
How I Optimized Large-Scale Data Ingestion
databricks
SEPTEMBER 6, 2024
Explore being a PM intern at a technical powerhouse like Databricks, learning how to advance data ingestion tools to drive efficiency.

databricks
SEPTEMBER 6, 2024
Explore being a PM intern at a technical powerhouse like Databricks, learning how to advance data ingestion tools to drive efficiency.
Netflix Tech
MARCH 7, 2023
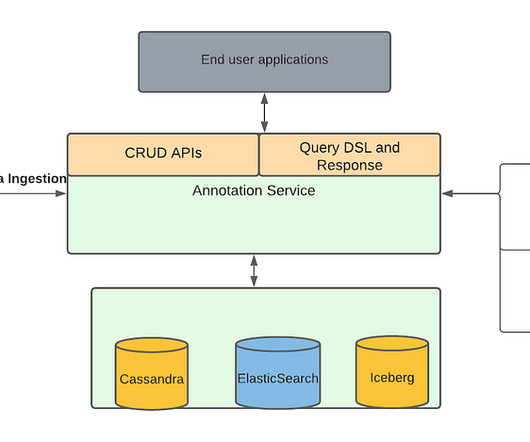
These media focused machine learning algorithms as well as other teams generate a lot of data from the media files, which we described in our previous blog , are stored as annotations in Marken. We refer the reader to our previous blog article for details. Marken Architecture Marken’s architecture diagram is as follows.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.
databricks
DECEMBER 10, 2024
Data engineering teams are frequently tasked with building bespoke ingestion solutions for myriad custom, proprietary, or industry-specific data sources. Many teams find that.

Cloudera
DECEMBER 4, 2024
For more than a decade, Cloudera has been an ardent supporter and committee member of Apache NiFi, long recognizing its power and versatility for data ingestion, transformation, and delivery. and discover how it can transform your data pipelines, watch this video.

Snowflake
MARCH 2, 2023
This solution is both scalable and reliable, as we have been able to effortlessly ingest upwards of 1GB/s throughput.” Rather than streaming data from source into cloud object stores then copying it to Snowflake, data is ingested directly into a Snowflake table to reduce architectural complexity and reduce end-to-end latency.

Databand.ai
JULY 19, 2023
Complete Guide to Data Ingestion: Types, Process, and Best Practices Helen Soloveichik July 19, 2023 What Is Data Ingestion? Data Ingestion is the process of obtaining, importing, and processing data for later use or storage in a database. In this article: Why Is Data Ingestion Important?

DataKitchen
NOVEMBER 5, 2024
You have typical data ingestion layer challenges in the bronze layer: lack of sufficient rows, delays, changes in schema, or more detailed structural/quality problems in the data. Data missing or incomplete at various stages is another critical quality issue in the Medallion architecture.

Expert insights. Personalized for you.








































Let's personalize your content