This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Ready to boost your Hadoop DataLake security on GCP? Our latest blog dives into enabling security for Uber’s modernized batch datalake on Google CloudStorage!
Shared Data Experience ( SDX ) on Cloudera Data Platform ( CDP ) enables centralized data access control and audit for workloads in the Enterprise DataCloud. The public cloud (CDP-PC) editions default to using cloudstorage (S3 for AWS, ADLS-gen2 for Azure).
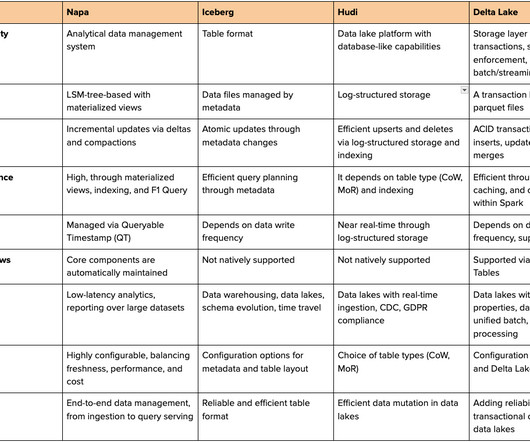
Open Table Format (OTF) architecture now provides a solution for efficient datastorage, management, and processing while ensuring compatibility across different platforms. In this blog, we will discuss: What is the Open Table format (OTF)? It can also be integrated into major data platforms like Snowflake.
A Drug Launch Case Study in the Amazing Efficiency of a Data Team Using DataOps How a Small Team Powered the Multi-Billion Dollar Acquisition of a Pharma Startup When launching a groundbreaking pharmaceutical product, the stakes and the rewards couldnt be higher. It is necessary to have more than a datalake and a database.
Apache Iceberg’s ecosystem of diverse adopters, contributors and commercial support continues to grow, establishing itself as the industry standard table format for an open data lakehouse architecture. Snowflake’s support for Iceberg Tables is now in public preview, helping customers build and integrate Snowflake into their lake architecture.
The Cloudera platform delivers a one-stop shop that allows you to store any kind of data, process and analyze it in many different ways in a single environment, and integrate with the rest of your data infrastructure. But working with cloudstorage has often been a compromise. As a Hadoop developer, I loved that!
The terms “ Data Warehouse ” and “ DataLake ” may have confused you, and you have some questions. Structuring data refers to converting unstructured data into tables and defining data types and relationships based on a schema. What is DataLake? . Athena on AWS. .
This blog post outlines detailed step by step instructions to perform Hive Replication from an on-prem CDH cluster to a CDP Public CloudDataLake. CDP DataLake cluster versions – CM 7.4.0, CDP DataLake cluster versions – CM 7.4.0, Pre-Check: DataLake Cluster.
With the addition of Google Cloud, we deliver on our vision of providing a hybrid and multi-cloud architecture to support our customer’s analytics needs regardless of deployment platform. . You could then use an existing pipeline to run analytics on the prepared data in BigQuery. .
Of high value to existing customers, Cloudera’s Data Warehouse service has a unique, separated architecture. . Separate storage. Cloudera’s Data Warehouse service allows raw data to be stored in the cloudstorage of your choice (S3, ADLSg2). Proprietary file formats mean no one else is invited in!
Summary Object storage is quickly becoming the unifying layer for data intensive applications and analytics. Modern, cloud oriented data warehouses and datalakes both rely on the durability and ease of use that it provides. How do you approach project governance and sustainability?
On May 3, 2023, Cloudera kicked off a contest called “Best in Flow” for NiFi developers to compete to build the best data pipelines. This blog is to congratulate our winner and review the top submissions. RK built some simple flows to pull streaming data into Google CloudStorage and Snowflake.
Cloudera Data Platform 7.2.1 introduces fine-grained authorization for access to Azure DataLakeStorage using Apache Ranger policies. Cloudera and Microsoft have been working together closely on this integration, which greatly simplifies the security administration of access to ADLS-Gen2 cloudstorage.
Mark: The first element in the process is the link between the source data and the entry point into the data platform. At Ramsey International (RI), we refer to that layer in the architecture as the foundation, but others call it a staging area, raw zone, or even a source datalake.
link] Uber: Enabling Security for Hadoop DataLake on Google CloudStorage Uber writes about securing a Hadoop-based datalake on Google Cloud Platform (GCP) by replacing HDFS with Google CloudStorage (GCS) while maintaining existing security models like Kerberos-based authentication.
alpha2 on the Cloudera Engineering blog, and 3.0.0 Improved support for cloudstorage systems like S3 (with S3Guard ), Microsoft Azure DataLake, and Aliyun OSS. appeared first on Cloudera Blog. The Apache Hadoop community recently released version 3.0.0 We covered earlier releases like 3.0.0-alpha1
Each workspace is associated with a collection of cloud resources. In the case of CDP Public Cloud, this includes virtual networking constructs and the datalake as provided by a combination of a Cloudera Shared Data Experience (SDX) and the underlying cloudstorage.
Data-in-motion is predominantly about streaming data so enterprises typically have two different ways or binary ways of looking at data. Stay tuned for Part II of our Q&A with Dinesh as we dive deeper into how live streaming data and technology is helping businesses within the financial service sector. .
Organizations find they have much more agility with analytics in the cloud and can operate at a lower cost point than has been possible with legacy on-premises solutions. Generally, instances for transient clusters need only minimal local disk space, since data processing runs directly on the data in the cloudstorage.
Data architecture is the organization and design of how data is collected, transformed, integrated, stored, and used by a company. If you are not familiar with the above-mentioned concepts, we suggest you to follow the links above to learn more about each of them in our blog posts.
Das Profil des Data Engineers: Big Data High-Tech Auch wenn Data Engineering von Hochschulen und Fortbildungsanbietern gerade noch etwas stiefmütterlich behandelt werden, werden der Einsatz und das daraus resultierende Anforderungsprofil eines Data Engineers am Markt recht eindeutig skizziert.
Tired of relentlessly searching for the most effective and powerful data warehousing solutions on the internet? This blog is your comprehensive guide to Google BigQuery, its architecture, and a beginner-friendly tutorial on how to use Google BigQuery for your data warehousing activities. Search no more! Did you know ?
Storage Services Azure Blob Storage, Azure Files, Azure Tables, Azure Queues, and Azure DataLakeCloud SQL, Cloud Spanner, BigTable, CloudStorage, and BigQuery 4. Azure vs. Google Cloud: Market Position Among the major players in cloud platforms are Microsoft Azure and Google Cloud Platform.
This position requires knowledge of Microsoft Azure services such as Azure Data Factory, Azure Stream Analytics, Azure Databricks, Azure Cosmos DB, and Azure Storage. To store various types of data, various methods are used. Conclusion So this was all about the Azure data engineer skills.
Another element that can be identified in both services is the copy operation, with the help of which data can be transferred between different systems and formats. This activity is rather critical of migrating data, extending cloud and on-premises deployments, and getting data ready for analytics.
Data pipelines are a significant part of the big data domain, and every professional working or willing to work in this field must have extensive knowledge of them. Generally, data pipelines are created to store data in a data warehouse or datalake or provide information directly to the machine learning model development.
IT Professionals looking to work in the cloud domain are expected to have a sound understanding of Azure tools as well as development and monitoring tools. This blog walks you through the top Azure Monitoring and Development that every SRE and DevOps engineer must know.
Fivetran Fivetran is a popular cloud-based data integration platform that simplifies the process of data engineering by automating data pipeline creation, management, and maintenance. Cloud Composer can integrate with other GCP services like BigQuery, CloudStorage, and Cloud Dataflow.
Data professionals who work with raw data like data engineers, data analysts, machine learning scientists , and machine learning engineers also play a crucial role in any data science project. And, out of these professions, this blog will discuss the data engineering job role.
Planning to land a successful job as an Azure Data Engineer? Read this blog till the end to learn more about the roles and responsibilities, necessary skillsets, average salaries, and various important certifications that will help you build a successful career as an Azure Data Engineer. The final step is to publish your work.
of data engineer job postings on Indeed? If you are still wondering whether or why you need to master SQL for data engineering, read this blog to take a deep dive into the world of SQL for data engineering and how it can take your data engineering skills to the next level.
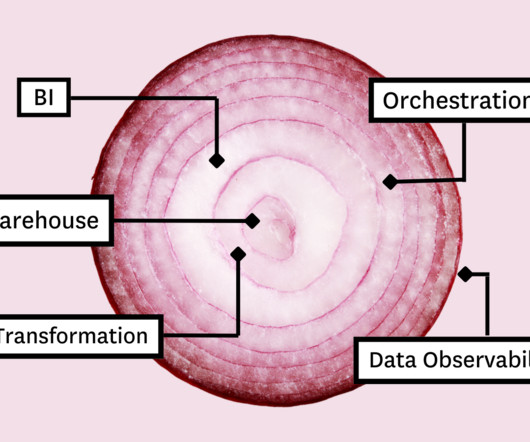
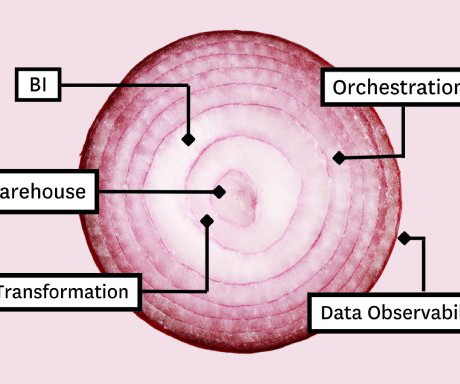
In this article, we’ll present you with the Five Layer Data Stack—a model for platform development consisting of five critical tools that will not only allow you to maximize impact but empower you to grow with the needs of your organization. Before you can model the data for your stakeholders, you need a place to collect and store it.
Those tools include: Table of Contents Cloudstorage and compute Data transformation Business Intelligence (BI) Data observability Data orchestration The most important part? Cloudstorage and compute Whether you’re stacking data tools or pancakes, you always build from the bottom up.
The world of data management is undergoing a rapid transformation. The rise of cloudstorage, coupled with the increasing demand for real-time analytics, has led to the emergence of the Data Lakehouse. This paradigm combines the flexibility of datalakes with the performance and reliability of data warehouses.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content