This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Batch dataprocessing — historically known as ETL — is extremely challenging. In this post, we’ll explore how applying the functional programming paradigm to data engineering can bring a lot of clarity to the process. Late arriving facts Late arriving facts can be problematic with a strict immutable data policy.
Since it takes so long to iterate on workflows, some ML engineers started to perform dataprocessing directly inside training jobs. This is what we commonly refer to as Last Mile DataProcessing. Last Mile processing can boost ML engineers’ velocity as they can write code in Python, directly using PyTorch.
A collaborative and interactive workspace allows users to perform big dataprocessing and machine learning tasks easily. In this blog post, we will take a closer look at Azure Databricks, its key features, […] The post Azure Databricks: A Comprehensive Guide appeared first on Analytics Vidhya.
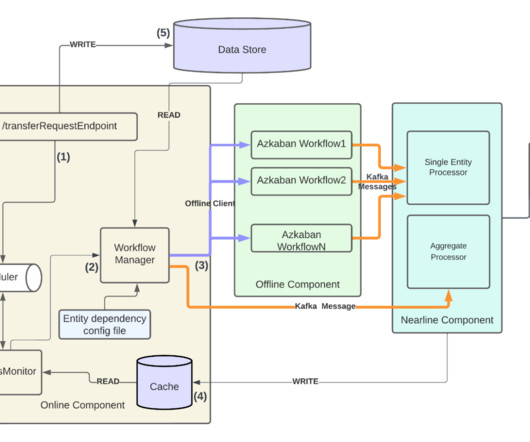
By Abhinaya Shetty , Bharath Mummadisetty In the inaugural blog post of this series, we introduced you to the state of our pipelines before Psyberg and the challenges with incremental processing that led us to create the Psyberg framework within Netflix’s Membership and Finance data engineering team.
The typical pharmaceutical organization faces many challenges which slow down the data team: Raw, barely integrated data sets require engineers to perform manual , repetitive, error-prone work to create analyst-ready data sets. Cloud computing has made it much easier to integrate data sets, but that’s only the beginning.
Data consistency, feature reliability, processing scalability, and end-to-end observability are key drivers to ensuring business as usual (zero disruptions) and a cohesive customer experience. With our new dataprocessing framework, we were able to observe a multitude of benefits, including 99.9%
StreamNative, a leading Apache Pulsar-based real-time data platform solutions provider, and Databricks, the Data Intelligence Platform, are thrilled to announce the enhanced Pulsar-Spark.
This belief has led us to developing Privacy Aware Infrastructure (PAI) , which offers efficient and reliable first-class privacy constructs embedded in Meta infrastructure to address different privacy requirements, such as purpose limitation , which restricts the purposes for which data can be processed and used.
The blog is an excellent summary of the existing unstructured data landscape. The learning mostly involves understanding the data's nature, frequency of dataprocessing, and awareness of the computing cost. It is exciting to read probably the first blog on building a vector search infrastructure at scale.
Data engineering can help with it. It is the force behind seamless data flow, enabling everything from AI-driven automation to real-time analytics. To stay competitive, businesses need to adapt to new trends and find new ways to deal with ongoing problems by taking advantage of new possibilities in data engineering.
Discover the insights he gained from academia and industry, his perspective on the future of dataprocessing and the story behind building a next-generation graph database. Semih explains how Kuzu addresses the challenges of large graph analytics, the benefits of embeddability, and its potential for applications in AI and beyond.
The blog took out the last edition’s recommendation on AI and summarized the current state of AI adoption in enterprises. The simplistic model expressed in the blog made it easy for me to reason about the transactional system design. Kafka is probably the most reliable data infrastructure in the modern data era.
I found the blog to be a fresh take on the skill in demand by layoff datasets. DeepSeek’s smallpond Takes on Big Data. DeepSeek continues to impact the Data and AI landscape with its recent open-source tools, such as Fire-Flyer File System (3FS) and smallpond. link] Mehdio: DuckDB goes distributed?
[link] QuantumBlack: Solving data quality for gen AI applications Unstructured dataprocessing is a top priority for enterprises that want to harness the power of GenAI. It brings challenges in dataprocessing and quality, but what data quality means in unstructured data is a top question for every organization.
For A Quick Recap You can find the first blog post here, where I learned which tech is most in demand in Toronto: [link] And the second blog post is here where I learn which Toronto industries need data engineers the most: [link] The Pipeline Proposal I'll be creating several pipelines in this project, but first things first; I need to ingest the data, (..)
I like writing code and each time there is a dataprocessing job to write with some business logic I'm very happy. Mack library, the topic of this blog post, is one of those projects discovered recently. However, with time I've learned to appreciate the Open Source contributions enhancing my daily work.
“Big data Analytics” is a phrase that was coined to refer to amounts of datasets that are so large traditional dataprocessing software simply can’t manage them. For example, big data is used to pick out trends in economics, and those trends and patterns are used to predict what will happen in the future.
However, it's not the single Python-based framework for distributed dataprocessing and people talk more and more often about the alternatives like Dask or Ray. Since both are completely new for me, I'm going to use this blog post to shed some light on them, and why not plan a deeper exploration next year?
However, implementing AI models requires significant computing power and real-time dataprocessing, which cannot be achieved without modern, scalable data platforms. The post Telco Enterprise Data Platforms: Key Success Factors in Building for an AI Future appeared first on Cloudera Blog.
Liang Mou; Staff Software Engineer, Logging Platform | Elizabeth (Vi) Nguyen; Software Engineer I, Logging Platform | In today’s data-driven world, businesses need to process and analyze data in real-time to make informed decisions. What is Change Data Capture? Why is CDC Important? or its affiliates.
Why Future-Proofing Your Data Pipelines Matters Data has become the backbone of decision-making in businesses across the globe. The ability to harness and analyze data effectively can make or break a company’s competitive edge. In this blog post, we’ll explore key strategies for future-proofing your data pipelines.
It discusses dataset considerations (relevance, annotation quality, size, ethics, data cutoffs, modalities, synthetic data), formats for instruction and preference tuning, synthetic data creation (Self-Instruct), data labeling approaches (human, LLM-assisted, cohort-based, RLHF-based), and dataprocessing architectures using Amazon Web Services.
These scalable models can handle millions of records, enabling you to efficiently build high-performing NLP data pipelines. However, scaling LLM dataprocessing to millions of records can pose data transfer and orchestration challenges, easily addressed by the user-friendly SQL functions in Snowflake Cortex.
This is part 2 in this blog series. You can read part 1, here: Digital Transformation is a Data Journey From Edge to Insight. The first blog introduced a mock connected vehicle manufacturing company, The Electric Car Company (ECC), to illustrate the manufacturing data path through the data lifecycle.
Read Time: 6 Minute, 6 Second In modern data pipelines, handling data in various formats such as CSV, Parquet, and JSON is essential to ensure smooth dataprocessing. However, one of the most common challenges faced by data engineers is the evolution of schemas as new data comes in.
However, due to the absence of a control group in these countries, we adopt a synthetic control framework ( blog post ) to estimate the counterfactual scenario. With some additional dataprocessing, this yields an expected percent of cash spend each day leading up to and beyond the launch date, which we can base our forecasts on.
link] Netflix: A Recap of the Data Engineering Open Forum at Netflix Netflix publishes a recap of all the talks in the first Data Engineering open forum tech meetups. The blog contains a summary of each talk and a link to the YouTube channel with all the talks. Are there enough usecases?
Automation, AI, DataOps, and strategic alignment are no longer optional —they are essential components of a successful data strategy. As we look towards 2025, it’s clear that data teams must evolve to meet the demands of evolving technology and opportunities. How effective are your current data workflows?
Data transformation helps make sense of the chaos, acting as the bridge between unprocessed data and actionable intelligence. You might even think of effective data transformation like a powerful magnet that draws the needle from the stack, leaving the hay behind.
This blog post describes the advantages of real-time ETL and how it increases the value gained from Snowflake implementations. With instant elasticity, high-performance, and secure data sharing across multiple clouds , Snowflake has become highly in-demand for its cloud-based data warehouse offering.
This blog captures the current state of Agent adoption, emerging software engineering roles, and the use case category. Generative AI demands the processing of vast amounts of diverse, unstructured data (e.g., meeting recordings and videos), which contrasts with traditional SQL-centric systems for structured data.
Balancing correctness, latency, and cost in unbounded dataprocessing Image created by the author. Intro Google Dataflow is a fully managed dataprocessing service that provides serverless unified stream and batch dataprocessing. Apache Beam lets users define processing logic based on the Dataflow model.
As you’ll see in this blog, NiFi is not only keeping up with Storm; it beats Storm by 4x throughput. . Because, they’ll be able to store massive amounts of data, process this data in real-time or batch, and serve the data to other applications. They asked, “Can NiFi keep up with the same throughput as Storm?”
This is super interesting because it details important steps of the generative process. This blog shows how you can use Gen AI to evaluate inputs like translations with added reasons. How we build Slack AI to be secure and private — How Slack uses VPC and Amazon SageMaker with your data secured and private.
[link] Discord: How Discord Uses Open-Source Tools for Scalable Data Orchestration & Transformation Discord writes about its migration journey from a homegrown orchestration engine to Dagster. Streaming execution to process a small chunk of data at a time. Intermediate spilling to disk while computing aggregations.
In the second part, we will focus on architectural patterns to implement data quality from a data contract perspective. Why is Data Quality Expensive? I won’t bore you with the importance of data quality in the blog. Let’s talk about the dataprocessing types. Should We Build a New Tool?
[link] Georg Heiler: Upskilling data engineers What should I prefer for 2028, or how can I break into data engineering? I honestly don’t have a solid answer, but this blog is an excellent overview of upskilling. These are common LinkedIn requests.
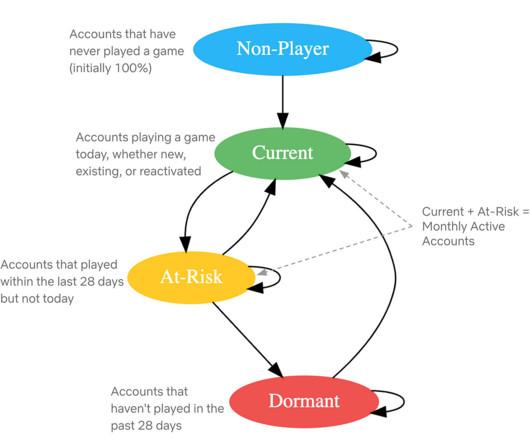
It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure. This nuanced integration of data and technology empowers us to offer bespoke content recommendations.
Check out this blog. Snowpark Container Services gives developers the ability to bring any containerized workload to their data that is already secure in Snowflake — ReactJS front-ends, open source large language models (LLMs), distributed dataprocessing pipelines, you name it. First, security.
While Apache NiFi is used successfully by hundreds of our customers to power mission critical and large-scale data flows, the expectations for enterprise data flow solutions are constantly evolving. In this blog post, I want to share the top three requirements for data flows in 2021 that we hear from our customers.
GDS will likely be looking at its cloud-first policy and specifically, it’s preference for public cloud, in order to understand if it can enable the Government to successfully mitigate complex dataprocessing legislation and uncertain future playing fields. . appeared first on Cloudera Blog.
In today’s fast-paced digital landscape, businesses face the daunting challenge of extracting valuable insights from large amounts of data. The ETL (Extract, Transform, Load) pipeline is the backbone of dataprocessing and analysis.
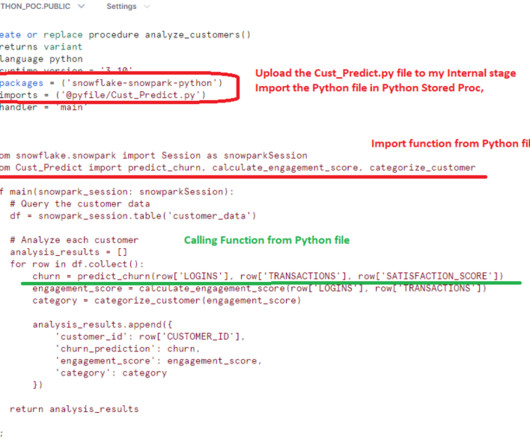
This capability enables advanced analytics, custom dataprocessing, and seamless integration of Python libraries. In this blog post, we’ll explore how to create and utilize a.Py One particularly powerful feature is the ability to import and use Python files (.py) file inside a Snowflake Python stored procedure.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content