This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The first level is a hashed string ID (the primary key), and the second level is a sorted map of a key-value pair of bytes. Chunked data can be written by staging chunks and then committing them with appropriate metadata (e.g. This model supports both simple and complex data models, balancing flexibility and efficiency.
In this blog post, we will discuss the AvroTensorDataset API, techniques we used to improve data processing speeds by up to 162x over existing solutions (thereby decreasing overall training time by up to 66%), and performance results from benchmarks and production. an array within a map, within a union, etc…). Default is 128 * 1024 (128KB).
In the first blog, we will share a short summary on the GokuS and GokuL architecture, data format for Goku Long Term, and how we improved the bootstrap time for our storage and serving components. More information about the architecture can be found in the GokuL blog and the cost reduction blog.
Our previous tech blog Packaging award-winning shows with award-winning technology detailed our packaging technology deployed on the streaming side. The inspection stage examines the input media for compliance with Netflix’s delivery specifications and generates rich metadata.
Our Engineering Blog was launched in June 2020 after a long break of the previous tech blog. What customizations we applied to design the blog and the publishing process. Static Site Generator Our previous tech blog used a CMS which only a limited number of people had access to. So which static site generator to choose?
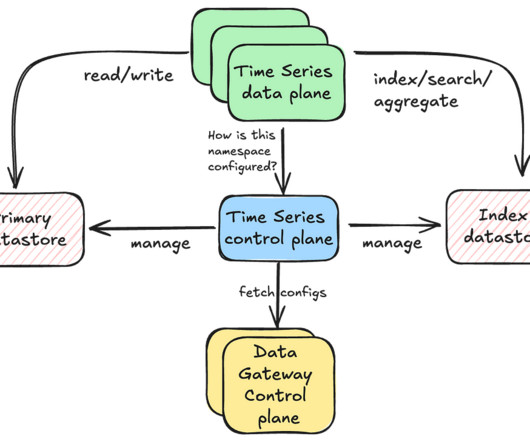
In previous blog posts, we introduced the Key-Value Data Abstraction Layer and the Data Gateway Platform , both of which are integral to Netflix’s data architecture. Metadata table : This table stores information about how each time slice is configured per namespace.
When a client (producer/consumer) starts, it will request metadata about which broker is the leader for a partition—and it can do this from any broker. The key thing is that when you run a client, the broker you pass to it is just where it’s going to go and get the metadata about brokers in the cluster from. The default is 0.0.0.0,
Netflix Drive relies on a data store that will be the persistent storage layer for assets, and a metadata store which will provide a relevant mapping from the file system hierarchy to the data store entities. 2 , are the file system interface, the API interface, and the metadata and data stores. The major pieces, as shown in Fig.
If you want to follow along and execute all the commands included in this blog post (and the next), you can check out this GitHub repository , which also includes the necessary Docker Compose functionality for running a compatible KSQL and Confluent Platform environment using the recently released Confluent 5.2.1. Sample repository.
One key part of the fault injection service is a very lightweight passthrough fuse file system that is used by Ozone for storing all its persistent data and metadata. The APIs are generic enough that we could target both Ozone data and metadata for failure/corruption/delays. NetFilter Extension. Fault Injection Framework: Github.
To prevent the management of these keys (which can run in the millions) from becoming a performance bottleneck, the encryption key itself is stored in the file metadata. Each file will have an EDEK which is stored in the file’s metadata. sent 11,286 bytes received 172 bytes 2,546.22 keytrustee ccycloud-3.cdpvcb.root.hwx.site:/var/lib/keytrustee/.
This blog discusses a few problems that you might encounter with Iceberg tables and offers strategies on how to optimize them in each of those scenarios. A bloated metadata.json file could increase both read/write times because a large metadata file needs to be read/written every time. Iceberg doesn’t delete the old data files.
The blog further gives insight into IDE usage and documentation access. The tool leverages a multi-agent system built on LangChain and LangGraph, incorporating strategies like quality table metadata, personalized retrieval, knowledge graphs, and Large Language Models (LLMs) for accurate query generation.
DataHub 0.8.36 – Metadata management is a big and complicated topic. DataHub is a completely independent product by LinkedIn, and the folks there definitely know what metadata is and how important it is. If you haven’t found your perfect metadata management system just yet, maybe it’s time to try DataHub!
DataHub 0.8.36 – Metadata management is a big and complicated topic. DataHub is a completely independent product by LinkedIn, and the folks there definitely know what metadata is and how important it is. If you haven’t found your perfect metadata management system just yet, maybe it’s time to try DataHub!
In this blog post, I will explain the underlying technical challenges and share the solution that we helped implement at kaiko.ai , a MedTech startup in Amsterdam that is building a Data Platform to support AI research in hospitals. A solution is to read the bytes that we need when we need them directly from Blob Storage. width , spec.
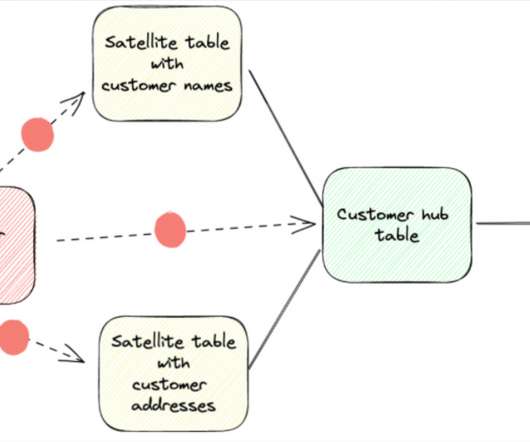
In this blog post we’ll dive into data vault architecture; challenges and best practices for maintaining data quality; and how data observability can help. architecture (with some minor deviations) to achieve their data integration objectives around scalability and use of metadata. “A What is a Data Vault model?
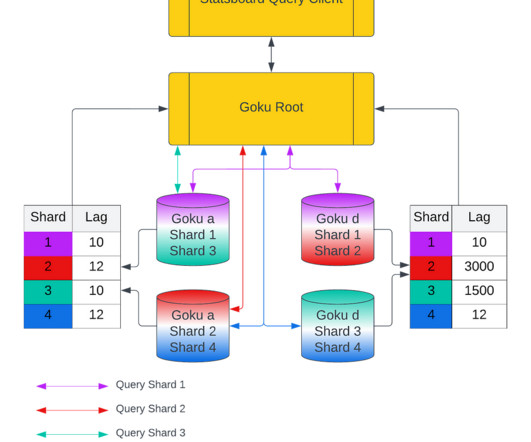
This three part blog post series covers the efficiency improvements (view parts 1 and parts 2 ), and this final part will cover the reduction of the overall cost of Goku and Pinterest. As explained in the overview of Goku architecture at the start of this blog, the compactor creates long term data ready for GokuL ingestion.
Looking around the internet, there are few approaches people will blog about but many would either cost too much, be really complicated to setup/maintain, or both. The user requirements are likely relatable to a lot of folks: My application emits data into Kafka that I want to analyze later.
We will use his tool to generate graphical illustrations of all topologies in this blog post. Of course, this would require you to have deep knowledge of Streams DSL topology generation internals (or to have been a reader of this blog post :)) in order to make the appropriate code changes. What’s next? release.
In this blog, we share the approach we took and the learnings wegained. While the tight coupling approach allows the native implementation of Tiered Storage to access Kafka internal protocols and metadata for a highly coordinated design, it also comes with limitations in realizing the full potential of Tiered Storage.
DoorDash’s internal platform team already has built many features which come in handy, like an Asgard-based microservice, which comes with a good set of built-in features like request-metadata, logging, and dynamic-value framework integration. New input formats: Currently, the platform is supporting byte-based input.
In this blog post, Palantir’s Information Security (InfoSec) team will share our recent experience using Cilium : an open-source project by Isovalent dedicated to securing container-based infrastructure, enabling visibility & controls preferable to those of a traditional firewall. Authors: Michael A. & & Sean C.
Run models & capture lineage metadata When working with Datakin (or any other OpenLineage backend) it’s important to generate the dbt docs first. Our schema has changed, and we want Datakin to have the latest metadata about tables and columns. % . % dbt debug Running with dbt=0.21.0 dbt version: 0.21.0 python version: 3.9.7
In this blog post, I'll describe how we use RocksDB at Rockset and how we tuned it to get the most performance out of it. For more details on leaf nodes, please refer to Aggregator Leaf Tailer blog post or Rockset white paper. RocksDB-Cloud replicates all the data and metadata for a RocksDB instance to S3.
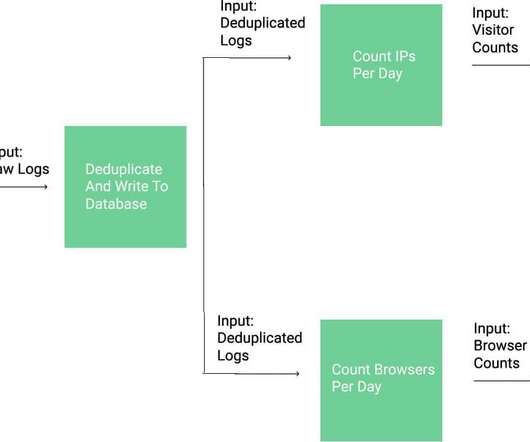
In this blog post, we’ll use data from web server logs to answer questions about our visitors. If you’re unfamiliar, every time you visit a web page, such as the Dataquest Blog , your browser is sent data from a web server. To host this blog, we use a high-performance web server called Nginx. PingdomPageSpeed/1.0
This is just a hypothetical case that we are talking about and if you prepare well, you will be able to answer any HBase Interview Question, during your next Hadoop job interview, having read ProjectPro Hadoop Interview Questions blogs. To iterate through these values in reverse order-the bytes of the actual value should be written twice.
This blog walks you through what does Snowflake do , the various features it offers, the Snowflake architecture, and so much more. This layer stores the metadata needed to optimize a query or filter data. For instance, only a small number of operations, such as deleting all of the records from a table, are metadata-only.
tesla-integration" You’ll notice in the results that not only will you see the lat and long you sent to the Kafka topic but some metadata that Rockset has added too including an ID, a timestamp and some Kafka metadata, this can be seen in Fig 2. select * from commons."tesla-integration" According to Postman that returned in 0.2
StructType is a collection of StructField objects that determines column name, column data type, field nullability, and metadata. To define the columns, PySpark offers the pyspark.sql.types import StructField class, which has the column name (String), column type (DataType), nullable column (Boolean), and metadata (MetaData).
In this blog, we'll dive into some of the most commonly asked big data interview questions and provide concise and informative answers to help you ace your next big data job interview. NameNode is often given a large space to contain metadata for large-scale files. And storing these metadata in RAM will become problematic.
This blog brings you the most popular Kafka interview questions and answers divided into various categories such as Apache Kafka interview questions for beginners, Advanced Kafka interview questions/Apache Kafka interview questions for experienced, Apache Kafka Zookeeper interview questions, etc. What do you understand about quotas in Kafka?
For a more concrete example, we are going to write a program that will parse markdown files, extract words identified as tags, and then regenerate those files with tag-related metadata injected back into them. FileInputStream In our example later, we are going to process blog posts to parse tag meta-data. collectAll [ String ].
The following blog post is a long one, but hang in there, it will be worth it. Did you know that by default, NPM keeps all the packages and metadata it ever downloads in its cache folder indefinitely? link] So what happens is that when you install things, NPM will store the tarballs and metadata into the packages folder.
Server logs might, for example, contain additional metadata such as the referring URL, HTTP status codes, bytes delivered, and user agents. If you enjoyed this blog on log files and want to dive deeper into the world of cybersecurity, consider enrolling in Edureka’s Cybersecurity Certification Course.
hey ( credits ) 🥹It's been a long time since I've put words down on paper or hit the keyboard to send bytes across the network. More than 5000 members subscribed to the newsletter and the blog generated almost 100k unique visitors. I'm writing this edition from my child's home, and it brings back memories.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content