This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
quintillion bytes of data are generated every day and thats a great sign for anyone interested in a data-driven career. This blog focuses […] The post Data Scientist Vs Data Analyst: Key Differences, Career Paths, and How to Choose the Right Role appeared first on WeCloudData.
In this blog post, well discuss our experiences in identifying the challenges associated with EC2 network throttling. In the remainder of this blog post, well share how we root cause and mitigate the aboveissues. This prompted us to engage with AWS and dive deep into the network performance of our clusters. 4xl with up to 12.5
Instead, in this post I will point you to an earlier blog post where I already answered that question and then I will focus on what should be your next question: now that I’m relying on Jaeger to trace how data is flowing through my distributed system, what if Jaeger goes down? Distributed tracing with Apache Kafka and Jaeger.
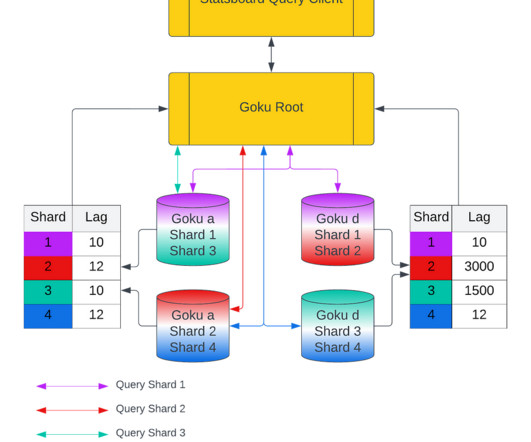
In the first blog, we will share a short summary on the GokuS and GokuL architecture, data format for Goku Long Term, and how we improved the bootstrap time for our storage and serving components. More information about the architecture can be found in the GokuL blog and the cost reduction blog.
Cost increases when gradient accumulation is enabled, or becomes ~free if used in concert with DDP DDP usually costs ~4 bytes/param, but becomes cheaper if used in concert with AMP DDP can be made 2.5 Transformer Math does not mention a "4 bytes/param master gradients" cost.
In this blog post, we will discuss the AvroTensorDataset API, techniques we used to improve data processing speeds by up to 162x over existing solutions (thereby decreasing overall training time by up to 66%), and performance results from benchmarks and production. an array within a map, within a union, etc…). Default is 128 * 1024 (128KB).
You can read previous blog posts on Impala’s performance and querying techniques here – “ New Multithreading Model for Apache Impala ”, “ Keeping Small Queries Fast – Short query optimizations in Apache Impala ” and “ Faster Performance for Selective Queries ”. . Total size of the Bucket is 16 bytes. Folding data into pointers.
The first level is a hashed string ID (the primary key), and the second level is a sorted map of a key-value pair of bytes. A future blog post will describe the chunking architecture in more detail, including its intricacies and optimization strategies. The idempotency token ties all these writes together into one atomic operation.
quintillion bytes of data are generated every day. The world is becoming increasingly dependent on data, about 2.5 Data is shaping our decisions, from personalized shopping experiences to checking weather forecasts before leaving home. All of these data science applications have a life cycle to follow.
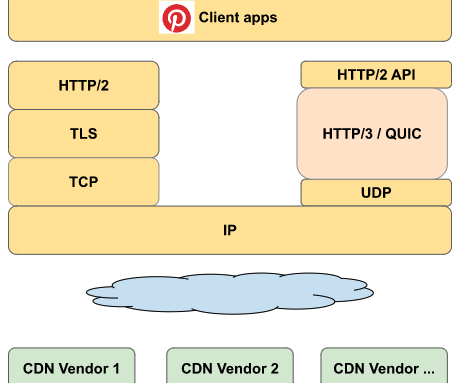
These advancements fit well with Pinterest use cases — enabling faster connection establishment (time to first byte of first request), improved congestion control (large media as we have), multiplexing without TCP head-of-line blocking (multiple downloads at the same time), and continued in-flight requests when pinners’ device network/ip changes.
Our Engineering Blog was launched in June 2020 after a long break of the previous tech blog. What customizations we applied to design the blog and the publishing process. Static Site Generator Our previous tech blog used a CMS which only a limited number of people had access to. So which static site generator to choose?
Our previous tech blog Packaging award-winning shows with award-winning technology detailed our packaging technology deployed on the streaming side. Writable MezzFS As described in a previous blog post, MezzFS is a tool developed by Netflix that allows cloud storage objects to be mounted as local files via FUSE.
Introduction This blog post describes a recent contribution from Zalando to the Postgres JDBC driver to address a long-standing issue with the driver’s integration with Postgres’ logical replication that resulted in runaway Write-Ahead Log (WAL) growth. However as you may imagine, this blog post concerns a path that is anything but happy.
In this blog we will dive into how CDF-PC’s support for NiFi reporting tasks can be used to monitor key metrics in Prometheus and Grafana. By using component_name and “Hello World Prometheus,” we’re monitoring the bytes received aggregated by the entire process group and therefore the flow. Select the nifi_amount_bytes_received metric.
Reading Time: 9 minutes In this blog, we will cover: What are Server-Sent Events? We’re taking in 16 bytes of data at a time from the stream. This function will provide basic units of data in the form of raw bytes. These bytes can then be converted into a readable JSON format. appeared first on The Workfall Blog.
If you want to follow along and execute all the commands included in this blog post (and the next), you can check out this GitHub repository , which also includes the necessary Docker Compose functionality for running a compatible KSQL and Confluent Platform environment using the recently released Confluent 5.2.1. Sample repository.
In this blog post, we describe the journey DoorDash took using a service mesh to realize data transfer cost savings without sacrificing service quality. This led us to use a number of observability tools, including VPC flow logs , ebpf agent metrics , and Envoy networking bytes metrics to rectify the situation.
For a more detailed introduction to BPF portability and CO-RE, see Andrii Nakryiko’s blog post on the subject. We also have an unmarshalling function to convert the raw bytes from the kernel into our structure. The post BPFAgent: eBPF for Monitoring at DoorDash appeared first on DoorDash Engineering Blog.
This blog would be of immense help to understand what happens under the hood with AWS blue/green deployment! The diff_bytes is 0 now! We now need to reset sequences in, which we accomplished with the following script: [link] This ensures that the sequence starts from the last entry of the individual tables.
This blog discusses quantifications, types, and implications of data. The International Data Corporation (IDC) estimates that by 2025 the sum of all data in the world will be in the order of 175 Zettabytes (one Zettabyte is 10^21 bytes). The post The Rise of Unstructured Data appeared first on Cloudera Blog.
Refer to the YARN – The Capacity Scheduler blog to understand these configuration settings.) . This can be tuned using the user limit factor of the YARN queue (refer the details in Capacity Scheduler blog ). Tez determines the reducers automatically based on the data (number of bytes) to be processed.
This blog post explores how Snowflake can help with this challenge. In the cloud, computing can be measured in various ways, like bytes scanned or CPU cycles. But what if security teams didn’t have to make tradeoffs? Detection and investigation processing: Security teams depend on detection rules to find important events automatically.
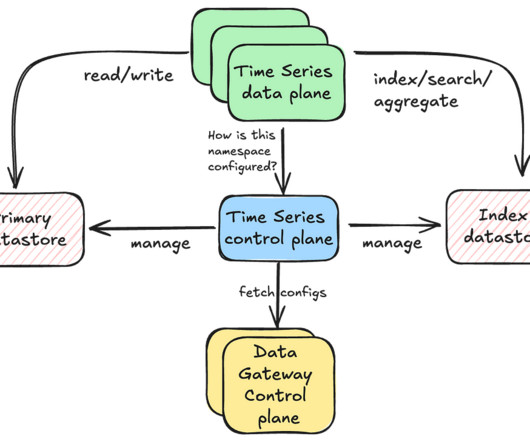
In previous blog posts, we introduced the Key-Value Data Abstraction Layer and the Data Gateway Platform , both of which are integral to Netflix’s data architecture. We may go into detail on this subject in one of our future blog posts. The next section describes how this is achieved.
I’ve written an event sourcing bank simulation in Clojure (a lisp build for Java virtual machines or JVMs) called open-bank-mark , which you are welcome to read about in my previous blog post explaining the story behind this open source example. Make sure it is indeed an ID and that the Value matches the expected type Fixed , with 16 bytes.
In this blog, I will demonstrate how COD can easily be used as a backend system to store data and images for a simple web application. The post Building a Simple CRUD web application and image store using Cloudera Operational Database and Flask appeared first on Cloudera Blog.
Github writes an excellent blog to capture the current state of the LLM integration architecture. The blog is an excellent read to understand late-arriving data, backfilling, and incremental processing complications. I experienced similar drawbacks to what Lyft is talking about in Druid. Rebalancing, the awkward middle child.
By Cyril Concolato Introduction In previous blog posts, our colleagues at Netflix have explained how 4K video streams are optimized , how even legacy video streams are improved and more recently how new audio codecs can provide better aural experiences to our members. Figure 1?—?Simplified
Espresso System Overview Figure 1 is a high-level overview of the Espresso ecosystem, which includes the online operation section of Espresso (the main focus of this blog post). Improvements to Encode/Decode performance This section focuses on the performance improvements we made when converting bytes to Http objects and vice versa.
Pyoung = Seden / Ralloc where Pyoung is the period between young GC, Seden is the size of Eden and Ralloc is the rate of memory allocations (bytes per second). To learn more about engineering at Pinterest, check out the rest of our Engineering Blog and visit our Pinterest Labs site.
If a consumer is only interested in production titles and format, they can set a FieldMask with paths “title” and “format”: [link] Masking fields Please note, even though code samples in this blog post are written in Java, demonstrated concepts apply to any other language supported by protocol buffers. Field names are not included.
In this blog series, we will discuss each of these deployments and the deployment choices made along with how they impact reliability. The post Apache Kafka Deployments and Systems Reliability – Part 1 appeared first on Cloudera Blog. There are many ways that Apache Kafka has been deployed in the field.
We will cover the different namespaces of Netflix Drive in more detail in a subsequent blog post. Data Store Characteristics Netflix Drive relies on a data store that allows streaming bytes into files/objects persisted on the storage media. The transfer mechanism for transport of bytes is a function of the data store.
Introduction This series of blog posts discusses the methods of estimating carbon emissions of end-user devices. After intending to write a single blog post, the research journey prompted me to reconsider how to present this to an audience. js is a javascript library that returns an estimated CO2e value for a web page.
This blog post is my note after reading the paper: The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing. In the rest of this blog, we will see how Google enables this contribution. See you next blog!
This blog is your comprehensive guide to Google BigQuery, its architecture, and a beginner-friendly tutorial on how to use Google BigQuery for your data warehousing activities. This blog presents a detailed overview of Google BigQuery and its architecture. Due to this, combining and contrasting the STRING and BYTE types is impossible.
The ML for large-scale production systems highlights the improvement made from the existing heuristic in the YouTube cache replacement algorithm with a new hybrid algorithm that combines a simple heuristic with a learned model, improving the byte miss ratio at the peak by ~9%. The blog talks about four types of architecture.
The target could be a particular Node (network endpoint), a file-system, a directory, a data-file or a byte-offset range within a given data-file. The post Apache Ozone Fault Injection Framework appeared first on Cloudera Blog. A Typical flow control for Apache Ozone using this Fault Injection Framework looks like this: .
Check out this informative blog for more details on how S5cmd works and its significant performance advantages. Here we show how to download specific byte-ranges of the file using the Boto3 get_object data streaming API. CPU cores and TCP connections). The S5cmd concurrency flag allows for controlling the download speed.
This is a guest blog post, authored by John Zantey, Director and Co-founder, Qabsu. Globally, there are quintillions of bytes of data being generated and collected, every day. The post Collaboration is Key to Reducing Pain and Finding Value in Data appeared first on Cloudera Blog. collect, enrich, report, serve, and predict).
The repository’s README contains a bit more detail, but in a nutshell, we check out the repo and then use Gradle to initiate docker-compose : git clone [link] cd kafka-examples git checkout confluent-blog./gradlew jar Zip file size: 5849 bytes, number of entries: 5. jar Zip file size: 11405084 bytes, number of entries: 7422.
sent 11,286 bytes received 172 bytes 2,546.22 However, we can continue without enabling TLS for the purpose of this blog. The post HDFS Data Encryption at Rest on Cloudera Data Platform appeared first on Cloudera Blog. [root@ccycloud-4 ~]# rsync -zav --exclude.ssl /var/lib/keytrustee/.keytrustee keytrustee ccycloud-3.cdpvcb.root.hwx.site:/var/lib/keytrustee/.
Blog Data Quality + Data Lineage = Written by Peter Hicks on Sep 2, 2021 In a prior life, I dwelled in the day-to-day cycles of an e-commerce platform. In previous blog posts, we’ve talked before about the importance of understanding data lineage from debugging to privacy and governance.
This blog discusses a few problems that you might encounter with Iceberg tables and offers strategies on how to optimize them in each of those scenarios. In a later blog, we will go into details about how to take advantage of the time travel feature. The rest of the blog will go into this in more detail. Opening files is costly.
In this blog post, I will explain the underlying technical challenges and share the solution that we helped implement at kaiko.ai , a MedTech startup in Amsterdam that is building a Data Platform to support AI research in hospitals. A solution is to read the bytes that we need when we need them directly from Blob Storage.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content