This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
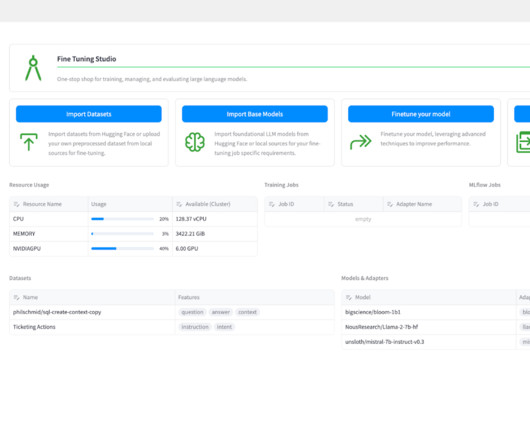
Fine Tuning Studio enables users to track the location of all datasets, models, and model adapters for training and evaluation. DataPreparation. We can import this dataset on the Import Datasets page. Let’s name our prompt better-ticketing and use our bitext dataset as the base dataset for the prompt.
Level 2: Understanding your dataset To find connected insights in your business data, you need to first understand what data is contained in the dataset. This is often a challenge for business users who arent familiar with the source data. Thats where ThoughtSpots architecture comes in.
Snowflakes Snowpark is a game-changing feature that enables data engineers and analysts to write scalable data transformation workflows directly within Snowflake using Python, Java, or Scala. SILVER Layer : Cleansed and enriched dataprepared for analytical processing. Built clean, enriched datasets in the SILVER layer.
Businesses need to understand the trends in datapreparation to adapt and succeed. If you input poor-quality data into an AI system, the results will be poor. This principle highlights the need for careful datapreparation, ensuring that the input data is accurate, consistent, and relevant.
An open-source AI-driven data quality testing that learns from your data automatically while providing a simple UI, not a code-specific DSL, to review, improve, and manage your data quality test estatea Test Generator. The Challenge of Writing Manual Data Quality Testing Organizations often have hundreds or thousands of tables.
Then, based on this information from the sample, defect or abnormality the rate for whole dataset is considered. This process of inferring the information from sample data is known as ‘inferential statistics.’ A database is a structured data collection that is stored and accessed electronically.
DataOps involves close collaboration between data scientists, IT professionals, and business stakeholders, and it often involves the use of automation and other technologies to streamline data-related tasks. One of the key benefits of DataOps is the ability to accelerate the development and deployment of data-driven solutions.
The platform converges data cataloging, data ingestion, data profiling, data tagging, data discovery, and data exploration into a unified platform, driven by metadata. Modak Nabu automates repetitive tasks in the datapreparation process and thus accelerates the datapreparation by 4x.
There are two main steps for preparingdata for the machine to understand. Any ML project starts with datapreparation. You can’t simply feed the system your whole dataset of emails and expect it to understand what you want from it. What should it be like and how to prepare a great one?
GitHub Copilot Features AI-Powered Coding Assistant : Trained on a massive dataset of publicly available code, including GitHub repositories, it can generate functions, classes, and entire code blocks. Data Project Assistance : Helps streamline tasks in data-driven projects, including datapreparation, analysis, and visual output.
This blog post delves into the AutoML framework for LinkedIn’s content abuse detection platform and its role in improving and fortifying content moderation systems at LinkedIn. It enables models to stay updated by automatically retraining on incrementally larger and more recent data with a pre-defined periodicity.
. ” In the continuously evolving field of data-driven insights, maintaining competitiveness relies not only on in-depth analysis but also on the rapid and precise development of reports. Power BI, Microsoft's cutting-edge business analytics solution, empowers users to visualize data and seamlessly distribute insights.
While it’s important to have the in-house data science expertise and the ML experts on-hand to build and test models, the reality is that the actual data science work — and the machine learning models themselves — are only one part of the broader enterprise machine learning puzzle. Laurence Goasduff, Gartner.
Data testing tools: Key capabilities you should know Helen Soloveichik August 30, 2023 Data testing tools are software applications designed to assist data engineers and other professionals in validating, analyzing and maintaining data quality. There are several types of data testing tools.
In this blog, we’ll explain why you should prepare your data before use in machine learning , how to clean and preprocess the data, and a few tips and tricks about datapreparation. Why PrepareData for Machine Learning Models? It may hurt it by adding in irrelevant, noisy data.
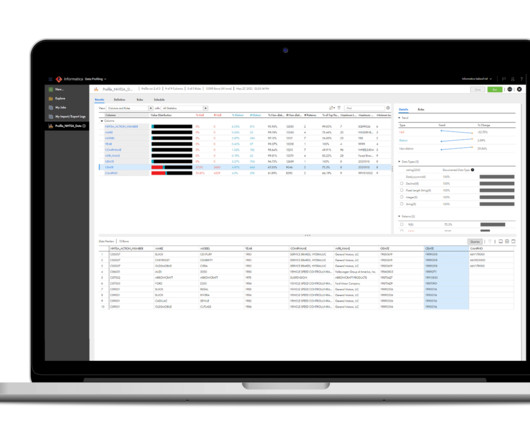
Data testing tools are software applications designed to assist data engineers and other professionals in validating, analyzing, and maintaining data quality. There are several types of data testing tools. Data profiling tools: Profiling plays a crucial role in understanding your dataset’s structure and content.
It doesn't matter if you're a data expert or just starting out; knowing how to clean your data is a must-have skill. The future is all about big data. This blog is here to help you understand not only the basics but also the cool new ways and tools to make your data squeaky clean. What is Data Cleaning?
Advanced Data Cleaning and Transformation : Scenario : A financial institution needs to clean and preprocess large datasets with complex transformations. Solution : Utilize Python’s Pandas library to perform data wrangling tasks such as handling missing values, merging datasets, and applying complex transformations.
Do ETL and data integration activities seem complex to you? Read this blog to understand everything about AWS Glue that makes it one of the most popular data integration solutions in the industry. Did you know the global big data market will likely reach $268.4 Businesses are leveraging big data now more than ever.
If you are an expert in working with data or a beginner excited to use visualization, this blog will help you understand the differences between power bi and tableau. Tableau, on the other hand, stands out for its exceptional speed, ensuring swift rendering even when dealing with large and complex datasets.
This blog post will delve into the challenges, approaches, and algorithms involved in hotel price prediction. For machine learning algorithms to predict prices accurately, people who do the datapreparation must consider these factors and gather all this information to train the model. Data relevance. Public datasets.
They also need a strong foundation of data science to underpin those efforts. Many organizations get bogged down with datapreparation, which can consume up to 80% of data science efforts. Collecting, organizing, and cleaning datasets consumes 45-60% of DS time.
As you now know the key characteristics, it gets clear that not all data can be referred to as Big Data. What is Big Data analytics? Big Data analytics is the process of finding patterns, trends, and relationships in massive datasets that can’t be discovered with traditional data management techniques and tools.
I was looking for some broken code to add a workshop to our Spark Performance Tuning class and write a blog post about, and this fitted the bill perfectly. For convenience purposes I chose to limit the scope of this exercise to a specific function that prepares the data prior to the churn analysis. distinct().collect()
However, collecting and annotating large amounts of data might not always be possible, and it is also expensive and time-consuming. Bid goodbye to worries related to such problems with this blog, as it covers an appropriate and effective solution to the problem of limited data available for training machine learning and deep learning models.
In this blog, I will describe the role of a Machine Learning Software Engineer, their responsibilities, required skills, and the path to becoming one. DataPreparation: The Machine Learning Engineer Software engineers get, clean, and process data so that it can be used in machine learning models.
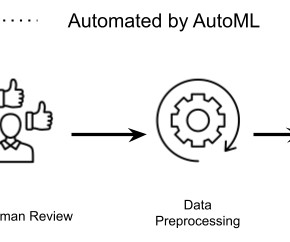
Namely, AutoML takes care of routine operations within datapreparation, feature extraction, model optimization during the training process, and model selection. In the meantime, we’ll focus on AutoML which drives a considerable part of the MLOps cycle, from datapreparation to model validation and getting it ready for deployment.
However, going from data to the shape of a model in production can be challenging as it comprises data preprocessing, training, and deployment at a large scale. In this blog, you will learn what is AWS SageMaker, its Key features, and some of the most common actual use cases! Table of Content What is Amazon SageMaker?
If you're looking to break into the exciting field of big data or advance your big data career, being well-prepared for big data interview questions is essential. Get ready to expand your knowledge and take your big data career to the next level! But the concern is - how do you become a big data professional?
Over the years, the field of data engineering has seen significant changes and paradigm shifts driven by the phenomenal growth of data and by major technological advances such as cloud computing, data lakes, distributed computing, containerization, serverless computing, machine learning, graph database, etc.
Data professionals who work with raw data like data engineers, data analysts, machine learning scientists , and machine learning engineers also play a crucial role in any data science project. And, out of these professions, this blog will discuss the data engineering job role.
In this blog, we provide a few examples that show how organizations put deep learning to work. Next, we introduce you to Cloudera’s unified platform for data and machine learning and show you four ways to implement deep learning. Move forward with Cloudera, the unified platform for data and machine learning.
Rockset indexes the entire data stream so when new fields are added, they are immediately exposed and made queryable using SQL. We’ve also enabled the ingest of historical and real-time streams so that customers can access a 360 view of their data, a common real-time analytics use case.
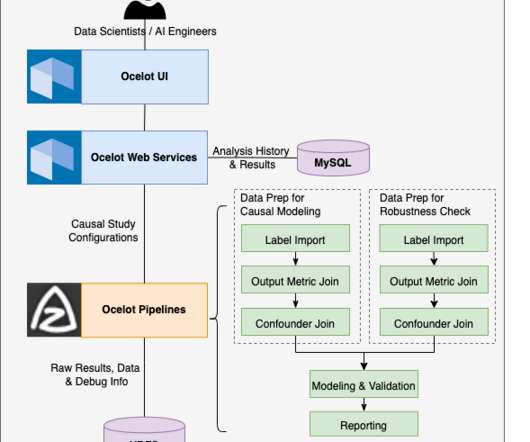
In this blog post, we share more details on how LinkedIn performs observational causal inference at scale using our Ocelot platform. We chose to bundle the functionality of datapreparation with the causal modeling for the following reasons.�� We fine tuned Spark jobs to reduce the datapreparation time and failure rate.
At Picnic, we understand the importance of efficient and accurate customer service, which is why we’ve turned to natural language processing techniques to automate the classification of customer feedback as you can read in this and this blog post. This is why we conclude that further improvements are likely possible.
Amazon Quicksight is a business intelligence service designed for cloud-based businesses to connect data from different sources for quick decision-making using a single dashboard. In this blog, let’s explore What AWS Quicksight is and how it disrupts data visualization workflows. Table of Content What is Amazon Quicksight?
While this blog post won’t dive deeply into Kinesis’ capabilities, it’s worth quickly noting three: Kinesis Data Streams enable continuous capture of gigabytes of data per second from an enormous number of sources. Rockset You didn’t think you’d finish a Rockset blog post without hearing about Rockset, did you?
Snowpark is our secure deployment and processing of non-SQL code, consisting of two layers: Familiar Client Side Libraries – Snowpark brings deeply integrated, DataFrame-style programming and OSS compatible APIs to the languages data practitioners like to use.
Planning to land a successful job as an Azure Data Engineer? Read this blog till the end to learn more about the roles and responsibilities, necessary skillsets, average salaries, and various important certifications that will help you build a successful career as an Azure Data Engineer. The final step is to publish your work.
However, the benefits might be game-changing: a well-designed big data pipeline can significantly differentiate a company. In this blog, we’ll go over elements of big data , the big data environment as a whole, big data infrastructures, and some valuable tools for getting it all done.
Table of Contents 20 Open Source Big Data Projects To Contribute How to Contribute to Open Source Big Data Projects? 20 Open Source Big Data Projects To Contribute There are thousands of open-source projects in action today. This blog will walk through the most popular and fascinating open source big data projects.
In this blog, I'll define the AI project life cycle and walk you through the steps, tools, and significance of the AI model lifecycle management process. This includes configuring hyperparameters, training the model on the training data, and fine-tuning it. They provide functions for cleaning, transforming, and analyzing data.
In the world of machine learning , there’s a well-known saying, “An ML model is only as good as the training data you feed it with.” It points out the critical role that data quality plays in the outcomes you get from these algorithms. Watch our video about datapreparation for ML tasks to learn more about this.
Launched in 2014, Snowflake is one of the most popular cloud data solutions on the market. This blog walks you through what does Snowflake do , the various features it offers, the Snowflake architecture, and so much more. Table of Contents Snowflake Overview and Architecture What is Snowflake Data Warehouse?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content