize performance, enhance security, and drive innovation.
I found the blog to be a comprehensive roadmap for data engineering in 2025. The blog narrates the gateway's purpose: simplifying access, enabling experimentation, achieving cost-efficiency, and providing auditing and platformization benefits.
The blog emphasizes the importance of starting with a clear client focus to avoid over-engineering and ensure user-centric development. link] Gunnar Morling: Revisiting the Outbox Pattern The blog is an excellent summary of the path we crossed with the outbox pattern and the challenges ahead.
An alternative is the RESTORE command, and it'll be the topic of this blog post. Time travel is a quite popular Delta Lake feature. But do you know it's not the single one you can use to interact with the past versions?
The feature looks amazing but hides some implementation challenges that we're going to see in this blog post. For over two years now you can leverage file triggers in Databricks Jobs to start processing as soon as a new file gets written to your storage.
After publishing a release of my blog post about the insertInto trap, I got an intriguing question in the comments. The alternative to the insertInto, the saveAsTable method, doesn't work well on partitioned data in overwrite mode while the insertInto does.
This blog describes the new change feed and snapshot capabilities in Apache Spark Structured Streamings State Reader API. The State Reader API enables.
In this blog post, well discuss our experiences in identifying the challenges associated with EC2 network throttling. In the remainder of this blog post, well share how we root cause and mitigate the aboveissues. This prompted us to engage with AWS and dive deep into the network performance of our clusters. 4xl with up to 12.5
In this blog, we will use a case study-Automated Resume Screening to understand […] The post NLP Project Life Cycle: A Case Study on Automated Resume Screening appeared first on WeCloudData.
The blog narrates how Apache Arrow offers better data serialization efficiency and avoids design pitfalls from the past. The blog stresses the need for granular, structured feedback, especially from experts, and outlines key considerations for evaluation design. years of manual effort!!!
This blog focuses […] The post Data Scientist Vs Data Analyst: Key Differences, Career Paths, and How to Choose the Right Role appeared first on WeCloudData. The world is becoming increasingly reliant on data, about 2.5
This blog will explore the significant advancements, challenges, and opportunities impacting data engineering in 2025, highlighting the increasing importance for companies to stay updated. In 2025, this blog will discuss the most important data engineering trends, problems, and opportunities that companies should be aware of.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content