This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Built for the AI era, Components offers compartmentalized code units with proper guardrails that prevent "AI slop" while supporting code generation. The blog is an excellent compilation of types of query engines on top of the lakehouse, its internal architecture, and benchmarking against various categories.
Instead, in this post I will point you to an earlier blog post where I already answered that question and then I will focus on what should be your next question: now that I’m relying on Jaeger to trace how data is flowing through my distributed system, what if Jaeger goes down? Distributed tracing with Apache Kafka and Jaeger.
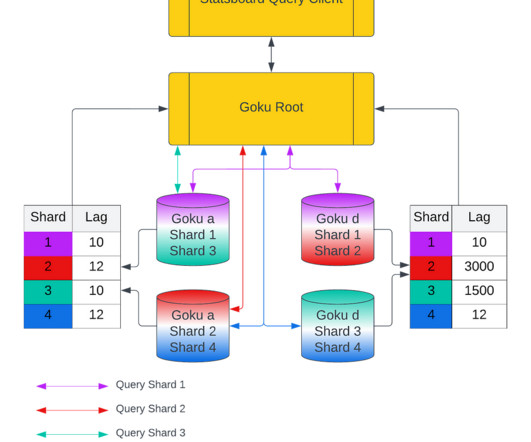
In the first blog, we will share a short summary on the GokuS and GokuL architecture, data format for Goku Long Term, and how we improved the bootstrap time for our storage and serving components. More information about the architecture can be found in the GokuL blog and the cost reduction blog.
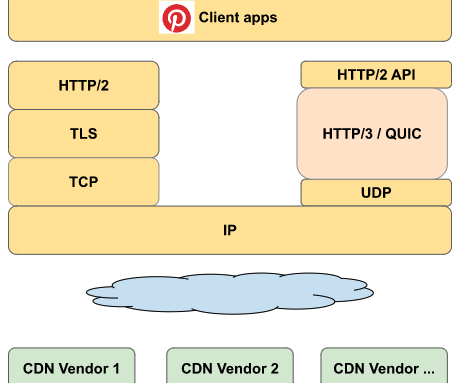
These advancements fit well with Pinterest use cases — enabling faster connection establishment (time to first byte of first request), improved congestion control (large media as we have), multiplexing without TCP head-of-line blocking (multiple downloads at the same time), and continued in-flight requests when pinners’ device network/ip changes.
In this blog post, we will discuss the AvroTensorDataset API, techniques we used to improve data processing speeds by up to 162x over existing solutions (thereby decreasing overall training time by up to 66%), and performance results from benchmarks and production. an array within a map, within a union, etc…). Default is 128 * 1024 (128KB).
Impala has always focused on efficiency and speed, being written in C++ and effectively using techniques such as runtime code generation and multithreading. For instance, in both the struct s above the largest member is a pointer of size 8 bytes. Total size of the Bucket is 16 bytes. Folding data into pointers.
Reading Time: 9 minutes In this blog, we will cover: What are Server-Sent Events? Fast to code : It enables considerable speed increases in development. Short : It reduces code duplication. Robust : It delivers production-ready code with interactive documentation. Then, we’ll dive into the server-side code.
We’ll demonstrate using Gradle to execute and test our KSQL streaming code, as well as building and deploying our KSQL applications in a continuous fashion. The first requirement to tackle: how to express dependencies between KSQL queries that exist in script files in a source code repository. Sample repository. gradlew composeUp.
Introduction This blog post describes a recent contribution from Zalando to the Postgres JDBC driver to address a long-standing issue with the driver’s integration with Postgres’ logical replication that resulted in runaway Write-Ahead Log (WAL) growth. However as you may imagine, this blog post concerns a path that is anything but happy.
Our Engineering Blog was launched in June 2020 after a long break of the previous tech blog. What customizations we applied to design the blog and the publishing process. Static Site Generator Our previous tech blog used a CMS which only a limited number of people had access to. So which static site generator to choose?
For a more detailed introduction to BPF portability and CO-RE, see Andrii Nakryiko’s blog post on the subject. The Cilium project has an exceptional cilium/ebpf Golang library that compiles and interacts with eBPF probes within Golang code. The probe runners follow a standard pattern.
In this blog post, we describe the journey DoorDash took using a service mesh to realize data transfer cost savings without sacrificing service quality. This led us to use a number of observability tools, including VPC flow logs , ebpf agent metrics , and Envoy networking bytes metrics to rectify the situation.
I’ve written an event sourcing bank simulation in Clojure (a lisp build for Java virtual machines or JVMs) called open-bank-mark , which you are welcome to read about in my previous blog post explaining the story behind this open source example. Rust is a compiled language, so code needs to be compiled first in order to be executed.
If a consumer is only interested in production titles and format, they can set a FieldMask with paths “title” and “format”: [link] Masking fields Please note, even though code samples in this blog post are written in Java, demonstrated concepts apply to any other language supported by protocol buffers. Field names are not included.
Instead, we chose to use an envoy circuitbreaker , which returns an HTTP 503 code immediately to the downstream caller. This blog would be of immense help to understand what happens under the hood with AWS blue/green deployment! The diff_bytes is 0 now!
This blog discusses quantifications, types, and implications of data. The International Data Corporation (IDC) estimates that by 2025 the sum of all data in the world will be in the order of 175 Zettabytes (one Zettabyte is 10^21 bytes). The post The Rise of Unstructured Data appeared first on Cloudera Blog.
In this blog, I will demonstrate how COD can easily be used as a backend system to store data and images for a simple web application. All code is in my github repo. Going through The Code. Hope you find it useful, Happy coding!! Auto-tune – better performance within the existing infrastructure footprint.
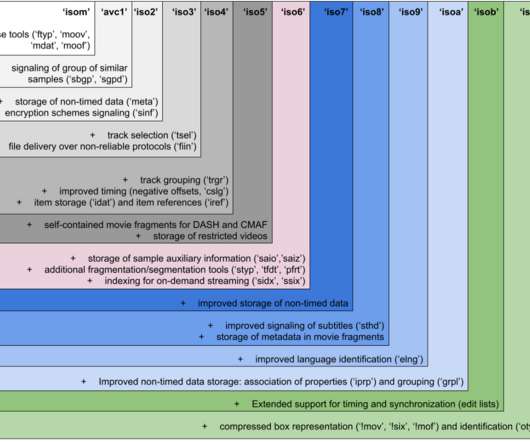
By Cyril Concolato Introduction In previous blog posts, our colleagues at Netflix have explained how 4K video streams are optimized , how even legacy video streams are improved and more recently how new audio codecs can provide better aural experiences to our members. Figure 1?—?Simplified Figure 2?—?Illustrating Brands are nested.
This framework does not require any code changes to the system-under-test that is being validated. Over time we can do more intrusive whitebox testing by enabling and disabling various join points and delay-points within the Ozone code. No changes to Ozone code required for simulating failures. How does it work?
The code block below includes snippets for: creating a file with random data and uploading it to Amazon S3 (using boto3), iterating over all of the samples sequentially, and sampling the data at non-sequential file offsets. Check out this informative blog for more details on how S5cmd works and its significant performance advantages.
Better performance, lower cost and less code complexity Xiao Li, Kapil Bajaj, Monil Mukesh Sanghavi and Zhenxiao Luo Introduction In the dynamic arena of real-time analytics, the need for precision and speed is non-negotiable. To assess the frequency of these GC pauses, we measure the time interval between each young collection.
As discussed in part 2, I created a GitHub repository with Docker Compose functionality for starting a Kafka and Confluent Platform environment, as well as the code samples mentioned below. We provide the functions: prefix to reference the subproject directory with our code. jar Zip file size: 5849 bytes, number of entries: 5.
The ML for large-scale production systems highlights the improvement made from the existing heuristic in the YouTube cache replacement algorithm with a new hybrid algorithm that combines a simple heuristic with a learned model, improving the byte miss ratio at the peak by ~9%. The blog talks about four types of architecture.
This blog is your comprehensive guide to Google BigQuery, its architecture, and a beginner-friendly tutorial on how to use Google BigQuery for your data warehousing activities. This blog presents a detailed overview of Google BigQuery and its architecture. Due to this, combining and contrasting the STRING and BYTE types is impossible.
Full code on GitHub. Note that the MappingProcessor and FilteringProcessor code is omitted here for clarity. Full code on GitHub. Full code on GitHub. We will use his tool to generate graphical illustrations of all topologies in this blog post. Full code on GitHub. println(builder. filter((k,v) -> v.
In this blog post, we will focus on the latter feature set. The challenge, then, is to be able to ingest and process these events in a scalable manner, i.e., scaling with the number of devices, which will be the focus of this blog post. In particular, the Kafka integration is the most relevant for this blog post.
This three part blog post series covers the efficiency improvements (view parts 1 and parts 2 ), and this final part will cover the reduction of the overall cost of Goku and Pinterest. We had to make sure the code changes did not affect the query SLA we had set with the client team. Goku Root routes the queries to GokuS andGokuL.
This blog post is my note after reading the paper: The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing. In the rest of this blog, we will see how Google enables this contribution. Triggering at completion estimates such as watermarks.
In this blog post, I will explain the underlying technical challenges and share the solution that we helped implement at kaiko.ai , a MedTech startup in Amsterdam that is building a Data Platform to support AI research in hospitals. A solution is to read the bytes that we need when we need them directly from Blob Storage.
88% of respondents “Always” or “Often” use Types in their Python code. The blog further gives insight into IDE usage and documentation access. Lack of Byte String Support : It is difficult to handle binary data efficiently. Meta published the state of the type hint usage of Python.
Based on benchmarks and blog posts out in the wild, brotli is able to get text-like payloads (HTML, Javascript, CSS) about 5–15% smaller than the gzipped size, and it’s not especially slower or more resource-intensive during decompression. When we enabled brotli in a straightforward manner, it reduced bytes sent as expected.
We shall now move forward in this Java Tutorial for beginners blog by explaining each aspect of Java. . It allows you to create reusable code and standard projects. . Platform-independent Java Code. Communication between objects is not limited to knowing the details of their data or code. Why Should You Learn Java? .
I feel comfortable debugging complex issues, such identifying those caused by garbage collection, and improving our code to alleviate the pauses (see Martin Thompson’s blog post or Aleksey Shipilёv’s JVM Anatomy Park ). I didn’t mind the boilerplate code too much if it didn’t get in the way of expressing the intent of the code.
In this blog, we will look at the differences between programming and web development, focusing on the key differences between these two related but distinct fields to help you decide which career path to take. Programming is the process of developing software or applications by coding in a specific language. What is Programming?
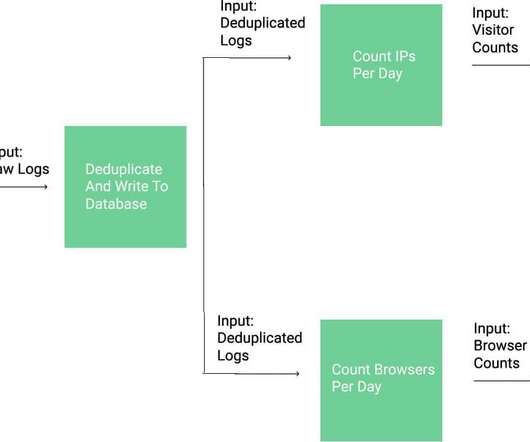
In this blog post, we’ll use data from web server logs to answer questions about our visitors. If you’re unfamiliar, every time you visit a web page, such as the Dataquest Blog , your browser is sent data from a web server. To host this blog, we use a high-performance web server called Nginx. PingdomPageSpeed/1.0
This blog post takes an engineer’s perspective. With all other technologies that are experiencing some level of hype, low-code for example, the only parties that stand to benefit significantly from the hype are those who are actively investing in the technology itself, building products and solutions.
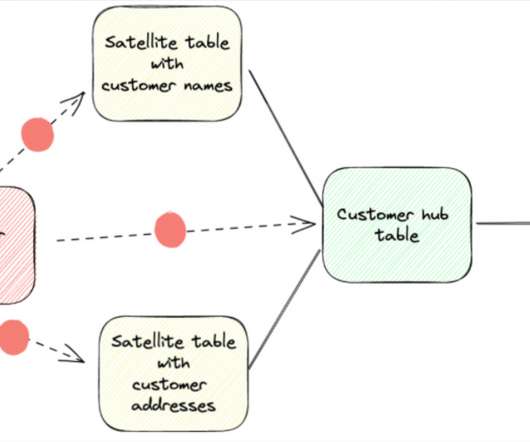
In this blog post we’ll dive into data vault architecture; challenges and best practices for maintaining data quality; and how data observability can help. The other advantage is because we follow a standard design, we are able to generate a lot of our code using code templates and metadata. What is a Data Vault model?
Looking around the internet, there are few approaches people will blog about but many would either cost too much, be really complicated to setup/maintain, or both. Despite the relative simplicity of the code, the cluster resources necessary are significant. Our first Spark-based attempt at solving this problem falls under “both.”
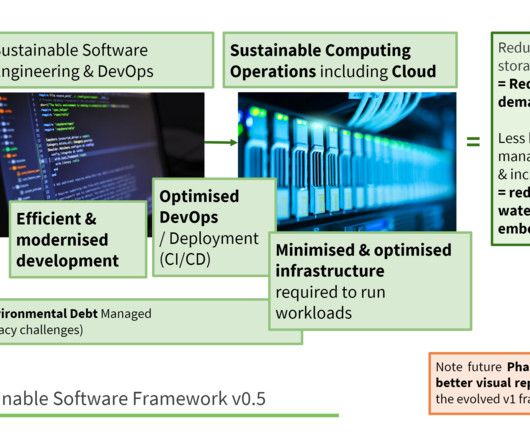
This is the first in our latest series of blogs on sustainable technology that will explore these issues and, where possible, offer pragmatic suggestions that hopefully raise thought-provoking questions to ask yourself, your suppliers, and technology teams. Software has real world impacts and the cloud is not ephemeral.
My first stop was the Zalando Engineering Blog - a real treasure for someone like me who was curious about the engineering culture and practices at what would be my new company. Since I love reading and writing blog posts, I even dreamt of contributing here someday. What's Next?
For the purpose of this article it is sufficient to know that Kafka Connect is a powerful framework to stream data in and out of Kafka at scale while requiring a minimal amount of code because the Connect framework handles most of the life cycle management of connectors already. MySQL CDC with Kafka Connect/Debezium in CDP Public Cloud.
Get FREE Access to Data Analytics Example Codes for Data Cleaning, Data Munging, and Data Visualization Example of a Class Variable Declaration in Java Public class Product { public static int Barcode; } Instance variables belong to an object and are specified without a static modifier. code to handle Exception.
In this blog, I aim to give you the zest of the following topics: What is DevSecOps ? Automated security testing, code analysis, and deployment pipelines make it possible to quickly respond to emerging threats, find security flaws, and enforce policy compliance. Core Values of DevSecOps How is DevSecOps different from DevOps ?
You then control the controller by providing colour data as an RGB byte sequence using just a single pin. This can greatly simplify application code by removing the need to explicitly maintain state machines and poll routines. For example, here’s the guts of the code from that post - let mut switch_state = switch_pin.is_low ().unwrap
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content