This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
TL;DR: Functional, Idempotent, Tested, Two-stage (FITT) data architecture has saved our sanity—no more 3 AM pipeline debugging sessions. The cloud has made it incredibly affordable to have copies of systems, tools, pipelines, and even data. Pipeline broke due to a schema change? Re-run the pipeline with debugging enabled.
billion by 2032, highlighting the critical need for efficient data pipeline management. While Airflow has long been a staple in the data engineering ecosystem, Dagster is emerging as a strong alternative, offering a fresh perspective on orchestration with enhanced functionality for data-aware pipelines. billion in 2024 to $924.39
We have also seen a fourth layer, the Platinum layer , in companies’ proposals that extend the Data pipeline to OneLake and Microsoft Fabric. The need to copy data across layers, manage different schemas, and address data latency issues can complicate data pipelines. However, this architecture is not without its challenges.
Ideal for: Business-centric workflows involving fabric Snowflake = environments with a lot of developers and data engineers 2. Ideal for: Fabric: Microsoft-centric organizations Snowflake: Multi-cloud flexibility seekers 3. Cloud support Microsoft Fabric: Works only on Microsoft Azure.
Unlocking Data Team Success: Are You Process-Centric or Data-Centric? We’ve identified two distinct types of data teams: process-centric and data-centric. We’ve identified two distinct types of data teams: process-centric and data-centric. They work in and on these pipelines.
impactdatasummit.com Thumbtack: What we learned building an ML infrastructure team at Thumbtack Thumbtack shares valuable insights from building its ML infrastructure team. The blog emphasizes the importance of starting with a clear client focus to avoid over-engineering and ensure user-centric development.
Have you ever considered the challenges data professionals face when building complex AI applications and managing large-scale data interactions? These obstacles usually slow development, increase the likelihood of errors and make it challenging to build robust, production-grade AI applications that adapt to evolving business requirements.
Read this dbt (data build tool) Snowflake tutorial blog to leverage the combined potential of dbt, the ultimate data transformation tool, and Snowflake, the scalable cloud data warehouse, to create efficient data pipelines. dbt and Snowflake: Building the Future of Data Engineering Together." Why Use dbt With Snowflake?
Google BigQuery Project Ideas GCP Project to Learn Using BigQuery for Exploring Data Check out the blog on 15 Sample GCP Project Ideas for more interesting use cases of Google BigQuery. Google BigQuery Google BigQuery is a fully managed, serverless, and highly scalable data warehouse solution offered by Google Cloud.
This blog is your roadmap in navigating the Amazon Data Engineer Interview landscape, providing valuable insights, strategies, and practical tips to crack the interview and thrive in the dynamic world of data engineering. Build a unique job-winning data engineer resume with big data mini projects.
Discover the perfect synergy between Kubernetes and Data Science as we unveil a treasure trove of innovative Data Science Kubernetes projects in this blog. Data scientists can practice Kubernetes projects to gain proficiency in deploying and managing data pipelines across cloud providers or on-premises infrastructure.
Becoming a successful aws data engineer demands you to learn AWS for data engineering and leverage its various services for building efficient business applications. AWS Data Engineering Tools Architecting Data Engineering Pipelines using AWS Data Ingestion - Batch and Streaming Data How to Transform Data to Optimize for Analytics?
Data Science The data science component streamlines the process of building, deploying, and operationalizing machine learning models. With Fabric, Aon can reduce the complexity of its analytics stack, allowing developers to spend less time on building infrastructure and more time on value-added activities for the business.
I know what I want to build. As AI applications become increasingly complex, AI engineers need more than prompt engineering to build reliable, production-grade systems. The core philosophies of LangChain and LangGraph represent distinct approaches to addressing AI challenges, particularly when building workflows.
And, out of these professions, we will focus on the data engineering job role in this blog and list out a comprehensive list of projects to help you prepare for the same. Build your Data Engineer Portfolio with ProjectPro!
This blog is your go-to guide for the top 21 big data tools, their key features, and some interesting project ideas that leverage these big data tools and technologies to gain hands-on experience on enterprise. Data scientists and engineers typically use the ETL (Extract, Transform, and Load) tools for data ingestion and pipeline creation.
GCP Data Engineers are highly-valued and in demand at top tech data-centric companies, and it has been reported that demand for them outweighs supply by a factor of 3 to 1. Data engineers require strong experience with multiple data storage technologies and frameworks to build data pipelines.
One thing that stands out to me is As AI-driven data workflows increase in scale and become more complex, modern data stack tools such as drag-and-drop ETL solutions are too brittle, expensive, and inefficient for dealing with the higher volume and scale of pipeline and orchestration approaches. We all bet on 2025 being the year of Agents.
Read this blog to find some of the best Data Science portfolio projects that elevate your skills, demonstrate your expertise, and help you land your dream data science job! Whether you are a beginner or a seasoned expert, data science projects are the most important thing for building a solid portfolio.
This blog will guide you through what to look for in an MLOps training program to ensure you gain the skills needed to excel. Managing these processes efficiently demands proficiency in cloud platforms, CI/CD pipelines , and containerization—areas that might be unfamiliar to those with a DevOps or software engineering background.
With Astro, you can build, run, and observe your data pipelines in one place, ensuring your mission critical data is delivered on time. This blog captures the current state of Agent adoption, emerging software engineering roles, and the use case category. link] Jack Vanlightly: Table format interoperability, future or fantasy?
OpenCV Project Ideas Explore hands-on learning by checking out this blog featuring 15 OpenCV project ideas tailored for beginners in 2023. It is one of Python's fundamental building blocks for data manipulation and analysis. dependent packages and 43.4K dependent repositories. Matplotlib is primarily designed for static graphics.
This blog post is your one-stop guide to mastering the LLM interview. Then, you slowly build upon it, brick by brick. Explain the RAG pipeline and each component. The Retrieval-Augmented Generation (RAG) pipeline tackles a fundamental limitation of Large Language Models (LLMs) – their reliance on pre-trained data.
So, if you are looking to build a career in cloud computing and don't know where to start, this blog can help you with all your solutions. A cloud engineer builds and maintains the cloud infrastructure. In other words, a cloud engineer builds and maintains the cloud infrastructure in any big data project.
Whether you are a cloud computing beginner or a tech enthusiast, this blog is the pathway to mastering AWS services and transforming your career in cloud computing. And by the end of this blog, you will be well on your way to a successful career in cloud computing ! It's a starting point for building expertise in cloud technology.
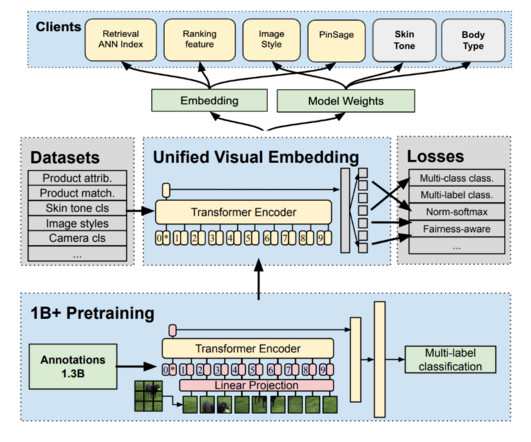
Our commitment is evidenced by our history of building products that champion inclusivity. We know from experience that building for marginalized communities helps make the product work better for everyone. To ensure an unbiased approach, we also leveraged our skin tone and hair pattern signals when building this dataset.
Software projects of all sizes and complexities have a common challenge: building a scalable solution for search. Building a resilient and scalable solution is not always easy. It involves many moving parts, from data preparation to building indexing and query pipelines. You might be wondering, is this a good solution?
Segment created the Unify product to reduce the burden of building a comprehensive view of customers and synchronizing it to all of the systems that need it. In this episode Kevin Niparko and Hanhan Wang share the details of how it is implemented and how you can use it to build and maintain rich customer profiles.
link] Chip Huyan: Building A Generative AI Platform We can’t deny that Gen-AI is becoming an integral part of product strategy, pushing the need for platform engineering. The blog is an excellent summarization of the common patterns emerging in GenAI platforms. Pipeline breakpoint feature.
This introductory blog focuses on an overview of our journey. Future blogs will provide deeper dives into each service, sharing insights and lessons learned from this process. Future blogs will provide deeper dives into each service, sharing insights and lessons learned from this process.
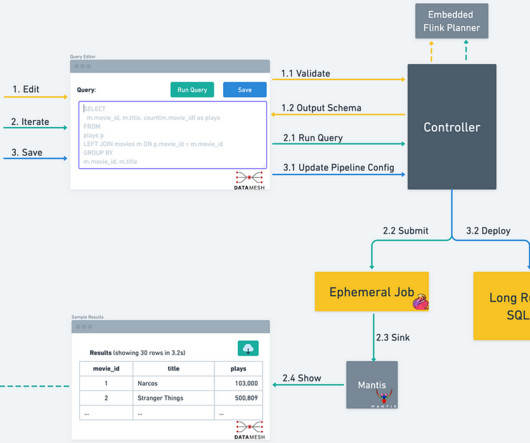
On the Data Platform team, we build the infrastructure used across the company to process data at scale. In our last blog post, we introduced “Data Mesh” — A Data Movement and Processing Platform. When a user wants to leverage Data Mesh to move and transform data, they start by creating a new Data Mesh pipeline.
Learn More → AI Verify Foundation: Model AI Governance Framework for Generative AI Several countries are working on building governance rules for Gen AI. The author highlights the structured approach to building data infrastructure, data management, and metrics. TIL that the queryable state is deprecated, which surprises me too.
NVidia released Eagle a vision-centric multimodal LLM — Look at the example in the Github repo, given an image and a user input the LLM is able to answer things like "Describe the image in detail" or "Which car in the picture is more aerodynamic" based on a drawing. How the UK football rely heavily on data?
DataOps is fundamentally about eliminating errors, reducing cycle time, building trust and increasing agility. The data pipelines must contend with a high level of complexity – over seventy data sources and a variety of cadences, including daily/weekly updates and builds.
Cloudera has partnered with Cisco in helping build the Cisco Validated design (CVD) for Apache Ozone. Look at details of volumes/buckets/keys/containers/pipelines/datanodes. Given a file, find out what nodes/pipeline is it part of. Cloudera will publish separate blog posts with results of performance benchmarks.
For modern data engineers using Apache Spark, DE offers an all-inclusive toolset that enables data pipeline orchestration, automation, advanced monitoring, visual troubleshooting, and a comprehensive management toolset for streamlining ETL processes and making complex data actionable across your analytic teams. Job Deployment Made Simple.
To enable LGIM to better utilize its wealth of data, LGIM required a centralized platform that made internal data discovery easy for all teams and could securely integrate external partners and third-party outsourced data pipelines. The post Cloudera Customer Story appeared first on Cloudera Blog. Please read the full story here.
Take Astro (the fully managed Airflow solution) for a test drive today and unlock a suite of features designed to simplify, optimize, and scale your data pipelines. The blog is a good overview of various components in a typical data stack. I often wonder if we are building a pyramid infrastructure scheme on top of the object storage.
Here is the agenda, 1) Data Application Lifecycle Management - Harish Kumar( Paypal) Hear from the team in PayPal on how they build the data product lifecycle management (DPLM) systems. 4) Building Data Products and why should you? link] Nvidia: What Is Sovereign AI?
Streamlit has rapidly become the de facto way to build UIs for LLM-powered apps. Get smarter about your data with native LLMs Additionally, Snowflake is building LLMs directly into the platform to help customers boost productivity and unlock new insights from their data. Read this blog. And with LLMs, it’s no different.
Data engineers spend countless hours troubleshooting broken pipelines. Data plays a central role in modern organisations; the centricity here is not just a figure of speech, as data teams often sit between traditional IT and different business functions. More can be found in this blog. Know when to build and when to buy.
Unlike data scientists — and inspired by our more mature parent, software engineering — data engineers build tools, infrastructure, frameworks, and services. The fact that ETL tools evolved to expose graphical interfaces seems like a detour in the history of data processing, and would certainly make for an interesting blog post of its own.
This blog discusses quantifications, types, and implications of data. The activity in the field of learning with limited data is reflected in a variety of courses , workshops , reports , blogs and a large number of academic papers (a curated list of which can be found here ). Quantifications of data. Addressing the challenges of data.
It is amusing for a human being to write an article about artificial intelligence in a time when AI systems, powered by machine learning (ML), are generating their own blog posts. We also shed light on how we drove value by taking a user-centered approach while building this internal tool.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content