

Level Up Your Data Platform With Active Metadata
Data Engineering Podcast
JUNE 19, 2022
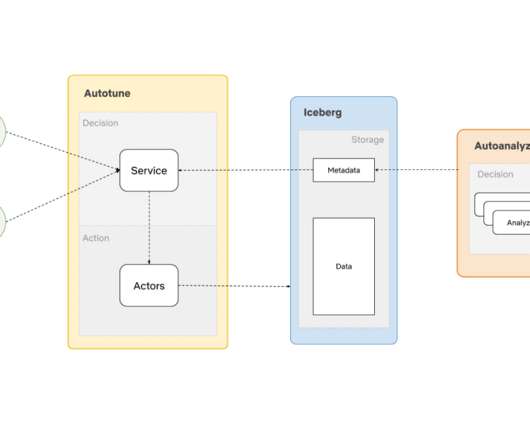
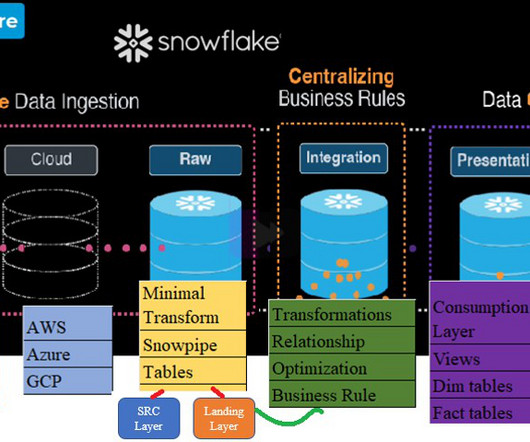
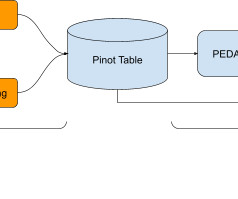
Summary Metadata is the lifeblood of your data platform, providing information about what is happening in your systems. In order to level up their value a new trend of active metadata is being implemented, allowing use cases like keeping BI reports up to date, auto-scaling your warehouses, and automated data governance.













































Let's personalize your content