This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Since it takes so long to iterate on workflows, some ML engineers started to perform dataprocessing directly inside training jobs. This is what we commonly refer to as Last Mile DataProcessing. Last Mile processing can boost ML engineers’ velocity as they can write code in Python, directly using PyTorch.
The Race For Data Quality In A Medallion Architecture The Medallion architecture pattern is gaining traction among data teams. It is a layered approach to managing and transforming data. By systematically moving data through these layers, the Medallion architecture enhances the data structure in a data lakehouse environment.
I can now begin drafting my dataingestion/ streaming pipeline without being overwhelmed. With careful consideration and learning about your market, the choices you need to make become narrower and more clear. I'll use Python and Spark because they are the top 2 requested skills in Toronto.
The blog took out the last edition’s recommendation on AI and summarized the current state of AI adoption in enterprises. The simplistic model expressed in the blog made it easy for me to reason about the transactional system design. Kafka is probably the most reliable data infrastructure in the modern data era.
Complete Guide to DataIngestion: Types, Process, and Best Practices Helen Soloveichik July 19, 2023 What Is DataIngestion? DataIngestion is the process of obtaining, importing, and processingdata for later use or storage in a database.
When you deconstruct the core database architecture, deep in the heart of it you will find a single component that is performing two distinct competing functions: real-time dataingestion and query serving. When dataingestion has a flash flood moment, your queries will slow down or time out making your application flaky.
[link] Georg Heiler: Upskilling data engineers What should I prefer for 2028, or how can I break into data engineering? I honestly don’t have a solid answer, but this blog is an excellent overview of upskilling. These are common LinkedIn requests.
In addition to big data workloads, Ozone is also fully integrated with authorization and data governance providers namely Apache Ranger & Apache Atlas in the CDP stack. While we walk through the steps one by one from dataingestion to analysis, we will also demonstrate how Ozone can serve as an ‘S3’ compatible object store.
For organizations who are considering moving from a legacy data warehouse to Snowflake, are looking to learn more about how the AI Data Cloud can support legacy Hadoop use cases, or are struggling with a cloud data warehouse that just isn’t scaling anymore, it often helps to see how others have done it.
Data transformation helps make sense of the chaos, acting as the bridge between unprocessed data and actionable intelligence. You might even think of effective data transformation like a powerful magnet that draws the needle from the stack, leaving the hay behind.
This is part 2 in this blog series. You can read part 1, here: Digital Transformation is a Data Journey From Edge to Insight. The first blog introduced a mock connected vehicle manufacturing company, The Electric Car Company (ECC), to illustrate the manufacturing data path through the data lifecycle.
The missing chapter is not about point solutions or the maturity journey of use cases, the missing chapter is about the data, it’s always been about the data, and most importantly the journey data weaves from edge to artificial intelligence insight. . Conclusion.
In the second part, we will focus on architectural patterns to implement data quality from a data contract perspective. Why is Data Quality Expensive? I won’t bore you with the importance of data quality in the blog. Let’s talk about the dataprocessing types.
The blog posts How to Build and Deploy Scalable Machine Learning in Production with Apache Kafka and Using Apache Kafka to Drive Cutting-Edge Machine Learning describe the benefits of leveraging the Apache Kafka ® ecosystem as a central, scalable and mission-critical nervous system. For now, we’ll focus on Kafka.
Open Table Format (OTF) architecture now provides a solution for efficient data storage, management, and processing while ensuring compatibility across different platforms. In this blog, we will discuss: What is the Open Table format (OTF)? Why should we use it? A Brief History of OTF A comparative study between the major OTFs.
Data Collection/Ingestion The next component in the data pipeline is the ingestion layer, which is responsible for collecting and bringing data into the pipeline. By efficiently handling dataingestion, this component sets the stage for effective dataprocessing and analysis.
It calls out that Cloudera DataFlow “ includes streaming flow and streaming dataprocessing unified with Cloudera Data Platform ”. The post Cloudera named a Strong Performer in The Forrester Wave™: Streaming Analytics, Q2 2021 appeared first on Cloudera Blog.
While Cloudera Flow Management has been eagerly awaited by our Cloudera customers for use on their existing Cloudera platform clusters, Cloudera Edge Management has generated equal buzz across the industry for the possibilities that it brings to enterprises in their IoT initiatives around edge management and edge data collection.
Here’s what implementing an open data lakehouse with Cloudera delivers: Integration of Data Lake and Data Warehouse : An open data lakehouse brings together the best of both worlds by integrating the storage flexibility of a data lake with the query performance and structured querying capabilities of a data warehouse.
The Rise of Data Observability Data observability has become increasingly critical as companies seek greater visibility into their dataprocesses. This growing demand has found a natural synergy with the rise of the data lake.
Data integration and ingestion: With robust data integration capabilities, a modern data architecture makes real-time dataingestion from various sources—including structured, unstructured, and streaming data, as well as external data feeds—a reality.
He wrote some years ago 3 articles defining data engineering field. Some concepts When doing data engineering you can touch a lot of different concepts. The main difference between both is the fact that your computation resides in your warehouse with SQL rather than outside with a programming language loading data in memory.
In this blog post, we will discuss the AvroTensorDataset API, techniques we used to improve dataprocessing speeds by up to 162x over existing solutions (thereby decreasing overall training time by up to 66%), and performance results from benchmarks and production.
Here’s What You Need to Know About PySpark This blog will take you through the basics of PySpark, the PySpark architecture, and a few popular PySpark libraries , among other things. Finally, you'll find a list of PySpark projects to help you gain hands-on experience and land an ideal job in Data Science or Big Data.
Authors: Bingfeng Xia and Xinyu Liu Background At LinkedIn, Apache Beam plays a pivotal role in stream processing infrastructures that process over 4 trillion events daily through more than 3,000 pipelines across multiple production data centers.
The fact that ETL tools evolved to expose graphical interfaces seems like a detour in the history of dataprocessing, and would certainly make for an interesting blog post of its own. Sure, there’s a need to abstract the complexity of dataprocessing, computation and storage.
DataOps is a collaborative approach to data management that combines the agility of DevOps with the power of data analytics. It aims to streamline dataingestion, processing, and analytics by automating and integrating various data workflows.
In our previous blog post we introduced Edgar, our troubleshooting tool for streaming sessions. This flexibility allows tracer libraries to record 100% traces in our mission-critical streaming microservices while collecting minimal traces from auxiliary systems like offline batch dataprocessing.
DataOps , short for data operations, is an emerging discipline that focuses on improving the collaboration, integration, and automation of dataprocesses across an organization. Accelerated Data Analytics DataOps tools help automate and streamline various dataprocesses, leading to faster and more efficient data analytics.
Use cases like fraud detection, network threat analysis, manufacturing intelligence, commerce optimization, real-time offers, instantaneous loan approvals, and more are now possible by moving the dataprocessing components up the stream to address these real-time needs. . Faster dataingestion: streaming ingestion pipelines.
Azure Data Engineering is a rapidly growing field that involves designing, building, and maintaining dataprocessing systems using Microsoft Azure technologies. Contents: What is the role of an Azure Data Engineer? Azure data engineers are essential in the design, implementation, and upkeep of cloud-based data solutions.
The table below summarizes Hive and Druid key features and strengths and suggests how combining the feature sets can provide the best of both worlds for data analytics. Cloudera Data Warehouse). Efficient batch dataprocessing. Complex data transformations. Native streaming ingestion support from Kafka and Kinesis.
As Snowflake streams define an offset to track change data capture (CDC) changes on underlying tables and views, Tasks can be used to schedule the consumption of that data. We covered this in depth in a previous blog post. Today’s Snowflake Dynamic Tables do not support append-only dataprocessing.
Conversely, high latency can hinder your organization’s data integration and streaming efforts. As data-driven decision-making becomes increasingly vital, the importance of minimizing latency has never been clearer. The way that you can do so is by harnessing real-time dataprocessing over batch processing methodologies.
Since we announced the general availability of Apache Iceberg in Cloudera Data Platform (CDP), Cloudera customers, such as Teranet , have built open lakehouses to future-proof their data platforms for all their analytical workloads. Cloudera partners are also benefiting from Apache Iceberg in CDP. ORC open file format support.
In the early days, many companies simply used Apache Kafka ® for dataingestion into Hadoop or another data lake. ® , Go, and Python SDKs where an application can use SQL to query raw data coming from Kafka through an API (but that is a topic for another blog). However, Apache Kafka is more than just messaging.
The Five Use Cases in Data Observability: Mastering Data Production (#3) Introduction Managing the production phase of data analytics is a daunting challenge. Overseeing multi-tool, multi-dataset, and multi-hop dataprocesses ensures high-quality outputs.
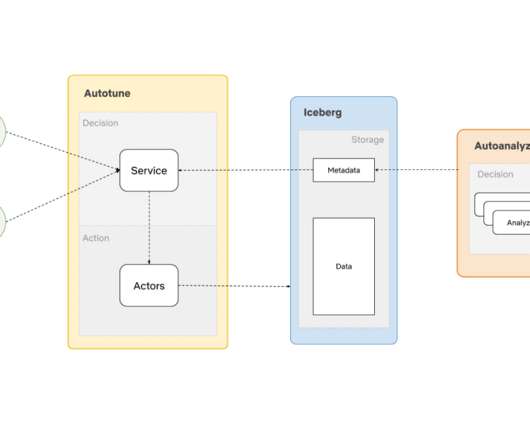
Merge As the data lands into the data warehouse through real-time dataingestion systems, it comes in different sizes. Merging those numerous smaller files into a handful of larger files can make query processing faster and reduce storage space. We will publish a follow-up blog post about AutoAnalyze in the future.
Data Engineering Weekly Is Brought to You by RudderStack RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. The blog narrates the key concepts of the Kimball model and a modern outlook on the concepts.
Most scenarios require a reliable, scalable, and secure end-to-end integration that enables bidirectional communication and dataprocessing in real time. MQTT Proxy for dataingestion without an MQTT broker. But that doesn’t move much.
[link] The short YouTube video gives a nice overview of the Data Cards. We often think of AI/ ML as a complex dataprocessing problem, but it doesn’t make any use until it is exposed to an end user or an application. The blog narrates one such application that uses video quality with neural networks.
Aim to automate processes: Automation is a key aspect of both DataOps and MLOps as it helps streamline workflows, reduce errors, increase efficiency, and ensure consistency across projects. Better data observability equals better data quality.
The AWS training will prepare you to become a master of the cloud, storing, processing, and developing applications for the cloud data. Amazon AWS Kinesis makes it possible to process and analyze data from multiple sources in real-time. What can I do with Kinesis Data Streams? How Amazon Kinesis Works?
The Challenge: High Stakes in the Age of Personalized Data Observability The primary challenge stems from the requirement of Data Consumers for personalized monitoring and alerts based on their unique dataprocessing needs. Data Observability platforms often need to deliver this level of customization.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content