This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
An end-to-end Data Science pipeline starts from business discussion to delivering the product to the customers. One of the key components of this pipeline is Dataingestion. It helps in integrating data from multiple sources such as IoT, SaaS, on-premises, etc., What is DataIngestion?
Though basic and easy to use, traditional table storage formats struggle to keep up. Open Table Format (OTF) architecture now provides a solution for efficient datastorage, management, and processing while ensuring compatibility across different platforms. In this blog, we will discuss: What is the Open Table format (OTF)?
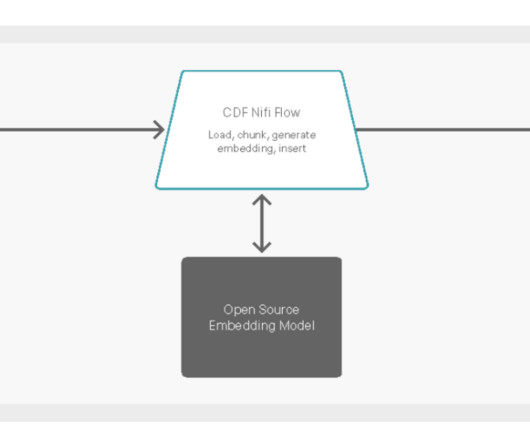
The connector makes it easy to update the LLM context by loading, chunking, generating embeddings, and inserting them into the Pinecone database as soon as new data is available. High-level overview of real-time dataingest with Cloudera DataFlow to Pinecone vector database.
This blog post explores how Snowflake can help with this challenge. Legacy SIEM cost factors to keep in mind Dataingestion: Traditional SIEMs often impose limits to dataingestion and data retention. Now there are a few ways to ingestdata into Snowflake.
Future connected vehicles will rely upon a complete data lifecycle approach to implement enterprise-level advanced analytics and machine learning enabling these advanced use cases that will ultimately lead to fully autonomous drive. This author is passionate about industry 4.0,
Data Collection/Ingestion The next component in the data pipeline is the ingestion layer, which is responsible for collecting and bringing data into the pipeline. By efficiently handling dataingestion, this component sets the stage for effective data processing and analysis.
formats — This is a huge part of data engineering. Picking the right format for your datastorage. The main difference between both is the fact that your computation resides in your warehouse with SQL rather than outside with a programming language loading data in memory. workflows (Airflow, Prefect, Dagster, etc.)
As data volumes grow and analytical needs evolve, organizations can seamlessly scale their infrastructure horizontally to accommodate increased dataingestion, processing, and storage demands. Learn more about the Cloudera Open Data Lakehouse here.
The organization was locked into a legacy data warehouse with high operational costs and inability to perform exploratory analytics. With more than 25TB of dataingested from over 200 different sources, Telkomsel recognized that to best serve its customers it had to get to grips with its data. .
In this particular blog post, we explain how Druid has been used at Lyft and what led us to adopt ClickHouse for our sub-second analytic system. Druid at Lyft Apache Druid is an in-memory, columnar, distributed, open-source data store designed for sub-second queries on real-time and historical data.
DataOps is a collaborative approach to data management that combines the agility of DevOps with the power of data analytics. It aims to streamline dataingestion, processing, and analytics by automating and integrating various data workflows. As a result, they can be slow, inefficient, and prone to errors.
Azure Data Engineering is a rapidly growing field that involves designing, building, and maintaining data processing systems using Microsoft Azure technologies. As a certified Azure Data Engineer, you have the skills and expertise to design, implement and manage complex datastorage and processing solutions on the Azure cloud platform.
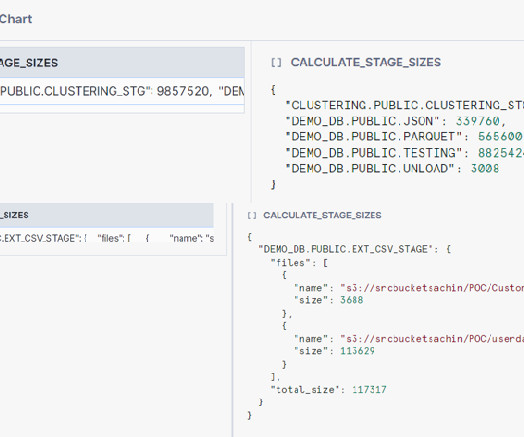
Read Time: 1 Minute, 39 Second Many organizations leverage Snowflake stages for temporary datastorage. However, with ongoing dataingestion and processing, it’s easy to lose track of stages containing old, potentially unnecessary data. This can lead to wasted storage costs.
In our previous blog post we introduced Edgar, our troubleshooting tool for streaming sessions. The data read queries took an increasingly longer time to finish because ElasticSearch clusters were using heavy compute resources for creating indexes on ingested traces. —?which is difficult when troubleshooting distributed systems.
For example, we are integrating architecture diagrams for active/passive, geographically dispersed disaster recovery cluster pairs like the following diagram, showing a common application zone and for dataingestion and analytics, and how replication moves through the system. Cloudera Data Platform. CDP Knowledge Hub.
In addition to simply consuming LLMs, our customers are also interested in fine-tuning pretrained LLMs, including models available with the NVIDIA NeMo framework and Meta’s Llama models , with their own corporate and Snowflake data.
Data Vault as a practice does not stipulate how you transform your data, only that you follow the same standards to populate business vault link and satellite tables as you would to populate raw vault link and satellite tables. Feature engineering: Data is transformed to support ML model training. ML workflow, ubr.to/3EJHjvm
From a data perspective, the World Cup represents an interesting source of information. The idea in this blog post is to mix information coming from two distinct channels: the RSS feeds of sport-related newspapers and Twitter feeds of the FIFA Women’s World Cup. Data sources. Ingesting Twitter data.
Application modernization initiatives have led to cloud native architectures gaining popularity on premises, making it a sensible choice to extend to your data platform. At its core, CDP Private Cloud Data Services (“the platform”) is an end-to-end cloud native platform that provides a private open data lakehouse.
With many data modeling methodologies and processes available, choosing the right approach can be daunting. This blog will guide you through the best data modeling methodologies and processes for your data lake, helping you make informed decisions and optimize your data management practices. What is a Data Lake?
It is meant for you to assess if you have thought through processes such as continuous dataingestion, enterprise data integration and data governance. Data infrastructure readiness – IoT architectures can be insanely complex and sophisticated. Get your free Expo Pass to IoT World and join us. See you there!
While this “data tsunami” may pose a new set of challenges, it also opens up opportunities for a wide variety of high value business intelligence (BI) and other analytics use cases that most companies are eager to deploy. . Traditional data warehouse vendors may have maturity in datastorage, modeling, and high-performance analysis.
Data observability works with your data pipeline by providing insights into how your data flows and is processed from start to end. Here is a more detailed explanation of how data observability works within the data pipeline: Dataingestion : Observability begins from the point where data is ingested into the pipeline.
The architecture is three layered: Database Storage: Snowflake has a mechanism to reorganize the data into its internal optimized, compressed and columnar format and stores this optimized data in cloud storage. The data objects are accessible only through SQL query operations run using Snowflake.
link] Meta: Tulip - Schematizing Meta’s data platform Numerous heterogeneous services make up a data platform, such as warehouse datastorage and various real-time systems. The schematization of data plays a vital role in a data platform. The author shares the experience of one such transition.
Managing cloud-based data services, cost optimization, and scaling are key responsibilities, and these trends are likely to grow along with the future of data governance. Data Pipeline Tools: Familiarity with tools such as Apache Kafka (mentioned in 71% of job postings) and Apache Spark (66%) is vital.
Managing cloud-based data services, cost optimization, and scaling are key responsibilities, and these trends are likely to grow along with the future of data governance. Data Pipeline Tools: Familiarity with tools such as Apache Kafka (mentioned in 71% of job postings) and Apache Spark (66%) is vital.
Two popular approaches that have emerged in recent years are data warehouse and big data. While both deal with large datasets, but when it comes to data warehouse vs big data, they have different focuses and offer distinct advantages. Analytics: Both data warehousing and big data platforms enable analytical capabilities.
In the previous blog posts in this series, we introduced the N etflix M edia D ata B ase ( NMDB ) and its salient “Media Document” data model. A fundamental requirement for any lasting data system is that it should scale along with the growth of the business applications it wishes to serve.
Forrester describes Big Data Fabric as, “A unified, trusted, and comprehensive view of business data produced by orchestrating data sources automatically, intelligently, and securely, then preparing and processing them in big data platforms such as Hadoop and Apache Spark, data lakes, in-memory, and NoSQL.”.
A growing number of companies now use this data to uncover meaningful insights and improve their decision-making, but they can’t store and process it by the means of traditional datastorage and processing units. Key Big Data characteristics. Big Data analytics processes and tools. Dataingestion.
However, going from data to the shape of a model in production can be challenging as it comprises data preprocessing, training, and deployment at a large scale. In this blog, you will learn what is AWS SageMaker, its Key features, and some of the most common actual use cases! Table of Content What is Amazon SageMaker?
It is widely used by data engineers for building scalable and reliable data processing systems. Hadoop provides tools for datastorage, processing, and analysis, including Hadoop Distributed File System (HDFS) and MapReduce. It can add more processing power and storage as the data grows.
This demonstrates the increasing need for Microsoft Certified Data Engineers. In this blog, I will explore Azure data engineer jobs and the top 10 job roles in this field where you can begin your career. They use many datastorage, computation, and analytics technologies to develop scalable and robust data pipelines.
By combining the power of the Snowflake Data Cloud with the ease of use of Django, developers can build sophisticated web applications that deliver powerful insights to end users. Read our announcement blog post for more. Offering data quality analysis based on solid math, CodeLine makes stats, predictions, and anomaly detection.
Do ETL and data integration activities seem complex to you? Read this blog to understand everything about AWS Glue that makes it one of the most popular data integration solutions in the industry. Did you know the global big data market will likely reach $268.4 Businesses are leveraging big data now more than ever.
If you're looking to break into the exciting field of big data or advance your big data career, being well-prepared for big data interview questions is essential. Get ready to expand your knowledge and take your big data career to the next level! But the concern is - how do you become a big data professional?
However, the benefits might be game-changing: a well-designed big data pipeline can significantly differentiate a company. In this blog, we’ll go over elements of big data , the big data environment as a whole, big data infrastructures, and some valuable tools for getting it all done.
Elasticsearch is one tool to which reads can be offloaded, and, because both MongoDB and Elasticsearch are NoSQL in nature and offer similar document structure and data types, Elasticsearch can be a popular choice for this purpose. This blog post will examine the various tools that can be used to sync data between MongoDB and Elasticsearch.
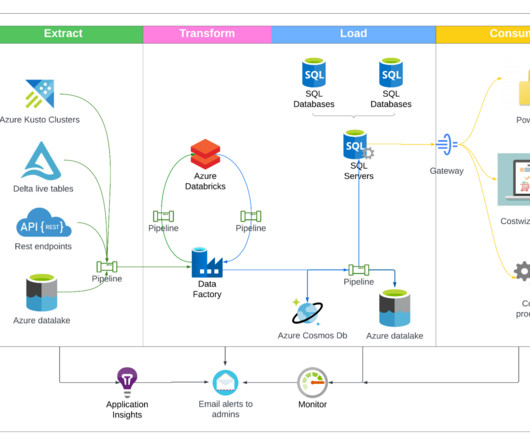
Costwiz provides a unified experience that helps leaders drive more accurate forecasting of Azure budgets at LinkedIn with resource ownership detection, accountability, expedited remedies, and holistic data visibility (via custom dashboards).
With so many data engineering certifications available , choosing the right one can be a daunting task. There are over 133K data engineer job openings in the US, but how will you stand out in such a crowded job market? Why Are Data Engineering Skills In Demand? Don’t worry!
Moreover, what benefits can you expect from a career in Azure Data Engineering? This blog aims to answer these questions, providing a straightforward and professional insight into the world of Azure Data Engineering. Join us on this journey through the exciting realm of Azure Data Engineering.
Table of Contents 20 Open Source Big Data Projects To Contribute How to Contribute to Open Source Big Data Projects? 20 Open Source Big Data Projects To Contribute There are thousands of open-source projects in action today. This blog will walk through the most popular and fascinating open source big data projects.
A brief history of datastorage The value of data has been apparent for as long as people have been writing things down. 100 zettabytes is 10 14 gigabytes, or 10 to 100 times more than the estimated number of stars in the Local Group of galaxies, which includes our Milky Way.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content