This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Unlock the power of scalable cloudstorage with Azure Blob Storage! This Azure Blob Storage tutorial offers everything you need to know to get started with this scalable cloudstorage solution. By 2030, the global cloudstorage market is likely to be worth USD 490.8
It also integrates with cloudstorage for added flexibility. mlruns This command uses an SQLite database for metadatastorage and saves artifacts in the mlruns directory. This format includes the model and its metadata. Metadata has the models framework, version, and dependencies.
Key components include metadata management, federation middleware, and role-based access controls to ensure governance and compliance. Connecting distributed sources The process starts by connecting to various data sources like relational databases, NoSQL databases, APIs, and cloudstorage systems.
With this public preview, those external catalog options are either “GLUE”, where Snowflake can retrieve table metadata snapshots from AWS Glue Data Catalog, or “OBJECT_STORE”, where Snowflake retrieves metadata snapshots directly from the specified cloudstorage location. Now, Snowflake can make changes to the table.
Open Table Format (OTF) architecture now provides a solution for efficient data storage, management, and processing while ensuring compatibility across different platforms. In this blog, we will discuss: What is the Open Table format (OTF)? Why should we use it? A Brief History of OTF A comparative study between the major OTFs.
Performance is one of the key, if not the most important deciding criterion, in choosing a Cloud Data Warehouse service. In this blog post, we compare Cloudera Data Warehouse (CDW) on Cloudera Data Platform (CDP) using Apache Hive-LLAP to Microsoft HDInsight (also powered by Apache Hive-LLAP) on Azure using the TPC-DS 2.9
We can store the data and metadata in a checkpointing directory. In Spark, checkpointing may be used for the following data categories- Metadata checkpointing: Metadata rmeans information about information. It refers to storing metadata in a fault-tolerant storage system such as HDFS. appName('ProjectPro').getOrCreate()
Our previous tech blog Packaging award-winning shows with award-winning technology detailed our packaging technology deployed on the streaming side. Table 1: Movie and File Size Examples Initial Architecture A simplified view of our initial cloud video processing pipeline is illustrated in the following diagram.
To help you prepare for your data warehouse engineer interview, we have included a list of some popular Snowflake interview questions and answers in this blog. The data is organized in a columnar format in the Snowflake cloudstorage. How does Snowflake store data? Is Snowflake an ETL tool? Define staging in Snowflake.
CDP One is a new service from Cloudera that is the first data lakehouse SaaS offering with cloud compute, cloudstorage, machine learning (ML), streaming analytics, and enterprise grade security built-in. Secure single tenant cloud infrastructure. The post Accelerate Analytics for All appeared first on Cloudera Blog.
Customers who have chosen Google Cloud as their cloud platform can now use CDP Public Cloud to create secure governed data lakes in their own cloud accounts and deliver security, compliance and metadata management across multiple compute clusters. A provisioning Service Account with these roles assigned.
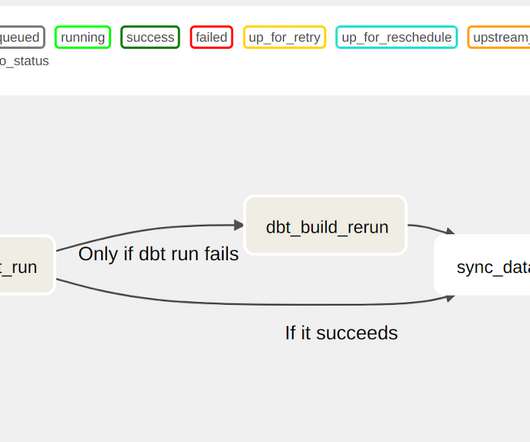
Read this blog till the end to learn everything you need to know about Airflow DAG. This blog will dive into the details of Apache Airflow DAGs, exploring how they work and multiple examples of using Airflow DAGs for data processing and automation workflows. Apache Airflow DAGs are your one-stop solution!
This blog post serves as a dev diary of the process, covering our challenges, contributions made and attempts to validate them. We started to consider breaking the components down into different plugins, which could be used for more than just cloudstorage.
Netflix Drive relies on a data store that will be the persistent storage layer for assets, and a metadata store which will provide a relevant mapping from the file system hierarchy to the data store entities. 2 , are the file system interface, the API interface, and the metadata and data stores. A sample manifest file.
By separating the compute, the metadata, and data storage, CDW dynamically adapts to changing workloads and resource requirements, speeding up deployment while effectively managing costs – while preserving a shared access and governance model. Separate storage.
Replication Manager can be used to migrate Apache Hive, Apache Impala, and HDFS objects from CDH clusters to CDP Public Cloud clusters. This blog post outlines detailed step by step instructions to perform Hive Replication from an on-prem CDH cluster to a CDP Public Cloud Data Lake. This blog post is not a substitute for that.
In the previous blog posts in this series, we introduced the N etflix M edia D ata B ase ( NMDB ) and its salient “Media Document” data model. NMDB is built to be a highly scalable, multi-tenant, media metadata system that can serve a high volume of write/read throughput as well as support near real-time queries.
YARN allows you to use various data processing engines for batch, interactive, and real-time stream processing of data stored in HDFS or cloudstorage like S3 and ADLS. Coordinates distribution of data and metadata, also known as shards. For the examples presented in this blog, we assume you have a CDP account already.
The Ranger Authorization Service (RAZ) is a new service added to help provide fine-grained access control (FGAC) for cloudstorage. We covered the value this new capability provides in a previous blog. Regardless of the storage type or location, all is handled consistently and audited on a per user basis. Conclusion.
This shift presents abundant career opportunities, especially in big data and cloud computing , as businesses increasingly rely on cloud technologies. Therefore, gaining hands-on experience through practical projects in cloud computing is now essential for anyone looking to excel in this field.
Are you looking to choose the best cloud data warehouse for your next big data project? This blog presents a detailed comparison of two of the very famous cloud warehouses - Redshift vs. BigQuery - to help you pick the right solution for your data warehousing needs. The global data warehousing market will likely reach $51.18
In terms of data analysis, as soon as the front-end visualization or BI tool starts accessing the data, the CDW Hive virtual warehouse will spin up cloud computing resources to combine the persisted historical data from the cloudstorage with the latest incremental data from Kafka into a transparent real-time view for the users.
We recently completed a project with IMAX, where we learned that they had developed a way to simplify and optimize the process of integrating Google CloudStorage (GCS) with Bazel. In this blog post, we’ll dive into the features, installation, and usage of rules_gcs , and how it provides you with access to private resources.
Foundational to the data fabric are metadata driven pipelines for scalability and resiliency, a unified view of the data from source through to the data products, and the ability to operate across a hybrid, multi-cloud environment. . The post Demystifying Modern Data Platforms appeared first on Cloudera Blog.
This blog comprehensively overviews Amazon Rekognition's features , use cases, architecture, pricing, projects, etc. Additionally, there's a separate charge for storing face metadata objects necessary for face and user search functionalities. Face metadatastorage for face search incurs monthly charges.
In the case of CDP Public Cloud, this includes virtual networking constructs and the data lake as provided by a combination of a Cloudera Shared Data Experience (SDX) and the underlying cloudstorage. Further auditing can be enabled at a session level so administrators can request key metadata about each CML process.
It serves as a foundation for the entire data management strategy and consists of multiple components including data pipelines; , on-premises and cloudstorage facilities – data lakes , data warehouses , data hubs ;, data streaming and Big Data analytics solutions ( Hadoop , Spark , Kafka , etc.);
The architecture is three layered: Database Storage: Snowflake has a mechanism to reorganize the data into its internal optimized, compressed and columnar format and stores this optimized data in cloudstorage. Snowflake allows the loading of both structured and semi-structured datasets from cloudstorage.
Multi-Cloud Management. Single-cloud visibility with Cloudera Manager. Single-cloud visibility with Ambari. Policy-Driven CloudStorage Permissions. The post The value of CDP Public Cloud over legacy Hadoop-on-IaaS implementations appeared first on Cloudera Blog. Workload Management. Not available.
DataHub 0.8.36 – Metadata management is a big and complicated topic. DataHub is a completely independent product by LinkedIn, and the folks there definitely know what metadata is and how important it is. If you haven’t found your perfect metadata management system just yet, maybe it’s time to try DataHub!
DataHub 0.8.36 – Metadata management is a big and complicated topic. DataHub is a completely independent product by LinkedIn, and the folks there definitely know what metadata is and how important it is. If you haven’t found your perfect metadata management system just yet, maybe it’s time to try DataHub!
One is data at rest, for example in a data lake, warehouse, or cloudstorage and from there they can do analytics on this data and that is predominantly around what has already happened or around how to prevent something from happening in the future.
This activity is rather critical of migrating data, extending cloud and on-premises deployments, and getting data ready for analytics. In this all-encompassing tutorial blog, we are going to give a detailed explanation of the Copy activity with special attention to datastores, file type, and options. can be ingested in Azure.
Read this blog to know how various data-specific roles, such as data engineer, data scientist, etc., Refining and enhancing local and metadata models. In the thought process of making a career transition from ETL developer to data engineer job roles? billion to USD 87.37 billion in 2025.
To prevent the management of these keys (which can run in the millions) from becoming a performance bottleneck, the encryption key itself is stored in the file metadata. Each file will have an EDEK which is stored in the file’s metadata. However, we can continue without enabling TLS for the purpose of this blog.
popular SQL and NoSQL database management systems including Oracle, SQL Server, Postgres, MySQL, MongoDB, Cassandra, and more; cloudstorage services — Amazon S3, Azure Blob, and Google CloudStorage; message brokers such as ActiveMQ, IBM MQ, and RabbitMQ; Big Data processing systems like Hadoop ; and. ZooKeeper issue.
If you want to follow along and execute all the commands included in this blog post (and the next), you can check out this GitHub repository , which also includes the necessary Docker Compose functionality for running a compatible KSQL and Confluent Platform environment using the recently released Confluent 5.2.1. Sample repository.
Because Altus Data Warehouse uses open source formats and the data resides in your cloudstorage rather than in a proprietary data store, there is no concern about vendor lock-in. Altus Data Warehouse is not like other cloud data warehouses. The post Altus Data Warehouse appeared first on Cloudera Blog.
Before Confluent Cloud was announced , a managed service for Apache Kafka did not exist. This blog post goes over: The complexities that users will run into when self-managing Apache Kafka on the cloud and how users can benefit from building event streaming applications with a fully managed service for Apache Kafka.
In this blog post, I will explain the underlying technical challenges and share the solution that we helped implement at kaiko.ai , a MedTech startup in Amsterdam that is building a Data Platform to support AI research in hospitals. A solution is to read the bytes that we need when we need them directly from Blob Storage. width , spec.
And, out of these professions, this blog will discuss the data engineering job role. Then, the Yelp dataset downloaded in JSON format is connected to Cloud SDK, following connections to Cloudstorage which is then connected with Cloud Composer. The Yelp dataset JSON stream is published to the PubSub topic.
From the Airflow side A client has 100 data pipelines running via a cron job in a GCP (Google Cloud Platform) virtual machine, every day at 8am. In a Google CloudStorage bucket. This is the same sensibility expressed in the dbt viewpoint in 2016, the closest thing to a founding blog post as exists for dbt. ]
The CDC system then periodically polls the source file system to check for any new files using the file metadata it stored earlier as a reference. Any new files are then captured and their metadata stored too. Along with the data, the path of the file and the source system it was captured from is also stored.
AWS S3 Interview Questions and Answers Amazon S3 (Simple Storage Service) is a secure, scalable, and durable cloudstorage solution designed for a wide range of use cases, from backup and archiving to big data analytics. Storage: Amazon S3 with intelligent tiering for video storage.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content