This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction This blog post describes a recent contribution from Zalando to the Postgres JDBC driver to address a long-standing issue with the driver’s integration with Postgres’ logical replication that resulted in runaway Write-Ahead Log (WAL) growth. However as you may imagine, this blog post concerns a path that is anything but happy.
Instead, in this post I will point you to an earlier blog post where I already answered that question and then I will focus on what should be your next question: now that I’m relying on Jaeger to trace how data is flowing through my distributed system, what if Jaeger goes down? Distributed tracing with Apache Kafka and Jaeger.
I’ve written an event sourcing bank simulation in Clojure (a lisp build for Java virtual machines or JVMs) called open-bank-mark , which you are welcome to read about in my previous blog post explaining the story behind this open source example. The schemas are also useful for generating specific Java classes.
Java-enabled general-purpose computers, mobile devices, and other handheld gadgets are a part of everyone’s daily life now. As a result, we can see that Java is one of the most widely used programming languages today. Therefore, our Java for beginners tutorial is here to educate the audience en masse. . Advantages of Java .
If a consumer is only interested in production titles and format, they can set a FieldMask with paths “title” and “format”: [link] Masking fields Please note, even though code samples in this blog post are written in Java, demonstrated concepts apply to any other language supported by protocol buffers. Field names are not included.
The repository’s README contains a bit more detail, but in a nutshell, we check out the repo and then use Gradle to initiate docker-compose : git clone [link] cd kafka-examples git checkout confluent-blog./gradlew We used Groovy instead of Java to write our UDFs, so we’ve applied the groovy plugin. gradlew composeUp. version = '1.0.0'.
Hiring managers agree that “Java is one of the most in-demand and essential skill for Hadoop jobs. But how do you get one of those hot java hadoop jobs ? You have to ace those pesky java hadoop job interviews artfully. To demonstrate your java and hadoop skills at an interview, preparation is vital.
If you want to follow along and execute all the commands included in this blog post (and the next), you can check out this GitHub repository , which also includes the necessary Docker Compose functionality for running a compatible KSQL and Confluent Platform environment using the recently released Confluent 5.2.1. Sample repository.
sent 11,286 bytes received 172 bytes 2,546.22 However, we can continue without enabling TLS for the purpose of this blog. TO ' rangerkms '@'localhost' IDENTIFIED BY ' Hadoop_123 '; Download and install mysql java connector jar: $ wget [link]. tar zxvf mysql-connector-java-5.1.46.tar.gz. mysql-connector-java-5.1.46-bin.jar
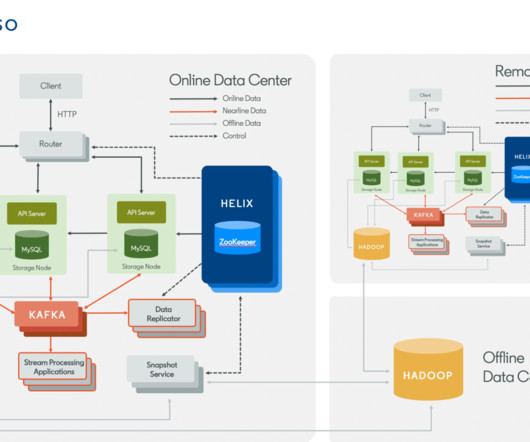
Espresso System Overview Figure 1 is a high-level overview of the Espresso ecosystem, which includes the online operation section of Espresso (the main focus of this blog post). Enabling Native SSL encryption/decryption Java's default built-in SSL implementation carries a significant performance overhead.
Pyoung = Seden / Ralloc where Pyoung is the period between young GC, Seden is the size of Eden and Ralloc is the rate of memory allocations (bytes per second). To learn more about engineering at Pinterest, check out the rest of our Engineering Blog and visit our Pinterest Labs site.
This blog post is my note after reading the paper: The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing. In the rest of this blog, we will see how Google enables this contribution. Triggering at completion estimates such as watermarks.
I find there is a lot of good work making the Java Virtual Machine very efficient and very fast, utilizing the underlying infrastructure well. I liked Java. It was a simple enough service, accepting bytes from the customer device (using a REST API) and writing them to disk. You can visit this blog post for more detail.
In this blog, we will look at the differences between programming and web development, focusing on the key differences between these two related but distinct fields to help you decide which career path to take. Programming languages such as Python, Ruby, and Java are used to write code that can be executed by a computer.
This means that the Impala authors had to go above and beyond to integrate it with different Java/Python-oriented systems. RocksDB is a storage engine with a key/value interface, where keys and values are arbitrary byte streams written as a C++ library. Follow JetBrains Big Data Tools on Twitter and subscribe to our blog for more news!
This means that the Impala authors had to go above and beyond to integrate it with different Java/Python-oriented systems. RocksDB is a storage engine with a key/value interface, where keys and values are arbitrary byte streams written as a C++ library. Follow JetBrains Big Data Tools on Twitter and subscribe to our blog for more news!
This is just a hypothetical case that we are talking about and if you prepare well, you will be able to answer any HBase Interview Question, during your next Hadoop job interview, having read ProjectPro Hadoop Interview Questions blogs. To iterate through these values in reverse order-the bytes of the actual value should be written twice.
This blog helps you understand the critical differences between two popular big data frameworks. The library is available in Java , Scala, Python, and R. The persist() method supports the following storage levels: MEMORY_ONLY: RDDs are stored as deserialized Java objects in JVM. Will Apache Spark Eliminate Hadoop MapReduce?
This blog brings you the most popular Kafka interview questions and answers divided into various categories such as Apache Kafka interview questions for beginners, Advanced Kafka interview questions/Apache Kafka interview questions for experienced, Apache Kafka Zookeeper interview questions, etc. config/server.properties 25.
The distributed execution engine in the Spark core provides APIs in Java, Python, and Scala for constructing distributed ETL applications. The following are the persistence levels available in Spark: MEMORY ONLY: This is the default persistence level, and it's used to save RDDs on the JVM as deserialized Java objects. getOrCreate() Q7.
This blog walks you through what does Snowflake do , the various features it offers, the Snowflake architecture, and so much more. BigQuery charges users depending on how many bytes are read or scanned. Launched in 2014, Snowflake is one of the most popular cloud data solutions on the market.
In this blog, we'll dive into some of the most commonly asked big data interview questions and provide concise and informative answers to help you ace your next big data job interview. Hadoop can execute MapReduce applications in various languages, including Java, Ruby, Python, and C++.
Each file has a 150 byte cost in NameNode memory, and HDFS has a limited number of overall IOPS. However, files are written to disk, in many cases, with compression, and in a format that is significantly different than the format of your records stored in the Java heap. However, there is a cost. Airbnb is hiring!
Whether you are just starting your career as a Data Engineer or looking to take the next step, this blog will walk you through the most valuable data engineering certifications and help you make an informed decision about which one to pursue. Why Are Data Engineering Skills In Demand? big data and ETL tools, etc. PREVIOUS NEXT <
One petabyte is equivalent to 20 million filing cabinets; worth of text or one quadrillion bytes. Related Posts How much Java is required to learn Hadoop? petabytes of unstructured data from 1 million customers every hour. If you want to work with one of the world's largest retail dataset, then drop us an email to care@projectpro.io
We can probably write a separate blog post about the security, scalability, extensibility and a few other compulsory properties to make it production ready. The main idea here is to avoid conflicts with Java 9 module system files and ensure smooth merging of other files. java ) where user code will be written. py , Program123.java
In this blog post, well explore how weve created our Feature Backfill Solution , leveraging various techniques to reduce costs and iteration time by up to90x. For the remainder of this blog post, we will specify user id as the entitykey. Stay tuned for future blog posts as we unveil more about thisjourney. Medium, 14 Mar.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content