This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Using Jaeger tracing, I’ve been able to answer an important question that nearly every Apache Kafka ® project that I’ve worked on posed: how is data flowing through my distributed system? Distributed tracing with Apache Kafka and Jaeger. Example of a Kafka project with Jaeger tracing. What does this all mean?
There are many ways that Apache Kafka has been deployed in the field. In our Kafka Summit 2021 presentation, we took a brief overview of many different configurations that have been observed to date. In this blog series, we will discuss each of these deployments and the deployment choices made along with how they impact reliability.
Put another way, courtesy of Spencer Ruport: LISTENERS are what interfaces Kafka binds to. Apache Kafka ® is a distributed system. You need to tell Kafka how the brokers can reach each other but also make sure that external clients (producers/consumers) can reach the broker they need to reach. Is anyone listening? on AWS, etc.)
I’ve written an event sourcing bank simulation in Clojure (a lisp build for Java virtual machines or JVMs) called open-bank-mark , which you are welcome to read about in my previous blog post explaining the story behind this open source example. Also, there are several functions wrapping the Java clients for Kafka.
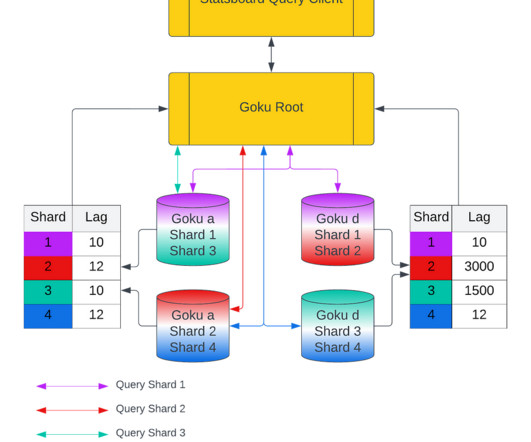
In the first blog, we will share a short summary on the GokuS and GokuL architecture, data format for Goku Long Term, and how we improved the bootstrap time for our storage and serving components. This is because the synthetic data points would be present in the retry kafka waiting to be pushed into the recovering host by the retry ingestor.
In part 1 , we discussed an event streaming architecture that we implemented for a customer using Apache Kafka ® , KSQL from Confluent, and Kafka Streams. In part 3, we’ll explore using Gradle to build and deploy KSQL user-defined functions (UDFs) and Kafka Streams microservices. Sample repository. gradlew composeUp.
With the release of Apache Kafka ® 2.1.0, Kafka Streams introduced the processor topology optimization framework at the Kafka Streams DSL layer. In what follows, we provide some context around how a processor topology was generated inside Kafka Streams before 2.1, Kafka Streams topology generation 101.
As discussed in part 2, I created a GitHub repository with Docker Compose functionality for starting a Kafka and Confluent Platform environment, as well as the code samples mentioned below. jar Zip file size: 5849 bytes, number of entries: 5. jar Zip file size: 11405084 bytes, number of entries: 7422. Kafka Streams.
Franz Kafka, 1897. Load balancing and scheduling are at the heart of every distributed system, and Apache Kafka ® is no different. Kafka clients—specifically the Kafka consumer, Kafka Connect, and Kafka Streams, which are the focus in this post—have used a sophisticated, paradigmatic way of balancing resources since the very beginning.
In this post I will demonstrate how Kafka Connect is integrated in the Cloudera Data Platform (CDP), allowing users to manage and monitor their connectors in Streams Messaging Manager while also touching on security features such as role-based access control and sensitive information handling. Kafka Connect. Streams Messaging Manager.
Streaming data from Apache Kafka into Delta Lake is an integral part of Scribd’s data platform, but has been challenging to manage and scale. We use Spark Structured Streaming jobs to read data from Kafka topics and write that data into Delta Lake tables. To serve this need, we created kafka-delta-ingest.
In this blog post, we will focus on the latter feature set. The challenge, then, is to be able to ingest and process these events in a scalable manner, i.e., scaling with the number of devices, which will be the focus of this blog post. In particular, the Kafka integration is the most relevant for this blog post.
In this blog post, we describe the journey DoorDash took using a service mesh to realize data transfer cost savings without sacrificing service quality. Storage traffic: Includes traffic from microservices to stateful systems such as Aurora PostgreSQL, CockroachDB, Redis, and Kafka.
Jeff Xiang | Senior Software Engineer, Logging Platform; Vahid Hashemian | Staff Software Engineer, LoggingPlatform When it comes to PubSub solutions, few have achieved higher degrees of ubiquity, community support, and adoption than Apache Kafka, which has become the industry standard for data transportation at large scale.
When there is a full GC, it leads to full halt to the data processing pipeline and causes both back-pressure for upstream kafka clusters and cascading failure for downstream TSDB. Pyoung = Seden / Ralloc where Pyoung is the period between young GC, Seden is the size of Eden and Ralloc is the rate of memory allocations (bytes per second).
Github writes an excellent blog to capture the current state of the LLM integration architecture. The blog is an excellent read to understand late-arriving data, backfilling, and incremental processing complications. link] Sophie Blee-Goldman: Kafka Streams and Rebalancing through the Ages Consumers come and go.
For a more detailed introduction to BPF portability and CO-RE, see Andrii Nakryiko’s blog post on the subject. We also have an unmarshalling function to convert the raw bytes from the kernel into our structure. The post BPFAgent: eBPF for Monitoring at DoorDash appeared first on DoorDash Engineering Blog.
Your search for Apache Kafka interview questions ends right here! Let us now dive directly into the Apache Kafka interview questions and answers and help you get started with your Big Data interview preparation! How to study for Kafka interview? What is Kafka used for? What are main APIs of Kafka?
RocksDB is a storage engine with a key/value interface, where keys and values are arbitrary byte streams written as a C++ library. Kafka: Mark KRaft as Production Ready – One of the most interesting changes to Kafka from recent years is that it now works without ZooKeeper. Of course, the main topic is data streaming.
RocksDB is a storage engine with a key/value interface, where keys and values are arbitrary byte streams written as a C++ library. Kafka: Mark KRaft as Production Ready – One of the most interesting changes to Kafka from recent years is that it now works without ZooKeeper. Of course, the main topic is data streaming.
This three part blog post series covers the efficiency improvements (view parts 1 and parts 2 ), and this final part will cover the reduction of the overall cost of Goku and Pinterest. Gokus ingestor component consumes from this Kafka topic and then produces into another kafka topic (partition corresponds to GokuSshard).
Our esteemed roundtable included leading practitioners, thought leaders and educators in the space, including: Ben Rogojan , aka Seattle Data Guy , is a data engineering and data science consultant (now based in the Rocky Mountain city of Denver) with a popular YouTube channel , Medium blog , and newsletter. Doing the pre-work is important.
Logs-As-A-Stream Many messaging platforms, such as Kafka, Pulsar, and/or RabbitMQ have what they advertise as Stream s. FileInputStream In our example later, we are going to process blog posts to parse tag meta-data. class RealFakeInputStream [ T T ) extends InputStream { val data : Array [ Byte ] = "0123456789". run ( sink ).
This is just a hypothetical case that we are talking about and if you prepare well, you will be able to answer any HBase Interview Question, during your next Hadoop job interview, having read ProjectPro Hadoop Interview Questions blogs. To iterate through these values in reverse order-the bytes of the actual value should be written twice.
Recommended Reading: 100 Kafka Interview Questions and Answers 20 linear regression interview questions and answers Top 50 NLP Interview Questions and Answers Top 20 Logistic Regression Interview Questions and Answers How can you create a deep copy of the complete java object along with its state?
New input formats: Currently, the platform is supporting byte-based input. The post Meeting DoorDash Growth with a Self-Service Logistics Configuration Platform appeared first on DoorDash Engineering Blog. Having separate endpoints for them will keep the blast radius limited and isolated.
Whether you are just starting your career as a Data Engineer or looking to take the next step, this blog will walk you through the most valuable data engineering certifications and help you make an informed decision about which one to pursue. Why Are Data Engineering Skills In Demand?
For input streams receiving data through networks such as Kafka, Flume, and others, the default persistence level setting is configured to achieve data replication on two nodes to achieve fault tolerance. MEMORY ONLY SER: The RDD is stored as One Byte per partition serialized Java Objects. But the problem is, where do you start?
There are two big gaps in the Apache Kafka project when we think of operating a cluster. There are no solutions for these inside the Kafka project but there are many good 3rd party tools for both problems. Cruise Control is integrated with Kafka through metrics reporting. About Cruise Control. Architecture. Metrics Reporting.
I walk through an end to end integration of requesting data from the car, streaming it into a Kafka Topic and using Rockset to expose the data via its API to create real time visualisations in D3. Getting started with Kafka When starting with any new tool I find it best to look around and see the art of the possible.
The ML for large-scale production systems highlights the improvement made from the existing heuristic in the YouTube cache replacement algorithm with a new hybrid algorithm that combines a simple heuristic with a learned model, improving the byte miss ratio at the peak by ~9%. The blog talks about four types of architecture.
Its based on a talk I gave at one of our internal engineering meetups, adapted for a blog format. If we select Usage Type , we can see what exactly EC2-Other refersto: Okay, so the majority of the EC2-Other cost comes from a usage type called EUC1-DataTransfer-Regional-Bytes. Still not clear? Wait, what? Yes,really!
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content