This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
introduces new features specifically designed to fuel GenAI initiatives: New AI Processors: Harness the power of cutting-edge AI models with new processors that simplify integration and streamline datapreparation for GenAI applications. and discover how it can transform your data pipelines, watch this video.
Businesses need to understand the trends in datapreparation to adapt and succeed. If you input poor-quality data into an AI system, the results will be poor. This principle highlights the need for careful datapreparation, ensuring that the input data is accurate, consistent, and relevant.
Snowflakes Snowpark is a game-changing feature that enables data engineers and analysts to write scalable data transformation workflows directly within Snowflake using Python, Java, or Scala. SILVER Layer : Cleansed and enriched dataprepared for analytical processing.
DataOps involves close collaboration between data scientists, IT professionals, and business stakeholders, and it often involves the use of automation and other technologies to streamline data-related tasks. One of the key benefits of DataOps is the ability to accelerate the development and deployment of data-driven solutions.
This blog post describes the advantages of real-time ETL and how it increases the value gained from Snowflake implementations. With instant elasticity, high-performance, and secure data sharing across multiple clouds , Snowflake has become highly in-demand for its cloud-based data warehouse offering.
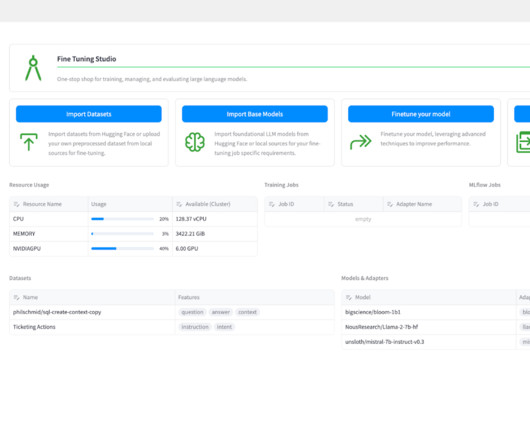
DataPreparation. The post Introducing Cloudera Fine Tuning Studio for Training, Evaluating, and Deploying LLMs with Cloudera AI appeared first on Cloudera Blog.
In this blog post, we will show how Snowflake’s integrated functionality simplifies building and deploying RAG-based applications. Preparing documents for a RAG system The responses of an LLM in a RAG app are only as good as the data available to it, which is why proper datapreparation is fundamental to building a high-performing RAG system.
In The Land Of The Blind, The Data Engineer Who Has Data Quality Testing In Production Is King Data engineers experience burnout at alarming rates , with many considering leaving the industry or their current company within the following year.
In this first Google Cloud release, CDP Public Cloud provides built-in Data Hub definitions (see screenshot for more details) for: Data Ingestion (Apache NiFi, Apache Kafka). DataPreparation (Apache Spark and Apache Hive) . You can get started with CDP Public Cloud by requesting a trial account here. .
This blog shows how text data representations can be used to build a classifier to predict a developer’s deep learning framework of choice based on the code that they wrote, via examples of TensorFlow and PyTorch projects.
Data science project cycle is composed of six phases: Business understanding Data understanding Datapreparation Modelling Evaluation Deployment This is the greater abstraction level of the Crisp-DM methodology, meaning one that can apply, with no exception, to all data problems.
A 2016 data science report from data enrichment platform CrowdFlower found that data scientists spend around 80% of their time in datapreparation (collecting, cleaning, and organizing of data) before they can even begin to build machine learning (ML) models to deliver business value.
Containerized service to run both multiple compute clusters against the same data, and to configure each cluster with its own unique characteristics (instance types, initial and growth sizing parameters, and workload aware auto scaling capabilities). appeared first on Cloudera Blog. The post Don’t Blink: You’ll Miss Something Amazing!
UDD works on any source and destination, even outside of Cloudera, making it very easy to integrate varied data sources. Only Cloudera includes integrated capabilities for the entire data lifecycle; datapreparation to advanced analytics; and has automation built into all our data services.
Currently the loss weight for each task is equal, but during the datapreparation stage, we apply various weight adjustments so that each training example is properly represented in the loss function. The loss function is captured below, where b = (1, … B) from B examples in the batch, and h = (1, … H) from H tasks.
While it’s important to have the in-house data science expertise and the ML experts on-hand to build and test models, the reality is that the actual data science work — and the machine learning models themselves — are only one part of the broader enterprise machine learning puzzle.
It involves many moving parts, from datapreparation to building indexing and query pipelines. Luckily, this task looks a lot like the way we tackle problems that arise when connecting data. Moving data into Apache Kafka with the JDBC connector. Building a resilient and scalable solution is not always easy.
It’s been around since 2017, and we don’t intend to go into a full review of its features here—only a month ago, Mike Morgan and Steve Conway from our Leeds office published a comparative review of three cloud BI solutions, including QuickSight here on the Scott Logic blog. Have Amazon succeeded?
CPUs and GPUs can be used in tandem for data engineering and data science workloads. A typical machine learning workflow involves datapreparation, model training, model scoring, and model fitting. To overcome this, practitioners often turn to NVIDIA GPUs to accelerate machine learning and deep learning workloads. .
Cloudera provides end-to-end data life cycle management on a hybrid data platform, which includes all the building blocks needed to build a data strategy for trusted data in manufacturing. The post Achieving Trusted AI in Manufacturing appeared first on Cloudera Blog.
Data testing tools: Key capabilities you should know Helen Soloveichik August 30, 2023 Data testing tools are software applications designed to assist data engineers and other professionals in validating, analyzing and maintaining data quality. There are several types of data testing tools.
. ” In the continuously evolving field of data-driven insights, maintaining competitiveness relies not only on in-depth analysis but also on the rapid and precise development of reports. Power BI, Microsoft's cutting-edge business analytics solution, empowers users to visualize data and seamlessly distribute insights.
In this blog, we’ll explain why you should prepare your data before use in machine learning , how to clean and preprocess the data, and a few tips and tricks about datapreparation. Why PrepareData for Machine Learning Models? It may hurt it by adding in irrelevant, noisy data.
There are two main steps for preparingdata for the machine to understand. Any ML project starts with datapreparation. People are doing NLP projects all the time and they’re publishing their results in papers and blogs. These won’t be the texts as we see them, of course. Text annotation and formatting.
However, going from data to the shape of a model in production can be challenging as it comprises data preprocessing, training, and deployment at a large scale. In this blog, you will learn what is AWS SageMaker, its Key features, and some of the most common actual use cases! Table of Content What is Amazon SageMaker?
Make Trusted Data Products with Reusable Modules : “Many organizations are operating monolithic data systems and processes that massively slow their data delivery time.”
For instance, telcos are early adopters of location intelligence – spatial analytics has been helping telecommunications firms by adding rich location-based context to their existing data sets for years. All that time spent on datapreparation has an opportunity cost associated with it.
To answer the three fundamental questions outlined above, telecoms rely on business-friendly GIS to create a single view of the network that’s accessible, easily understood, and trusted by internal stakeholders to drive better, data-informed decisions. They also need a strong foundation of data science to underpin those efforts.
Otherwise, let’s proceed to the first and most fundamental step in building AI-fueled computer vision tools — datapreparation. Computer vision requires plenty of quality data, diverse in gender, race, and geography. Source: AWS Machine Learning Blog. Source: Google AI Blog. A common DICOM file contains.
In this blog, I will describe the role of a Machine Learning Software Engineer, their responsibilities, required skills, and the path to becoming one. DataPreparation: The Machine Learning Engineer Software engineers get, clean, and process data so that it can be used in machine learning models.
Data testing tools are software applications designed to assist data engineers and other professionals in validating, analyzing, and maintaining data quality. There are several types of data testing tools. In this article: Why Are Data Testing Tools Important?
The post Azure Marketplace features Cloudera Customer 360 offering appeared first on Cloudera Blog. A recently-launched solution serves as an example of the power of partnerships. Learn more about Customer 360 Powered by Zero2Hero by visiting the Azure Marketplace , or the Cloudera Solutions Gallery.
It doesn't matter if you're a data expert or just starting out; knowing how to clean your data is a must-have skill. The future is all about big data. This blog is here to help you understand not only the basics but also the cool new ways and tools to make your data squeaky clean.
Aspire , built by Search Technologies , part of Accenture is a search engine independent content processing framework for handling unstructured data. It provides a powerful solution for datapreparation and publishing human-generated content to search engines and big data applications.
In this blog, we provide a few examples that show how organizations put deep learning to work. Next, we introduce you to Cloudera’s unified platform for data and machine learning and show you four ways to implement deep learning. Move forward with Cloudera, the unified platform for data and machine learning.
According to DataKitchen’s 2024 market research, conducted with over three dozen data quality leaders, the complexity of data quality problems stems from the diverse nature of data sources, the increasing scale of data, and the fragmented nature of data systems.
As every company becomes a data company, and more users within these companies are discovering new uses for previously unavailable data, existing infrastructure and tools are not just meeting that demand but creating new demands. At the center of it all is the data warehouse, the lynchpin of any modern data stack.
Data-driven Marketing Agency A data-driven marketing agency would use data to understand which marketing campaigns are most likely to be effective and then create and implement a marketing strategy that is customized to the client's needs.
Azure Synapse Analytics Pipelines: Azure Synapse Analytics (formerly SQL Data Warehouse) provides data exploration, datapreparation, data management, and data warehousing capabilities. It provides data prep, management, and enterprise data warehousing tools. It does the job.
Rockset indexes the entire data stream so when new fields are added, they are immediately exposed and made queryable using SQL. We’ve also enabled the ingest of historical and real-time streams so that customers can access a 360 view of their data, a common real-time analytics use case.
At Picnic, we understand the importance of efficient and accurate customer service, which is why we’ve turned to natural language processing techniques to automate the classification of customer feedback as you can read in this and this blog post.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content