This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To tackle these challenges, we’re thrilled to announce CDP Data Engineering (DE) , the only cloud-native service purpose-built for enterprise data engineering teams. Native Apache Airflow and robust APIs for orchestrating and automating job scheduling and delivering complex datapipelines anywhere.
With Astro, you can build, run, and observe your datapipelines in one place, ensuring your mission critical data is delivered on time. This blog captures the current state of Agent adoption, emerging software engineering roles, and the use case category.
The blog emphasizes the importance of starting with a clear client focus to avoid over-engineering and ensure user-centric development. link] Gunnar Morling: Revisiting the Outbox Pattern The blog is an excellent summary of the path we crossed with the outbox pattern and the challenges ahead.
After the launch of CDP Data Engineering (CDE) on AWS a few months ago, we are thrilled to announce that CDE, the only cloud-native service purpose built for enterprise data engineers, is now available on Microsoft Azure. . CDP data lifecycle integration and SDX security and governance. Key features of CDP Data Engineering.
When data reaches the Gold layer, it is highly curated and structured, offering a single version of the truth for decision-makers across the organization. We have also seen a fourth layer, the Platinum layer , in companies’ proposals that extend the Datapipeline to OneLake and Microsoft Fabric.
Snowflake is completely managed, but its main focus is on the data warehouse layer, and users need to integrate with other tools for BI, ML, or ETL. Ideal for: Business-centric workflows involving fabric Snowflake = environments with a lot of developers and data engineers 2.
However, that's also something we're re-thinking with our warehouse-centric strategy. How does reverse ETL factor into the enrichment process for profile data? Contact Info Kevin LinkedIn Blog Hanhan LinkedIn Parting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?
One paper suggests that there is a need for a re-orientation of the healthcare industry to be more "patient-centric". Furthermore, clean and accessible data, along with data driven automations, can assist medical professionals in taking this patient-centric approach by freeing them from some time-consuming processes.
NVidia released Eagle a vision-centric multimodal LLM — Look at the example in the Github repo, given an image and a user input the LLM is able to answer things like "Describe the image in detail" or "Which car in the picture is more aerodynamic" based on a drawing. How the UK football rely heavily on data?
This introductory blog focuses on an overview of our journey. Future blogs will provide deeper dives into each service, sharing insights and lessons learned from this process. Future blogs will provide deeper dives into each service, sharing insights and lessons learned from this process.
To enable LGIM to better utilize its wealth of data, LGIM required a centralized platform that made internal data discovery easy for all teams and could securely integrate external partners and third-party outsourced datapipelines. The post Cloudera Customer Story appeared first on Cloudera Blog.
To this end, UBL embarked on a data analytics project that would achieve its goals for an improved data environment. Next, it needed to enhance the company’s customer-centric approach for a needs-based alignment of products and services. Mr. Kashif Riaz, head of data and AI at UBL, shared his thoughts on this project. “To
Take Astro (the fully managed Airflow solution) for a test drive today and unlock a suite of features designed to simplify, optimize, and scale your datapipelines. Try For Free → Conference Alert: Data Engineering for AI/ML This is a virtual conference at the intersection of Data and AI.
Without DataOps, companies can employ hundreds of data professionals and still struggle. The datapipelines must contend with a high level of complexity – over seventy data sources and a variety of cadences, including daily/weekly updates and builds. That’s the power of DataOps automation. It’s that simple. .
Here is the agenda, 1) Data Application Lifecycle Management - Harish Kumar( Paypal) Hear from the team in PayPal on how they build the data product lifecycle management (DPLM) systems. 3) DataOPS at AstraZeneca The AstraZeneca team talks about data ops best practices internally established and what worked and what didn’t work!!!
Data Engineering is typically a software engineering role that focuses deeply on data – namely, data workflows, datapipelines, and the ETL (Extract, Transform, Load) process. What is the role of a Data Engineer? Data scientists and data Analysts depend on data engineers to build these datapipelines.
The word “data” is ubiquitous in narratives of the modern world. And data, the thing itself, is vital to the functioning of that world. This blog discusses quantifications, types, and implications of data. Quantifications of data. Addressing the challenges of data. Conclusions. Here we mention two.
Business users are unable to find and access data assets critical to their workflows. Data engineers spend countless hours troubleshooting broken pipelines. The data team is constantly burning out and has a high employee turnover. Stakeholders fail to see the ROI behind expensive data initiatives.
Treating data as a product is more than a concept; it’s a paradigm shift that can significantly elevate the value that business intelligence and data-centric decision-making have on the business. DatapipelinesData integrity Data lineage Data stewardship Data catalog Data product costing Let’s review each one in detail.
These limited-term databases can be generated as needed from automated recipes (orchestrated pipelines and qualification tests) stored and managed within the process hub. . The process hub capability of the DataKitchen Platform ensures that those processes that act upon data – the tests, the recipes – are shareable and manageable.
Data Engineering Weekly Is Brought to You by RudderStack RudderStack Profiles takes the SaaS guesswork, and SQL grunt work out of building complete customer profiles, so you can quickly ship actionable, enriched data to every downstream team. Similarly, the blog narrates how to use vector searching in Postgres using PGVector.
This helps to enhance data quality, facilitate data governance, and enable regulatory compliance. Notable Data Lineage Tools and Solutions Let’s take a look at several notable data lineage tools that can improve the quality and efficiency of your datapipeline.
Snowpark is our secure deployment and processing of non-SQL code, consisting of two layers: Familiar Client Side Libraries – Snowpark brings deeply integrated, DataFrame-style programming and OSS compatible APIs to the languages data practitioners like to use. Previously, tasks could be executed as quickly as 1-minute.
Data Engineering Weekly Is Brought to You by RudderStack RudderStack provides datapipelines that make collecting data from every application, website, and SaaS platform easy, then activating it in your warehouse and business tools. Sign up free to test out the tool today. I print this out and read it a couple of times.
But perhaps one of the most common reasons for data quality challenges are software feature updates and other changes made upstream by software engineers. These are particularly frustrating, because while they are breaking datapipelines constantly, it’s not their fault. He suggested : “Private vs. public methods.
As a result, a less senior team member was made responsible for modifying a production pipeline. When you architect for flexibility, quality, rapid deployment, and real-time data monitoring (in addition to your customer requirements), you move towards a DataOps-centricdata engineering practice.
He is also an open-source developer at The Apache Software Foundation and the author of Hysterical , a popular blog on tech careers and topics like data, coding, and engineering. Through these roles, he has developed a passion for using data and common sense to generate simple, implementable solutions to complex problems.
Owing to the vitality of application software, businesses are actively seeking professionals with excellent technical expertise and a consumer-centric mindset to develop more practical application software systems that enhance customer experience. This blog has explored its utility, types, and impact on businesses and organizations.
Slow Response to New Information: Legacy data systems often lack the computation power necessary to run efficiently and can be cost-inefficient to scale. This typically results in long-running ETL pipelines that cause decisions to be made on stale or old data.
Here if there arises a need to modify the datapipeline , nothing but the data flow from the source to the stage, there is the capability of monitoring the flow processes and other data hold through the governance systems. post which is the ML model trainings.
As advanced analytics and AI continue to drive enterprise strategy, leaders are tasked with building flexible, resilient datapipelines that accelerate trusted insights. A New Level of Productivity with Remote Access The new Cloudera Data Engineering 1.23 Jupyter, PyCharm, and VS Code).
The article discusses common pitfalls such as absence bias and intervention bias while advocating for a user-centric approach that emphasizes evaluating retrieval accuracy through precision and recall, focusing on recall. Furthermore, the article highlights Glovo's evolution towards a declarative approach to defining data products.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










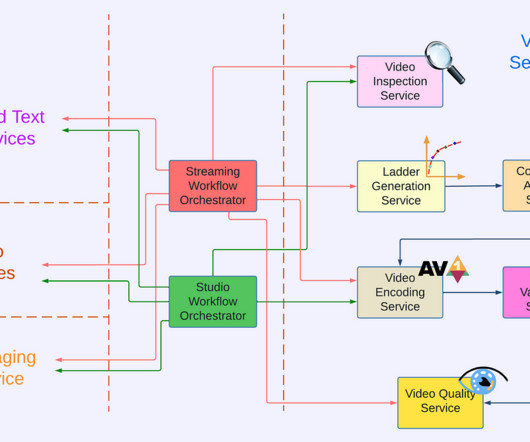







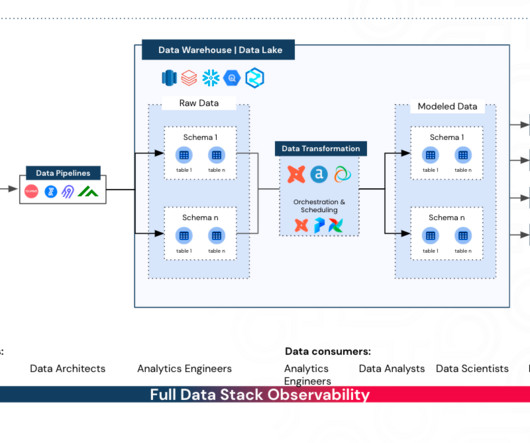



















Let's personalize your content